序列类型
1. 列表 List
列表用中括号表示,类似于Java中的数组,索引从0开始取值的
num = ["a",1,2,2,1,3,4,56,7,8]
In [52]: a = [1,2,3,'aaaa','bbab']
In [53]: a[0]
Out[53]: 1
In [54]: a[4]
Out[54]: 'bbab'
In [21]: #list 列表用[] 表示
In [22]: num = ['aa',1,1,1,2,3,4,5,6,7,8]
In [23]: #count 查找元素出现多少次,下面的语句表示"1"这个元素出现的
...: 次数
In [24]: print(num.count(1))
3
In [25]: #index 查询元素的下标,如果列表里面有重复的元素,只能显示
...: 出第一个索引
In [34]: num
Out[34]: ['a', 1, 1, 1, 2, 3, 4, 5, 6, 7, 8]
In [35]: num.index('a')
Out[35]: 0
1.1 列表的增加
1.1.1 append 从末尾增加元素
num.append(9) #表示在num列表的尾部增加 9 这个元素;如果想增加字符,num.append('s')
print(num)
['a', 1, 2, 2, 1, 3, 4, 56, 7, 8, 9]
num.append('s')
print(num)
['a', 1, 2, 2, 1, 3, 4, 56, 7, 8, 9, 's']
1.1.2 insert 指定位置添加元素,num.insert(2,’q’) #表示索引为2的位置添加一个元素’q’
num.insert(2,'q')
print(num)
['a', 1, 'q', 2, 2, 1, 3, 4, 56, 7, 8, 9, 's']
1.1.3 列表合并拼接,extend
num.extend(name) #把后面的list的元素加到前面的list里面,
num
[8, 7, 6, 5, 4, 3, 2, 1, 'a', 'b', 'c', 'd']
info = num + name #合并两个list,把2个列表元素合并在info里面
print(info)
[8, 7, 6, 5, 4, 3, 2, 1, 'a', 'b', 'c', 'd', 'a', 'b', 'c', 'd']
print(num.extend(name)) #注意:这样的表达式是错误的,因为extend方法中没有返回值,所以不能这样操作
None
1.2 列表的删除
1.2.1 删除元素,用del,这是python内置的函数,不是列表自带的函数
del num[2] #表示删除num列表中索引为2的元素
print(num)
[0, 1, 2, 2, 1, 3, 4, 56, 7, 8, 9, 's']
1.2.2 pop() 默认删除最后一个元素,pop(3),写入索引,就删除了指定的元素
num.pop()
's'
num.pop(3)
2
1.2.3 remove 删除指定的元素
num.remove(0)
num
[1, 2, 1, 3, 4, 56, 7, 8, 9]
1.2.4 clear 清空列表
num.clear()
print (num)
[]
num = ['a',1,2,3,4,5,6,1,7,8,1,1]
num
['a', 1, 2, 3, 4, 5, 6, 1, 7, 8, 1, 1]
1.3 列表的修改
# 把num[0] 修改为0
num[0] = 0
print(num)
[0, 1, 'q', 2, 2, 1, 3, 4, 56, 7, 8, 9, 's']
1.4 列表的查询
1.4.1 count 查找元素出现的次数,下面的语句表示”1”这个元素在num列表中出现的次数
print(num.count(1))
2
1.4.2 index 查询元素的下标,如果列表里面有重复的元素,只能显示出第一个索引
print(num.index('a')) #表示在num列表里面的a这个元素的索引是多少
0
#列表取值
print(num[2]) #表示num列表中的索引为2的值是多少
2
In [19]: b = ['a',1,2,3,4,5,'cc','hello',1,2,33]
In [20]: b.index('a')
Out[20]: 0
In [21]: b.index(2)
Out[21]: 2
#可以用help方法查看方法下面的使用的情况
In [27]: help(b.index)
Help on built-in function index:
index(...) method of builtins.list instance
L.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
#注意:index的使用方法,第一个是查询的值,然后可以加上查询的起始位置和结束位置,中括号表示是可以省略的;默认的起始位置从第一个元素开始
In [26]: b.index(1,2,9) #查询从第2个索引位置元素到第9个索引位置元素之间出现值为1的第一个索引位置
Out[26]: 8
# 从索引位置为1开始,查询值为2的索引位置
In [37]: b.index(2,1)
Out[37]: 2
# 从索引位置为3开始,查询值为2的索引位置
In [39]: b.index(2,3)
Out[39]: 9
1.5 reverse 翻转,用来对列表的顺序倒过来;num.reverse()
num.reverse()
num
[1, 1, 8, 7, 1, 6, 5, 4, 3, 2, 1, 'a']
1.6 列表排序,sort()默认是升序,加上reverse=True,直接变成降序排列
num = [1,3,2,8,4,5,7,6]
num.sort()
num
[1, 2, 3, 4, 5, 6, 7, 8]
num.sort(reverse=True)
num
[8, 7, 6, 5, 4, 3, 2, 1]
name = ['a','b','c','d']
# 注意:列表排序一定是同类型的之间排序,比如,数字类型之间,字符串类型之间排序
In [49]: a = [1,0.9,1.2,1.1]
In [50]: a.sort()
In [51]: a
Out[51]: [0.9, 1, 1.1, 1.2]
1.7 in 用来判断一个值在不在list中,不在的话,则打印not in if username in users
1.7.1 一维数组
num1 = [1,2,3,4,5]
1.7.2 三维数组
num2 = [1,2,3,4,5,["a","b","c",["d","e"]]]
In [2]: print (num2[-1]) #表示取num2 这个列表的最后一个元素
['a', 'b', 'c', ['d', 'e']]
#打印三维数组中的某个元素的索引print(num2[5].index("a")),这个表示在num2列表里面的第5个元素中的子列表中的 a 的索引值是多少,a 在第一个位置,索引值为0
In [3]: print (num2[5].index("a"))
0
1.8 列表的copy()方法
In [53]: b = ['a',1,2,3,4,5,'cc','hello',1,2]
In [54]: a = b
In [55]: a.append('python')
In [56]: a
Out[56]: ['a', 1, 2, 3, 4, 5, 'cc', 'hello', 1, 2, 'python']
In [57]: b
Out[57]: ['a', 1, 2, 3, 4, 5, 'cc', 'hello', 1, 2, 'python']
In [58]: id(a)==id(b)
Out[58]: True
# 注意:直接赋值操作,id不会出现变化,说明没有重新开辟一块内存空间,但是使用了copy()方法后,内存空间出现了变化,即出现了两个不同的列表
In [59]: c = b.copy()
In [60]: b.append('haha')
In [61]: b
Out[61]: ['a', 1, 2, 3, 4, 5, 'cc', 'hello', 1, 2, 'python', 'haha']
In [62]: c
Out[62]: ['a', 1, 2, 3, 4, 5, 'cc', 'hello', 1, 2, 'python']
In [63]: id(b) == id(c)
Out[63]: False
2. 字符串
2.1 字符串不可以增删改
# 字符串用单引号或者双引号表示
In [1]: a = '123abc'
# 查看字符串的所有方法
In [3]: print(dir(a))
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
2.2 字符串的方法
2.2.1 查询
In [4]: a = 'abcdcbad'
In [5]: a.count('a')
Out[5]: 2
In [6]: a.index("a")
Out[6]: 0
In [7]: a.index("e")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-7-b9d890eb46e3> in <module>()
----> 1 a.index("e")
ValueError: substring not found
In [8]: a.find("e") # 当没有找到元素的时候返回-1
Out[8]: -1
In [9]: a.find('d')
Out[9]: 3
注意:
find和index方法都是查询元素的索引位置的,但是针对没有找到得元素,find不会报错,而index会报错;而find()方法只是字符串出现的方法。
2.2.2 判断
In [12]: a = 'abcdcbad'
In [13]: b = '123'
In [14]: c = '123adb'
In [15]: a.isdigit() #判断字符串a是否为数字类型
Out[15]: False
In [16]: b.isdigit()
Out[16]: True
In [17]: c.isdigit()
Out[17]: False
In [18]: a.isalpha() #判断字符串a是否为字母类型
Out[18]: True
In [19]: b.isalpha()
Out[19]: False
In [20]: c.isalpha()
Out[20]: False
In [21]: a.endswith('d') #判断字符串a是否以字母d结束
Out[21]: True
In [22]: b.endswith('2')
Out[22]: False
In [23]: a.startswith('b') #判断字符串a是否以字母b开始
Out[23]: False
In [24]: a.startswith('a')
Out[24]: True
In [25]: a.islower() #判断字符串a是否是全部是小写字母
Out[25]: True
In [26]: a.isupper()
Out[26]: False
In [27]: b = 'AND'
In [28]: b.isupper() #判断字符串b是否全部是大写字母
Out[28]: True
In [29]: c = 'asjHnA'
In [31]: c.isupper()
Out[31]: False
2.2.3 修改
In [1]: a = 'aendwe'
In [2]: print(a.upper()) #把字符串中的小写字母变成大写字母
AENDWE
In [3]: a.lower() #把字符串中的大写字母变成小写字母
Out[3]: 'aendwe'
In [11]: b = 'asdDND'
In [12]: b.upper()
Out[12]: 'ASDDND'
In [13]: b.lower()
Out[13]: 'asddnd'
In [14]: b = ' abd '
In [15]: b.strip() #去掉字符串两边的空格
Out[15]: 'abd'
In [20]: b.lstrip() #去掉左边的空格
Out[20]: 'abd '
In [21]: b.rstrip() #去掉右边的空格
Out[21]: ' abd'
In [22]: a = 'hello world'
In [23]: a.capitalize() #字符串的首字母大写
Out[23]: 'Hello world'
In [24]: a.title() #字符串单词的首字母大写
Out[24]: 'Hello World'
In [25]: a #字符串a是不会发生变化的
Out[25]: 'hello world'
In [26]: a = 'a b c d e f'
In [27]: a.split() #默认以空格来进行切割,切割后变成了一个列表
Out[27]: ['a', 'b', 'c', 'd', 'e', 'f']
In [28]: a.splitlines() #把一个字符串变成了一个字符串列表
Out[28]: ['a b c d e f']
In [31]: a = 'hahh heelo huuo'
In [32]: a.split('h') #以字母h进行切割,即去掉字母h
Out[32]: ['', 'a', '', ' ', 'eelo ', 'uuo']
In [33]: a.replace('h','ff') #替换,把字符串的中的h,全部替换为ff
Out[33]: 'ffaffff ffeelo ffuuo'
In [34]: a.replace('h','ff',2) #把字符串中的h,从左边开始替换,连续替换2次为ff
Out[34]: 'ffaffh heelo huuo'
2.2.4 删除
In [37]: a = 'a v s d e f '
In [38]: a.replace(' ','') #删除就是替换,即把空格全部删除
Out[38]: 'avsdef'
2.2.5 增加(字符串的4种拼接方法)
In [39]: a = 'adew'
In [40]: b = '123'
In [41]: a + b # 方法1:直接使用加号把字符串拼接在一起
Out[41]: 'adew123'
In [76]: '%s %s %s' %('hello','python','world')
Out[76]: 'hello python world'
In [79]: '%s%s' %(123,'abc') #方法2:格式化字符串
Out[79]: '123abc'
# 方法3:使用join,''.join([str1,str2,str3]),注意:列表里面必须是字符串
In [80]: ' '.join(['abc',123])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-80-dbc438cea3a1> in <module>()
----> 1 ' '.join(['abc',123])
TypeError: sequence item 1: expected str instance, int found
In [85]: ' '.join(['abc','345'])
Out[85]: 'abc 345'
In [86]: ''.join(['abc','345'])
Out[86]: 'abc345'
In [87]: '$#'.join(['abc','345'])
Out[87]: 'abc$#345'
In [88]: '$#HHH^&'.join(['abc','345'])
Out[88]: 'abc$#HHH^&345'
In [90]: '#%'.join(['123','abc','345'])
Out[90]: '123#%abc#%345'
In [91]: a = '###'
In [92]: a.join('123') # 这种表示方法和前面是一样的
Out[92]: '1###2###3'
#方法4:使用format
""" ’{} {} {}’.format(obj1,obj2,obj3)
’{0} {1} {2}’.format(obj1,obj2,obj3)
’{1} {0} {2}’.format(obj1,obj2,obj3)
'{n0} {n1} {n2}'.format(n1=obj1,n0=obj2,n2=obj3)
"""
In [93]: '{} {}'.format('hello','123')
Out[93]: 'hello 123'
In [94]: '{0},{1}'.format('hah',123)
Out[94]: 'hah,123'
In [95]: '{0},{1}'.format('hah',[1,2,3])
Out[95]: 'hah,[1, 2, 3]'
In [96]: '{}#{}${}'.format('hah',[1,2,3],(1,3,'a'))
Out[96]: "hah#[1, 2, 3]$(1, 3, 'a')"
In [47]: a = 'justdodt'
In [48]: b = '24'
In [49]: c = '重庆'
In [50]: print('我的名字是:{} 我今年{}岁了,我来自 {}'.format(a,b,a))
我的名字是:justdodt 我今年24岁了,我来自 justdodt
In [51]: print('我的名字是:{} 我今年{}岁了,我来自 {}'.format(a,b,c))
我的名字是:justdodt 我今年24岁了,我来自 重庆
In [53]: a = 'hello'
In [54]: b = 'python'
In [55]: c = '您好 !'
In [56]: '{} {} {}'.format(a,b,c) #fromat()中可以加上索引
Out[56]: 'hello python 您好 !'
In [57]: '{2} {0} {1}'.format(a,b,c)
Out[57]: '您好 ! hello python'
In [91]: '{0:x} {0:o} '.format(10) #fromat对应前面的
Out[91]: 'a 12 '
In [40]: '{0:x} {0:o} {0:0b} {0:d}'.format(10)
Out[40]: 'a 12 1010 10' #x为十六进制,o为八进制,0b为二进制,d为十进制
#注意:前面必须加上0,因为槽的数量必须要一致
In [93]: '{0:x} {0:o} {0:0b} '.format(10) + chr(65)
Out[93]: 'a 12 1010 A'
In [101]: '{name} {age} {gender}'.format(name='张三',age='20',gender='female')
Out[101]: '张三 20 female'
In [106]: "姓名:'{name} 年龄:{age} 性别:{gender}'".format(name='张三',age='20',gender='男')
Out[106]: "姓名:'张三 年龄:20 性别:男'"
In [108]: "姓名:'{name} 年龄:{age} 性{gender}'".format(age='20',gender='男',name='张三')
Out[108]: "姓名:'张三 年龄:20 性别:男'"
In [109]: '{:.2f}'.format(12.34234)
Out[109]: '12.34'
In [110]: '{a:.2f}'.format(a=12.32354)
Out[110]: '12.32'
In [109]: '{:.2f}'.format(12.34234) #.2f表示有2位小数
Out[109]: '12.34'
In [110]: '{a:.2f}'.format(a=12.32354)
Out[110]: '12.32'
In [111]: '{:.3%}'.format(.08934) #.3% 表示是有3位小数,但是需要转化为百分数
Out[111]: '8.934%'
In [112]: a = 13.3545
In [113]: '{:.3%}'.format(a)
Out[113]: '1335.450%'
In [115]: '{:0<10}'.format(12.4) #表示10个字符,< 为向左对齐,不足的补0
Out[115]: '12.4000000'
In [116]: '{:x<10}'.format(12.4) #表示10个字符,< 为向左对齐,不足的补x
Out[116]: '12.4xxxxxx'
In [117]: '{:%<10}'.format(12.4) #表示10个字符,< 为向左对齐,不足的补%
Out[117]: '12.4%%%%%%'
In [118]: '{:%>10}'.format(12.4) #表示10个字符,> 为向右对齐,不足的补%
Out[118]: '%%%%%%12.4'
In [119]: '{:%^10}'.format(12.4) #表示10个字符,^ 为居中对齐,不足的补%
Out[119]: '%%%12.4%%%'
2.2.6 format的浅析
In [35]: a = ['hello','python','!']
In [36]: print('{0[0]} {0[1]} {0[2]}'.format(a))
hello python !
In [37]: """
...: 上面的数字0是列表的固定格式,只能写成0
...: """
Out[37]: '\n上面的数字0是列表的固定格式,只能写成0\n'
In [38]: print('{a[0]:} {a[1]:} {a[2]}'.format(a=a))
hello python !
In [39]: #如果要写成a的形式需要加上a=a,但是需要注意空格
In [40]: '{0:x} {0:o} {0:0b} {0:d}'.format(10)
Out[40]: 'a 12 1010 10'
In [41]: ##x为十六进制,o为八进制,0b为二进制,d为十进制
In [42]: #如果前面的{}不见上0的话,会报元组索引越界
In [43]: '{:x} {:o} {:0b} {:d}'.format(10)
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-43-f266c76fd121> in <module>()
----> 1 '{:x} {:o} {:0b} {:d}'.format(10)
IndexError: tuple index out of range
In [44]: #原因:因为右边的format中是一个数字10,左边的{}中有两个字符,一个空字符,一个匹配的字符;两边数量不一致,所以
...: 会报元组越界;是传入的数字,所以会格式化为元组
In [45]: '{name} {age} {gender}'.format(name='张三',age='20',gender='female')
Out[45]: '张三 20 female'
In [46]: "姓名:'{name} 年龄:{age} 性{gender}'".format(age='20',gender='男',name='张三')
Out[46]: "姓名:'张三 年龄:20 性男'"
2.3 字符串的转义
In [42]: a = 'abc\nhae' # \n 换行符
In [43]: print(a)
abc
hae
In [46]: a = '123\tabc' # \t 表示水平制表符,就是键盘的Tab按键
In [47]: print(a)
123 abc
In [48]: b = 'agd\b123' # \b 表示退格
In [49]: print(b)
ag123
In [50]: c = '123\rabc' # \r 回车,当前位置移到本行开头
In [51]: print(c)
abc
In [52]: d = '123\\abc' # \\ 表示反斜杠\
In [53]: print(d)
123\abc
In [54]: a = '12enj\'abc' # \' 代表一个单引号,同样的",? 等符号也可以这样输出
In [55]: print(a)
12enj'abc
In [56]: b = 'asc\0123' # \0 表示一个空字符
In [57]: print(b)
asc
3
In [58]: c = 'as\a' # \a 系统提示音
In [59]: print(c)
as
In [62]: d = r'abc\tabc' # 去掉字符串的转义,只需要在字符串前面加上r就行
In [63]: print(d)
abc\tabc
2.4 字符串格式化
In [2]: '%d' %123 #%d,输出数字
Out[2]: '123'
In [34]: '%i'%0b10
Out[34]: '2'
In [31]: '%i'%0x10 #%i,表示可以自动把八进制和十六进制转换为十进制,%d不会转换
Out[31]: '16'
In [4]: '%s' %'hello' #%s,输出字符串,采用的是str()的显示
Out[4]: 'hello'
In [8]: '%.3f' %2.34203 #%.3f,输出浮点数,保留3位小数
Out[8]: '2.342'
In [9]: '%.4f' %2.34203 #%.4f,输出浮点数,保留4位小数
Out[9]: '2.3420'
#优先看小数点后的数字,为3,即保留3位小数,然后看小数点前的数字,为5,即表示总共输出5位数
In [35]: '%5.3f'%3.24235345
Out[35]: '3.242'
#优先看小数点后的数字,为3,即保留3位小数,然后看小数点前的数字,为7,即表示总共输出7位数(包含小数点),不足的用空格表示;3.242为5个数字(加上小数点),所以向前用2个空格填充
In [36]: '%7.3f'%3.24235345
Out[36]: ' 3.242'
In [37]: '%4.3f'%3.24235345 #优先看小数点后的数字,
Out[37]: '3.242'
In [38]: '%6.3f'%3.24235345
Out[38]: ' 3.242'
#优先看小数点后的数字,为3,即保留3位小数,然后看小数点前的数字,为07,即表示总共输出7位数(包含小数点),不足的用0表示;3.242为5个数字(加上小数点),所以向前用2个0填充
In [39]: '%07.3f'%3.24235345
Out[39]: '003.242'
#-表示向左对齐
In [40]: '%-7.3f'%3.24235345
Out[40]: '3.242 '
In [41]: '%+7.3f'%3.24235345 #+ 表示向右对齐
Out[41]: ' +3.242'
In [11]: '%c'%65 #%c,把整数变成ASCII
Out[11]: 'A'
In [12]: '%o'%8 #%o,八进制
Out[12]: '10'
In [13]: '%x'%16 #%x ,十六进制
Out[13]: '10'
In [14]: '%e'%10.4 #%e,科学计数法
Out[14]: '1.040000e+01'
In [26]: type('%r'%123)
Out[26]: str
#%r,也是表示输出字符串,他采用的repr()的显示,他会将后面给的参数原样打印出来,带有类型信息
3. 元组 Tuple
# 元组用小括号表示,注意:元组和字符串都是属于不可变的类型
In [55]: b = (1,2,3,'aaa','bbb')
In [56]: b
Out[56]: (1, 2, 3, 'aaa', 'bbb')
In [16]: a = ()
In [17]: type(a)
Out[17]: tuple
In [18]: #元组只包含一个元素时,需要在元素的后面加上逗号
In [19]: b = 12,
In [21]: type(b)
Out[21]: tuple
In [22]: b
Out[22]: (12,)
In [23]: c = '12','我们'
In [24]: type(c)
Out[24]: tuple
In [25]: #元组的定义也可以不加上括号
3.1 注意:
元组是不可变的,只有index和count方法,直接把元组变成列表就有其他的方法了。
In [68]: a = (1,2,3,'a')
In [69]: print(dir(a))
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'count', 'index']
In [70]: b = list(a)
In [71]: type(b)
Out[71]: list
4. 序列之间的相互转换
4.1 字符串转为列表
In [57]: d = "aaaa"
In [58]: e = list(d)
In [59]: e
Out[59]: ['a', 'a', 'a', 'a']
4.2 列表转换为字符串
In [2]: c = 'aaaa'
In [3]: d = list(c)
In [4]: e = str(d)
In [5]: e
Out[5]: "['a', 'a', 'a', 'a']"
In [6]: d
Out[6]: ['a', 'a', 'a', 'a']
4.3 字符串转为元组
In [7]: f = tuple(e)
In [8]: f
Out[8]:
('[',
"'",
'a',
"'",
',',
' ',
"'",
'a',
"'",
',',
' ',
"'",
'a',
"'",
',',
' ',
"'",
'a',
"'",
']')
注意:
字符串,元组,列表都是可以索引取值的,都是从0开始取值的
In [9]: a = 'dfghjk'
In [10]: a[0]
Out[10]: 'd'
In [11]: a[3]
Out[11]: 'h'
In [12]: a[7]
-------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-12-9cf13ba20553> in <module>()
----> 1 a[7]
IndexError: string index out of range
5. 切片
取一部分叫做切片,切片的原则是左闭右开,即取头部不取尾部;切片的步长默认为1,不可以为0
In [13]: a = [1,2,3,'bb','cc','dd']
In [14]: a[1:3]
Out[14]: [2, 3]
In [15]: a[1:4]
Out[15]: [2, 3, 'bb']
In [16]: a
Out[16]: [1, 2, 3, 'bb', 'cc', 'dd']
In [17]: a[2:]
Out[17]: [3, 'bb', 'cc', 'dd']
5.1 切片中的步长
比如a[1:4:2] 中的2就是表示步长为2,表示就是从第1个元素取到第3个元素,但是是每2个元素取一个。如果步长为1就是表示的连续取值。
In [19]: a = [1,2,3,'aa','bb','cc']
In [20]: a[1:4:2]
Out[20]: [2, 'aa']
In [5]: print (a[:3])
[1, 2, 3]
In [6]: print(a[::2])
[1, 3, 'bb']
In [7]: print (a[::-1])
['cc', 'bb', 'aa', 3, 2, 1]
In [8]: print (a[1:5:-1])
[]
In [1]: a = [1,2,3,4,5,6]
In [2]: a[1:4:-2]
Out[2]: [] #首先看步长,步长为-2,表示逆序取值,然后起始索引位置为1,结束索引位置为4,则是顺序取值的,所以无法取到值
In [3]: a[4:1:-2]
Out[3]: [5, 3]#步长为-2,表示逆序取值,起始位置索引是4,结束位置索引是1,但是无法取到索引为1的值
In [4]: a[-1::-1]
Out[4]: [6, 5, 4, 3, 2, 1]
#步长为-1,逆序取值;起始索引位置为-1,即倒数第一个值,结束为空,则表示取完所有的
In [5]: a[-1:0:-1]
Out[5]: [6, 5, 4, 3, 2]
#步长为-1,逆序取值;起始索引位置为-1,则为倒数第一个;结束的索引位置为0,但是无法取到索引位置为0的元素;即无法取到1
In [12]: a[-3:0:-2]
Out[12]: [4, 2]
#步长为-2,逆序间隔取值;其实位置索引为-3,结束位置索引为0,即从倒数第三个取到顺数第一个值;
In [13]: a[-5:-3:-1]
Out[13]: []
#步长为-1,逆序取值;起始位置索引为-5,结束位置索引为-3,即从倒数第5个元素取到倒数第2个元素,这样就变成了顺序取值了,矛盾了,故无法取到值
In [15]: a[-1:-5:-1]
Out[15]: [6, 5, 4, 3]
#步长为-1,即逆序取值;起始位置索引为-1,结束位置索引为-4,即从倒数第一个取到倒数第4个
In [16]: a[-1:-5:-2]
Out[16]: [6, 4]
#步长为-2,即逆序间隔取值;起始位置索引为-1,结束位置索引为-4,即间隔从倒数第1个取到倒数第4个
5.2 总结:切片取值
[1:] 从当前索引位置取到最后
[1:3] 取索引值为1到3的元素
[1:3:2] 最后一个元素叫做步长
[:3] 从头开始取,取到第二个元素
[::2] 表示以步长为2取出列表中的值
[::-1] 步长为负数,从后面往前面取值,相当于翻转
[1:5:-1] 步长为负数,逆序取值,然而起始位置索引是1,结束位置索引是5,表示顺序取值,与逆序取值相矛盾,即取出来为空
切片的操作适用于字符串和元组,但是字符串和元组是不可变的,列表是可变的。
6. 赋值
重新赋值,内存地址发生了变化。例如:
In [1]: b = (1,2,3,4)
In [2]: id(b)
Out[2]: 140236764820168
In [3]: b = ('a','b',1,2,4)
In [4]: id(b)
Out[4]: 140236739139896
In [5]: a = [1,2,3]
In [6]: id(a)
Out[6]: 140236764654088
In [7]: a = [1,3,'r']
In [8]: id(a)
Out[8]: 140236764729480
7. 拆包
In [9]: c = (1,2,3,4,5)
In [10]: d,*e,f=c
In [11]: d
Out[11]: 1
In [12]: e
Out[12]: [2, 3, 4]
In [13]: f
Out[13]: 5
In [14]: *d,e,f=c
In [15]: d
Out[15]: [1, 2, 3]
In [16]: e
Out[16]: 4
In [17]: *b,a=c
In [18]: b
Out[18]: [1, 2, 3, 4]
In [19]: a
Out[19]: 5
8. 查看元素类型和对应类型下的方法
8.1 查看元素类型,用type()
In [41]: type(b)
Out[41]: list
In [42]: a = (1,2,3)
In [43]: type(a)
Out[43]: tuple
In [44]: c = 'hahhw'
In [45]: type (c)
Out[45]: str
8.2 查看元素对应类型下的方法,用dir()
In [46]: dir(b) #列表对应的所有方法
Out[46]:
['__add__',
'__class__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__gt__',
'__hash__',
'__iadd__',
'__imul__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__len__',
'__lt__',
'__mul__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__reversed__',
'__rmul__',
'__setattr__',
'__setitem__',
'__sizeof__',
'__str__',
'__subclasshook__',
'append',
'clear',
'copy',
'count',
'extend',
'index',
'insert',
'pop',
'remove',
'reverse',
'sort']
9. 深浅复制
9.1 浅复制
In [1]: li = [1,2,3]
In [2]: l2 = ['a',li]
In [3]: l2
Out[3]: ['a', [1, 2, 3]]
In [4]: l2[0]
Out[4]: 'a'
In [5]: l2[1]
Out[5]: [1, 2, 3]
In [6]: l2[1][0]
Out[6]: 1
In [7]: li
Out[7]: [1, 2, 3]
In [8]: l2
Out[8]: ['a', [1, 2, 3]]
In [9]: li[0] = 'b'
In [10]: l2
Out[10]: ['a', ['b', 2, 3]]
In [11]: l3 = l2.copy()
In [12]: id(l2)
Out[12]: 140498762428104
In [13]: id(l3)
Out[13]: 140498804155208
In [14]: l2
Out[14]: ['a', ['b', 2, 3]]
In [15]: l3
Out[15]: ['a', ['b', 2, 3]]
In [16]: l2[0] = 'c'
In [17]: l2
Out[17]: ['c', ['b', 2, 3]]
In [18]: l3
Out[18]: ['a', ['b', 2, 3]]
In [19]: li
Out[19]: ['b', 2, 3]
In [20]: li[1] = 'd'
In [21]: li
Out[21]: ['b', 'd', 3] #浅复制是指改变外层的,但是里层的元素也跟着发生变化;因为id没有发生变化
In [22]: l2
Out[22]: ['c', ['b', 'd', 3]]
In [23]: l3
Out[23]: ['a', ['b', 'd', 3]]
In [24]: id(l2[1])
Out[24]: 140498804631944
In [25]: id(l3[1])
Out[25]: 140498804631944
9.2 深复制
In [36]: l1 = [1,2,3]
In [37]: l2 = ['a',l1]
In [38]: l2
Out[38]: ['a', [1, 2, 3]]
In [39]: l1[1] = 'a'
In [42]: import copy #深复制,只改变外层的元素,不改变里层的元素;他们的Id发生了变化
In [43]: l3 = copy.deepcopy(l2) #深复制需要导入copy模块,然后调用copy模块下的deepcopy方法
In [44]: l2
Out[44]: ['a', [1, 'a', 3]]
In [45]: l3
Out[45]: ['a', [1, 'a', 3]]
In [46]: l1[0] = 'h'
In [47]: l2
Out[47]: ['a', ['h', 'a', 3]]
In [48]: l3
Out[48]: ['a', [1, 'a', 3]]
In [49]: id(l1)
Out[49]: 140498753462856
In [50]: id(l4[1])
Out[50]: 140498753883208
总结:深浅复制
深浅复制是用于列表的嵌套,即定义为:l1=[1,2,3],l2=[‘a’,l1];浅复制是直接用l3=l2.copy();深复制需要导入import copy包,调用deepcopy方法。即l4 = copy.deepcopy(l2)
10. Bytes和bytearray
10.1 Bytes
In [51]: a = bytes(3) #指定长度为3的零填充字节对象
In [52]: a
Out[52]: b'\x00\x00\x00'
In [53]: a[0]
Out[53]: 0
In [54]: a[2]
Out[54]: 0
In [55]: a[1]
Out[55]: 0
In [56]: bytes(b'abc')
Out[56]: b'abc'
In [57]: c = bytes(b'bcd') #二进制字符串对象
In [58]: c[0] #b对应的ASCII为98
Out[58]: 98
In [59]: c[1]
Out[59]: 99
In [60]: c[2]
Out[60]: 100
10.2 bytearray
In [62]: bytearray(b'abc') #字节数组,在python中基本上用不到
Out[62]: bytearray(b'abc')
11. 字符串的编码
In [64]: a = '中国'.encode('utf8') #编码有2种常用的方式,utf8和jbk
In [65]: a
Out[65]: b'\xe4\xb8\xad\xe5\x9b\xbd'
In [66]: a.decode('utf8')
Out[66]: '中国'
In [67]: b = '计算机'.encode('gbk') #解码一定要按照编码对应的格式解码
In [68]: b
Out[68]: b'\xbc\xc6\xcb\xe3\xbb\xfa'
11.1 字符串编码的作用
pyhton统一了编码,这样python在内部处理的时候不会因为编码不同而出现程序不能正常执行的问题。
python会自动根据系统环境选择编码,但是经常在文件传输的过程中,会遇到各种不同的编码,这个时候就需要我们处理编码问题。
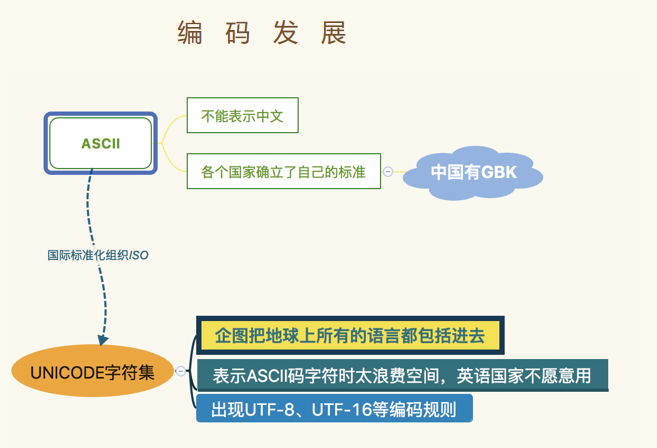
11.2 编码的发展
ASCII(ASCII不能表示中文,各个国家确立了自己的标准,中国有GBK)—>国际标准化组织ISO—>UNICODE字符集—>企图把地球上所有的语言都包括进去,由于表示ASCII码字符时太浪费时间,英语国家不愿意—>出现UTF-8、UTF-16等编码规则
11.3 python对字符集的处理
Python内核(在内存中)<—>用Unicode(转成其他的编码)外部:终端、.py文件、不同的地方与系统有关系,编码有GBK、UTF-8等等
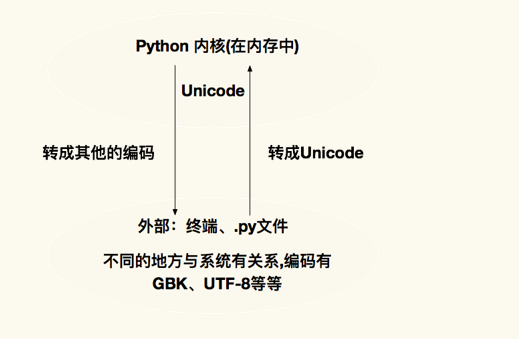
注意: 编码用encode,常见的是utf8和jbk,解码用decode;解码必须要和编码的的格式一样,如果不一样就会出现乱码。
12. Python的交互式环境
12.1 怎么退出Python的虚拟环境
输入命令 deactivate
12.2 安装ipython3
sudo apt install ipython3
直接输入ipthon3在里面操作