分区表
/user/hive/warehouse/emp/d=20180808/.....
/user/hive/warehouse/emp/d=20180809/.....
select .... from table where d='20180808'
大数据的瓶颈:IO,disk,network
创建分区表
create table order_partition(
order_no string,
event_time string
)
PARTITIONED BY(event_month string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
加载数据
load data local inpath '/home/hadoop/data/order.txt' overwrite into table order_partition
PARTITION (event_month='2014-05');
再创建一个分区
hdfs dfs -mkdir /user/hive/warehouse/d6_hive.db/order_partition/event_month=2014-06
把Linux本地的数据上传到HDFS新建的目录下
hdfs dfs -put /home/hadoop/data/order.txt /user/hive/warehouse/d6_hive.db/order_partition/event_month=2014-06
然而在hive中没有出现分区6 的数据,在mysql中的partiion中也没有出现;需要对分区表做如下的修改才行的
mysql> select * from partitions ;
+---------+-------------+------------------+---------------------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+---------------------+-------+--------+
| 6 | 1553373298 | 0 | event_month=2014-05 | 47 | 46 |
+---------+-------------+------------------+---------------------+-------+--------+
1 row in set (0.00 sec)
在hive中,修改分区表
ALTER TABLE order_partition ADD IF NOT EXISTS PARTITION (event_month='2014-06') ;
在MySQL中查看元数据信息
mysql> select * from partitions ;
+---------+-------------+------------------+---------------------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+---------------------+-------+--------+
| 6 | 1553373298 | 0 | event_month=2014-05 | 47 | 46 |
| 7 | 1553373768 | 0 | event_month=2014-06 | 48 | 46 |
+---------+-------------+------------------+---------------------+-------+--------+
2 rows in set (0.00 sec)
在hive中查询分区信息
hive (d6_hive)> show partitions order_partition;
OK
event_month=2014-05
event_month=2014-06
Time taken: 0.06 seconds, Fetched: 2 row(s)
hive (d6_hive)>
创建多级分区表
create table order_mulit_partition(
order_no string,
event_time string
)
PARTITIONED BY(event_month string, step string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
load data local inpath '/home/hadoop/data/order.txt' overwrite into table order_mulit_partition
PARTITION (event_month='2014-05', step='1');
在Hive中查询结果
hive (d6_hive)> select * from order_mulit_partition where event_month='2014-05' and step='1';
OK
10703007267488 2014-05-10 06:01:12.334+01 2014-05 1
10101043509689 2014-05-10 07:36:23.342+01 2014-05 1
10101043529689 2014-05-10 07:45:23.32+01 2014-05 1
10101043549689 2014-05-10 07:51:23.32+01 2014-05 1
10101043539689 2014-05-10 07:57:23.342+01 2014-05 1
NULL 2014-05 1
Time taken: 0.223 seconds, Fetched: 6 row(s)
hive (d6_hive)>
按照部门编号写到指定的分区中去
静态分区
CREATE TABLE `emp_static_partition`(
`empno` int,
`ename` string,
`job` string,
`mgr` int,
`hiredate` string,
`sal` double,
`comm` double)
partitioned by(deptno int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
insert into table emp_static_partition PARTITION (deptno=10)
select empno,ename,job,mgr,hiredate,sal,comm from emp
where deptno=10;
select * from emp_static_partition where deptno=10; --会执行MapReduce程序
动态分区
CREATE TABLE `emp_dynamic_partition`(
`empno` int,
`ename` string,
`job` string,
`mgr` int,
`hiredate` string,
`sal` double,
`comm` double)
partitioned by(deptno int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
hive (d6_hive)> insert into table emp_dynamic_partition partition (deptno)
> select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp;
FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
注意:这是为严格模式,需要修改模式
hive (d6_hive)>
hive (d6_hive)>set hive.exec.dynamic.partition.mode=nonstrict;
hive (d6_hive)>insert into table emp_dynamic_partition PARTITION (deptno) select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp;
静态分区和动态分区对比
静态分区,不够智能,需要认为指定分区号;动态分区更加简单,不需要认为的去指定分区号,只需要指定分区的字段就行。
hiveserver2+beeline配合使用操作Hive
Server + Client
thriftserver+beeline
操作语句:
beeline -u jdbc:hive2://hadoop000:10000/d6_hive -n hadoop
复杂数据类型:
复杂的数据类型,需要考虑如何存,如何取的问题,特别是如何取数据的问题。
array类型
create table hive_array(
name string,
work_locations array<string>
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ',';
load data local inpath '/home/hadoop/data/hive_array.txt'
overwrite into table hive_array;
查询出work_locations中的数组其中的元素
hive (d6_hive)> select name,work_locations[0] from hive_array;
OK
justdodt beijjing
hahh chengdu
查询work_locations 的个数
hive (d6_hive)> select size(work_locations) from hive_array;
OK
4
4
查询在深圳上班的人
hive (d6_hive)> select * from hive_array where array_contains(work_locations,'shenzhen');
OK
justdodt ["beijjing","shanghai","guangzhou","shenzhen"]
map 类型
map : key-value
father:xiaoming#mother:xiaohuang#brother:xiaoxu
创建表
create table hive_map(
id int,
name string,
members map<string,string>,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ':';
load data local inpath '/home/hadoop/data/hive_map.txt'
overwrite into table hive_map;
查询家庭成员的母亲
hive (d6_hive)> select id,name,age,members['mother'] from hive_map;
OK
1 zhangsan 28 xiaohuang
2 lisi 22 huangyi
3 wangwu 29 ruhua
4 mayun 26 angelababy
求出家庭成员的亲属关系
hive (d6_hive)> select map_keys(members) from hive_map;
OK
["father","mother","brother"]
["father","mother","brother"]
["father","mother","sister"]
["father","mother"]
取值
hive (d6_hive)> select map_values(members) from hive_map;
OK
["xiaoming","xiaohuang","xiaoxu"]
["mayun","huangyi","guanyu"]
["wangjianlin","ruhua","jingtian"]
["mayongzhen","angelababy"]
求出亲属关系的个数
hive (d6_hive)> select size(members) from hive_map;
OK
3
3
3
2
结构体类型
struct struct(‘a’,1,2,3,4)
创建表,存储结构体
create table hive_struct(
ip string,
userinfo struct<name:string,age:int>
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '#'
COLLECTION ITEMS TERMINATED BY ':';
load data local inpath '/home/hadoop/data/hive_struct.txt'
overwrite into table hive_struct;
查询结构体后面的用户的姓名和年龄
hive (d6_hive)> select userinfo.name,userinfo.age from hive_struct;
OK
zhangsan 40
lisi 50
wangwu 60
zhaoliu 70
Hive元数据
在hive-site.xml配置中,把hive 的元数据存储在MySQL中
mysql> show tables;
+---------------------------+
| Tables_in_ruoze_d6 |
+---------------------------+
| bucketing_cols |
| cds |
| columns_v2 |
| database_params |
| dbs |
| func_ru |
| funcs |
| global_privs |
| idxs |
| index_params |
| part_col_privs |
| part_col_stats |
| part_privs |
| partition_key_vals |
| partition_keys |
| partition_params |
| partitions |
| roles |
| sd_params |
| sds |
| sequence_table |
| serde_params |
| serdes |
| skewed_col_names |
| skewed_col_value_loc_map |
| skewed_string_list |
| skewed_string_list_values |
| skewed_values |
| sort_cols |
| tab_col_stats |
| table_params |
| tbl_col_privs |
| tbl_privs |
| tbls |
| version |
+---------------------------+
35 rows in set (0.00 sec)
注意:dbs,tbls,cds,sds,partitions,version
在MySQL中查看dbs,dbs是hive中的数据库的元数据信息
mysql> select * from dbs\G;
*************************** 1. row ***************************
DB_ID: 1
DESC: Default Hive database
DB_LOCATION_URI: hdfs://localhost:9000/user/hive/warehouse
NAME: default
OWNER_NAME: public
OWNER_TYPE: ROLE
*************************** 2. row ***************************
DB_ID: 6
DESC: NULL
DB_LOCATION_URI: hdfs://localhost:9000/user/hive/warehouse/hive.db
NAME: hive
OWNER_NAME: hadoop
OWNER_TYPE: USER
*************************** 3. row ***************************
DB_ID: 7
DESC: NULL
DB_LOCATION_URI: hdfs://localhost:9000/d6_hive/test
NAME: hive2
OWNER_NAME: hadoop
OWNER_TYPE: USER
*************************** 4. row ***************************
DB_ID: 11
DESC: NULL
DB_LOCATION_URI: hdfs://localhost:9000/user/hive/warehouse/testdb.db
NAME: testdb
OWNER_NAME: hadoop
OWNER_TYPE: USER
*************************** 5. row ***************************
DB_ID: 12
DESC: NULL
DB_LOCATION_URI: hdfs://localhost:9000/user/hive/warehouse/d6_hive.db
NAME: d6_hive
OWNER_NAME: hadoop
OWNER_TYPE: USER
*************************** 6. row ***************************
DB_ID: 16
DESC: NULL
DB_LOCATION_URI: hdfs://localhost:9000/user/hive/warehouse/g6_hadoop.db
NAME: g6_hadoop
OWNER_NAME: hadoop
OWNER_TYPE: USER
6 rows in set (0.00 sec)
ERROR:
No query specified
在mysql中查看sds
mysql> select * from sds\G;
*************************** 1. row ***************************
SD_ID: 8
CD_ID: 8
INPUT_FORMAT: org.apache.hadoop.mapred.TextInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/flow_info
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SERDE_ID: 8
*************************** 2. row ***************************
SD_ID: 11
CD_ID: 11
INPUT_FORMAT: org.apache.hadoop.mapred.TextInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/version_test
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SERDE_ID: 11
*************************** 3. row ***************************
SD_ID: 16
CD_ID: 16
INPUT_FORMAT: org.apache.hadoop.mapred.TextInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/test
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SERDE_ID: 16
*************************** 4. row ***************************
SD_ID: 17
CD_ID: 17
INPUT_FORMAT: org.apache.hadoop.mapred.TextInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/emp
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SERDE_ID: 17
*************************** 5. row ***************************
SD_ID: 18
CD_ID: 18
INPUT_FORMAT: org.apache.hadoop.mapred.TextInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/managed_emp
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SERDE_ID: 18
*************************** 6. row ***************************
SD_ID: 19
CD_ID: 19
INPUT_FORMAT: org.apache.hadoop.mapred.TextInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/d6_hive/external
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SERDE_ID: 19
*************************** 7. row ***************************
SD_ID: 20
CD_ID: 20
INPUT_FORMAT: org.apache.hadoop.mapred.TextInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/order_partition
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SERDE_ID: 20
*************************** 8. row ***************************
SD_ID: 21
CD_ID: 20
INPUT_FORMAT: org.apache.hadoop.mapred.TextInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/order_partition/event_month=2014-05
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SERDE_ID: 21
*************************** 9. row ***************************
SD_ID: 26
CD_ID: 21
INPUT_FORMAT: org.apache.hadoop.mapred.SequenceFileInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/page_views_seq
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
SERDE_ID: 26
*************************** 10. row ***************************
SD_ID: 28
CD_ID: 23
INPUT_FORMAT: org.apache.hadoop.mapred.TextInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/page_views
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
SERDE_ID: 28
*************************** 11. row ***************************
SD_ID: 29
CD_ID: 24
INPUT_FORMAT: org.apache.hadoop.hive.ql.io.RCFileInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/page_views_rcfile
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.RCFileOutputFormat
SERDE_ID: 29
*************************** 12. row ***************************
SD_ID: 30
CD_ID: 25
INPUT_FORMAT: org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat
IS_COMPRESSED:
IS_STOREDASSUBDIRECTORIES:
LOCATION: hdfs://hadoop001:8020/user/hive/warehouse/hive.db/page_views_parquet
NUM_BUCKETS: -1
OUTPUT_FORMAT: org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat
SERDE_ID: 30
12 rows in set (0.00 sec)
注意:sds表是存放的文件存储格式信息,hive默认的格式是Text,还有Sequence,Orc,Parquet
在MySQL中查看tbls
mysql> select * from tbls\G;
*************************** 1. row ***************************
TBL_ID: 1
CREATE_TIME: 1552944715
DB_ID: 1
LAST_ACCESS_TIME: 0
OWNER: hadoop
RETENTION: 0
SD_ID: 1
TBL_NAME: d6_wc
TBL_TYPE: MANAGED_TABLE
VIEW_EXPANDED_TEXT: NULL
VIEW_ORIGINAL_TEXT: NULL
*************************** 2. row ***************************
TBL_ID: 6
CREATE_TIME: 1552961328
DB_ID: 12
LAST_ACCESS_TIME: 0
OWNER: hadoop
RETENTION: 0
SD_ID: 6
TBL_NAME: emp
TBL_TYPE: MANAGED_TABLE
VIEW_EXPANDED_TEXT: NULL
VIEW_ORIGINAL_TEXT: NULL
在MySQL中查看分区信息
mysql> select * from partitions\G;
*************************** 1. row ***************************
PART_ID: 6
CREATE_TIME: 1553373298
LAST_ACCESS_TIME: 0
PART_NAME: event_month=2014-05
SD_ID: 47
TBL_ID: 46
*************************** 2. row ***************************
PART_ID: 7
CREATE_TIME: 1553373768
LAST_ACCESS_TIME: 0
PART_NAME: event_month=2014-06
SD_ID: 48
TBL_ID: 46
*************************** 3. row ***************************
PART_ID: 8
CREATE_TIME: 1553374636
LAST_ACCESS_TIME: 0
PART_NAME: event_month=2014-05/step=1
SD_ID: 50
TBL_ID: 47
*************************** 4. row ***************************
PART_ID: 11
CREATE_TIME: 1553381184
LAST_ACCESS_TIME: 0
PART_NAME: deptno=10
SD_ID: 52
TBL_ID: 51
*************************** 5. row ***************************
PART_ID: 12
CREATE_TIME: 1553381778
LAST_ACCESS_TIME: 0
PART_NAME: deptno=30
SD_ID: 55
TBL_ID: 53
*************************** 6. row ***************************
PART_ID: 13
CREATE_TIME: 1553381778
LAST_ACCESS_TIME: 0
PART_NAME: deptno=10
SD_ID: 56
TBL_ID: 53
*************************** 7. row ***************************
PART_ID: 14
CREATE_TIME: 1553381778
LAST_ACCESS_TIME: 0
PART_NAME: deptno=__HIVE_DEFAULT_PARTITION__
SD_ID: 57
TBL_ID: 53
*************************** 8. row ***************************
PART_ID: 15
CREATE_TIME: 1553381778
LAST_ACCESS_TIME: 0
PART_NAME: deptno=20
SD_ID: 58
TBL_ID: 53
*************************** 9. row ***************************
PART_ID: 16
CREATE_TIME: 1553523756
LAST_ACCESS_TIME: 0
PART_NAME: day=20190328
SD_ID: 76
TBL_ID: 66
9 rows in set (0.00 sec)
在MySQL中查看version表信息
mysql> select * from version;
+--------+----------------+-----------------------------------------+
| VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+--------+----------------+-----------------------------------------+
| 1 | 1.1.0 | Set by MetaStore hadoop@192.168.100.111 |
+--------+----------------+-----------------------------------------+
1 row in set (0.00 sec)
如果插入了一条数据或者删除这一条数据,会导致hive无法启动,更新这一条数据,hive还是会正常启动。 示例:
mysql> select * from version;
+--------+----------------+-----------------------------------------+
| VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+--------+----------------+-----------------------------------------+
| 1 | 1.1.0 | Set by MetaStore hadoop@192.168.100.111 |
| 2 | 1.1.0 | Set by MetaStore hadoop@192.168.100.111 |
+--------+----------------+-----------------------------------------+
2 rows in set (0.00 sec)
当启动Hive-Cli时候
会报错 Caused by: MetaException(message:Metastore contains multiple versions (2)
参考博客:
Hive 元数据表关系图
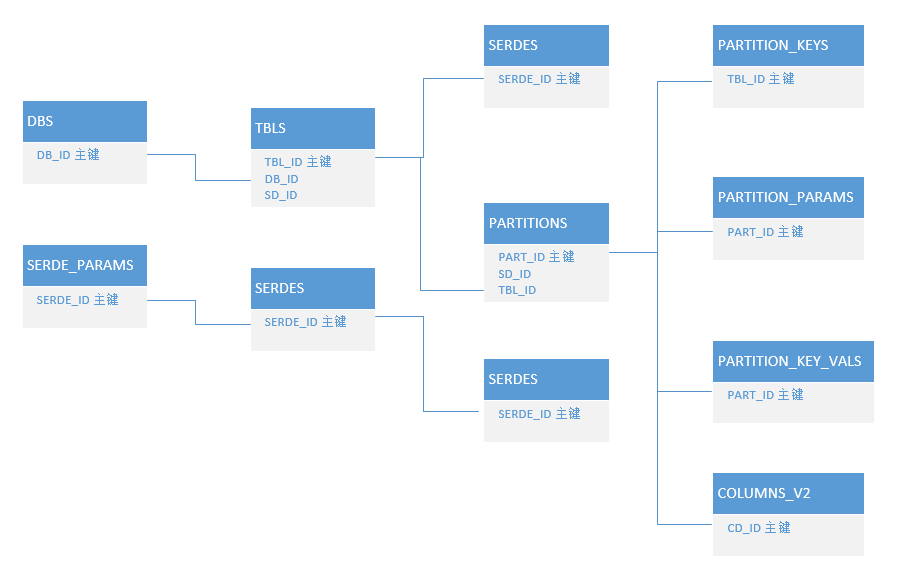
注意:Hive中的数据由2部分组成,存储在HDFS上的数据和MySQL中的元数据,二者缺一不可。
思考题
请把hiveserver2 启动在16666端口上,并使用beeline访问通
答案:在hive-sit.xml 文件增加
<property>
<name>hive.server2.thrift.port</name>
<value>16666</value>
</property>