概述
在进行map计算之前,map会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
问题
Hadoop 2.x默认的block大小是128MB,Hadoop 1.x默认的block大小是64MB,可以在hdfs-site.xml中设置dfs.block.size,注意单位是byte。
分片大小范围可以在mapred-site.xml中设置,mapred.min.split.size mapred.max.split.size,minSplitSize大小默认为1B,maxSplitSize大小默认为Long.MAX_VALUE = 9223372036854775807
那么分片到底是多大呢?
minSize=max{minSplitSize,mapred.min.split.size}
maxSize=mapred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
看一下源码: 源码地址
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
.
.
.
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
所以在我们没有设置分片的范围的时候,分片大小是由block块大小决定的,和它的大小一样。比如把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成三个block块,与之对应产生三个split,所以最终会产生三个map task。我又发现了另一个问题,第三个block块里存的文件大小只有2MB,而它的block块大小是128MB, 那它实际占用Linux file system的多大空间?
答案是实际的文件大小,而非一个块的大小
最后一个问题是: 如果hdfs占用Linux file system的磁盘空间按实际文件大小算,那么这个”块大小“有必要存在吗?
其实块大小还是必要的,一个显而易见的作用就是当文件通过append操作不断增长的过程中,可以通过来block size决定何时split文件。
源码解读
作业从JobClient端的submitJobInternal()方法提交作业的同时,调用InputFormat接口的getSplits()方法来创建split。默认是使用InputFormat的子类FileInputFormat来计算分片,而split的默认实现为FileSplit(其父接口为InputSplit)。这里要注意,split只是逻辑上的概念,并不对文件做实际的切分。一个split记录了一个Map Task要处理的文件区间,所以分片要记录其对应的文件偏移量以及长度等。每个split由一个Map Task来处理,所以有多少split,就有多少Map Task。下面着重分析这个方法:
public List<InputSplit> getSplits(JobContext job
) throws IOException {
//getFormatMinSplitSize():始终返回1
//getMinSplitSize(job):获取” mapred.min.split.size”的值,默认为1
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//getMaxSplitSize(job):获取"mapred.max.split.size"的值,
//默认配置文件中并没有这一项,所以其默认值为” Long.MAX_VALUE”,即2^63 – 1
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus>files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
FileSystem fs = path.getFileSystem(job.getConfiguration());
long length = file.getLen();
BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
if ((length != 0) && isSplitable(job, path)) {
long blockSize = file.getBlockSize();
//计算split大小
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
//计算split个数
long bytesRemaining = length; //bytesRemaining表示剩余字节数
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { //SPLIT_SLOP=1.1
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(new FileSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkLocations.length-1].getHosts()));
}
} else if (length != 0) {
splits.add(new FileSplit(path, 0, length, blkLocations[0].getHosts()));
} else {
//Create empty hosts array for zero length files
splits.add(new FileSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files in the job-conf
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
LOG.debug("Total # of splits: " + splits.size());
return splits;
}
首先计算分片的下限和上限:minSize和maxSize,具体的过程在注释中已经说清楚了。接下来用这两个值再加上blockSize来计算实际的split大小,过程也很简单,具体代码如下:
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
接下来就是计算实际的分片个数了。针对每个输入文件,计算input split的个数。while循环的含义如下:
a) 文件剩余字节数/splitSize>1.1,创建一个split,这个split的字节数=splitSize,文件剩余字节数=文件大小 - splitSize
b) 文件剩余字节数/splitSize<1.1,剩余的部分全都作为一个split(这主要是考虑到,不用为剩余的很少的字节数一些启动一个Map Task)
**我们发现,在默认配置下,split大小和block大小是相同的。这是为什么?
一个split如果对应的多个block,若这些block大多不在本地,则会降低Map Task的本地性,降低效率。
到这里split的划分就介绍完了,但是有两个问题需要考虑:
1、如果一个record跨越了两个block该怎么办?
这个可以看到,在Map Task读取block的时候,每次是读取一行的,如果发现块的开头不是上一个文件的结束,那么抛弃第一条record,因为这个record会被上一个block对应的Map Task来处理。那么,第二个问题来了:
2、上一个block对应的Map Task并没有最后一条完整的record,它又该怎么办?
一般来说,Map Task在读block的时候都会多读后续的几个block,以处理上面的这种情况。
参考博客 MapReduce中如何处理跨行的Block和InputSplit
通过上面的源码可以得出,加入一个块大小设置为128MB,如果输入的文件小于128*1.1=140.8MB; 那么就只有一个分片;如果输入的文件大于 140.8MB,小于128*2.1MB,就有2个分片。
测试
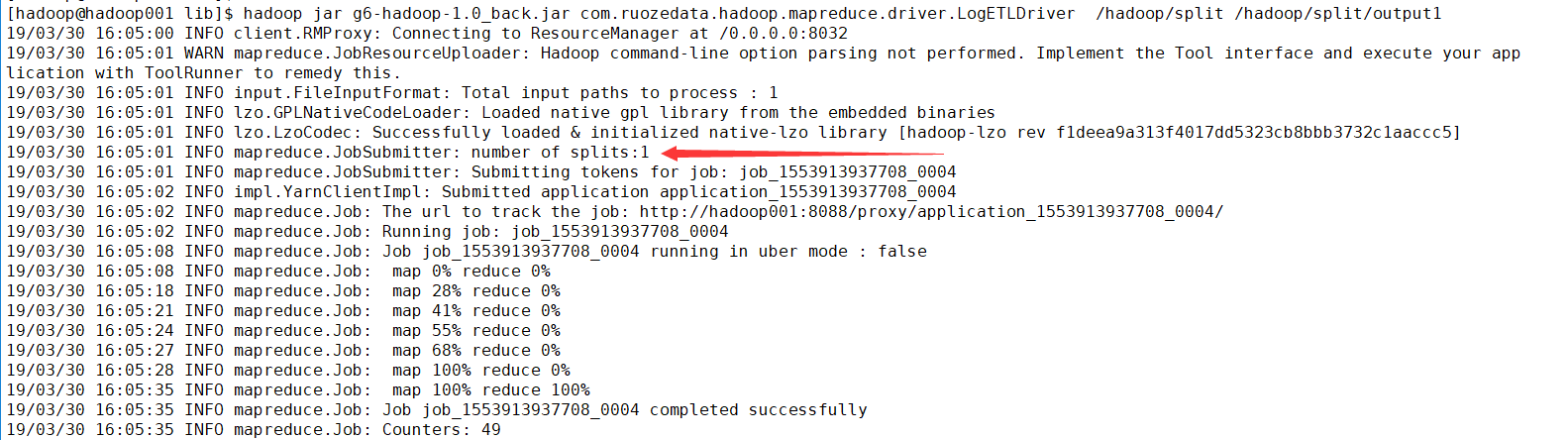
测试数据 data1.log 139MB < 128*1.1 =140.8MB
[hadoop@hadoop001 data]$ du -sh data1.log
139M data1.log
[hadoop@hadoop001 lib]$ hadoop jar g6-hadoop-1.0_back.jar com.ruozedata.hadoop.mapreduce.driver.LogETLDriver /hadoop/split /hadoop/split/output1
[hadoop@hadoop001 lib]$ hadoop jar g6-hadoop-1.0_back.jar com.ruozedata.hadoop.mapreduce.driver.LogETLDriver /hadoop/split /hadoop/split/output1
19/03/30 16:05:00 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
19/03/30 16:05:01 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
19/03/30 16:05:01 INFO input.FileInputFormat: Total input paths to process : 1
19/03/30 16:05:01 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
19/03/30 16:05:01 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev f1deea9a313f4017dd5323cb8bbb3732c1aaccc5]
19/03/30 16:05:01 INFO mapreduce.JobSubmitter: number of splits:1
注意:number of splits:1
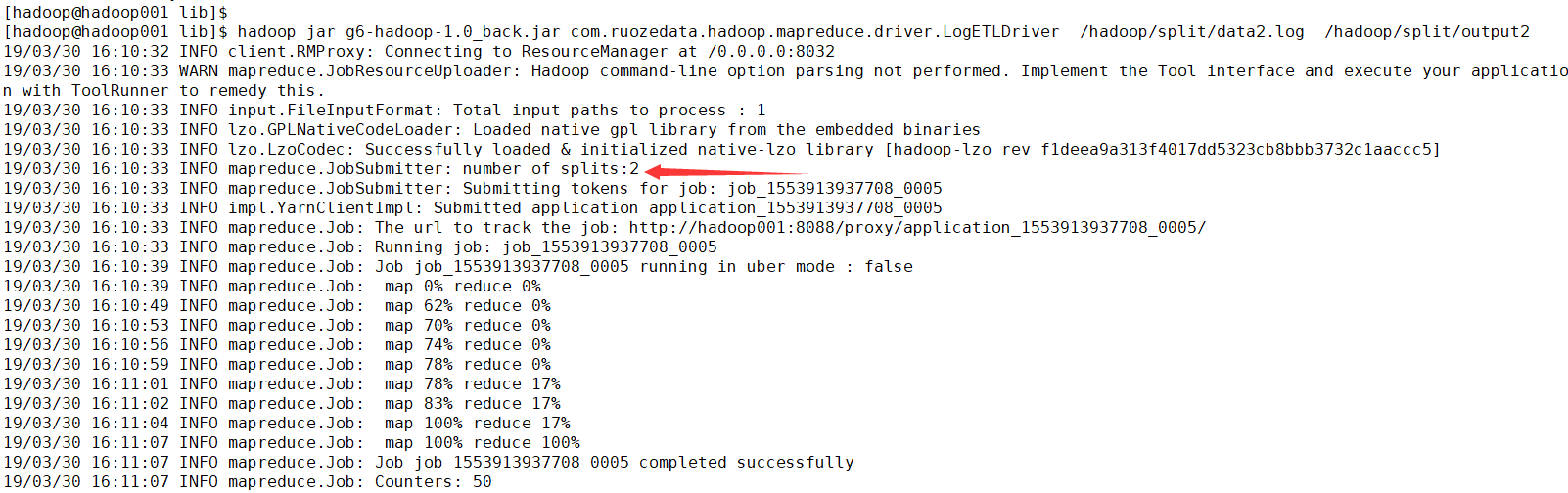
测试数据 data2.log 148M > 128 * 1.1 MB
[hadoop@hadoop001 data]$ du -sh data2.log
148M data2.log
[hadoop@hadoop001 data]$ hdfs dfs -put data2.log /hadoop/split
[hadoop@hadoop001 lib]$ hadoop jar g6-hadoop-1.0_back.jar com.ruozedata.hadoop.mapreduce.driver.LogETLDriver /hadoop/split/data2.log /hadoop/split/output2
19/03/30 16:10:32 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
19/03/30 16:10:33 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
19/03/30 16:10:33 INFO input.FileInputFormat: Total input paths to process : 1
19/03/30 16:10:33 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library from the embedded binaries
19/03/30 16:10:33 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev f1deea9a313f4017dd5323cb8bbb3732c1aaccc5]
19/03/30 16:10:33 INFO mapreduce.JobSubmitter: number of splits:2
总结:
Split 分片的计算跟 blockSize, minSize, maxSize 三个参数有关 假如 blockSize 设置128 M 文件大小 200M 那么splitSize 就是128M 200/128=1.56>1.1 创建2个split (通过源码可以看出最右一个文件的大小在 0- 128+12.8M之间)