介绍
本文档浅谈YARN的ResourceManager的High Availability。RM负责追踪集群的资源和调度应用作业(比如MapReduce作业)。在Hadoop2.4之前,ResourceManager是YARN集群的单点。 高可用特性就是用来解决单点问题的,通过加入一个Active/Standby的ResourceManager对来解决。
架构
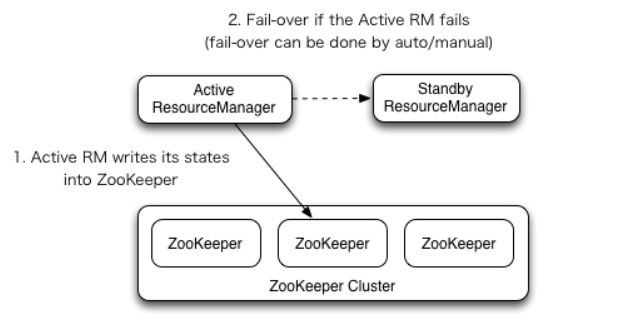
RM Failover
ResourceManager HA 通过一个主从架构实现在任意时刻,总有一个RM是active 的,而一个或者多个RM处于standby状态等待随时成为active。触发active的转换的条件是 通过admin命令行或者在automatic-failover启动的情况下集成的failover-controller触发。
手动转换failover
当自动failover没有启用时,管理员需要手动切换众多RM中的一个成为active。为了从一个RM到其他RM进行failover,做法通常是先将现在的Active的RM切为Standby, 然后再选择一个Standby切为Active。所有这些都可以通过”yarn rmadmin”的命令行完成。
自动failover
RM有一个选项可以嵌入使用Zookeeper的ActiveStandbyElector来决定哪个RM成为Active。当Active挂掉或者不响应时,另一个RM会自动被选举为Active然后接管集群。 注意,并不需要像HDFS一样运行一个隔离的ZKFC守护进程,因为对于嵌入到RM中的ActiveStandbyElector表现出来就是在做failure检查和leader选举,不用单独的ZKFC。
在RM failover时的Client, ApplicationMaster和 NodeManager
当有多个RM时,被client和node使用的配置文件yarn-site.xml需要列出所有的RM。Clients, ApplicationMasters (AMs) 和 NodeManagers (NMs) 会以一种round-robin轮询的方式来不断尝试连接RM直到其命中一个active的RM。 如果当前Active挂掉了,他们会恢复round-robin来继续寻找新的Active。默认的重试策略是 org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider类来实现的。 你可以通过继承实现org.apache.hadoop.yarn.client.RMFailoverProxyProvider来覆盖这个方法,并且设置对应的类名到这个属性yarn.client.failover-proxy-provider。
从之前的主RM状态恢复 伴随ResourceManager的重启机制开启,升级为主的RM会加载RM内部状态并且恢复原来RM留下的状态,而这依赖于RM的重启特性。而之前提交到RM的作业会发起一个新的尝试请求。 应用作业会周期性的checkpoint来避免任务丢失。状态存储对于所有的RM都必须可见。当前,有两种RMStateStore实现来支持持久化—— FileSystemRMStateStore 和 ZKRMStateStore。 其中 ZKRMStateStore隐式的允许在任意时刻写到一个单一的RM,因此是HA集群的推荐存储。当使用ZKRMStateStore时,不需要单独的隔离机制来解决分布式的脑裂问题(多个RM都成为Active)。
YARN HA 的配置
管理命令
yarn rmadmin有一组HA相关的命令选项来检查RM的健康状态,以及切换主备。HA用来切换的RM的id由 yarn.resourcemanager.ha.rm-ids属性设置。
$ yarn rmadmin -getServiceState rm1
active
$ yarn rmadmin -getServiceState rm2
standby
如果自动failover开启,就不需要手动的切换命令了。
$ yarn rmadmin -transitionToStandby rm1
Automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@1d8299fd
Refusing to manually manage HA state, since it may cause
a split-brain scenario or other incorrect state.
If you are very sure you know what you are doing, please
specify the forcemanual flag.
与NameNode HA的区别
NN HA中,DN会同时向ActiveNN和StandbyNN发送心跳。 RM HA中,NM只会向ActiveRM发送心跳。StandyRM中的很多服务甚至不会启动,见代码(ResourceManager类): 这个机制决定了RM的HA切换会比较慢,不像NN的切换那么迅速。
RM HA的另一个不同之处是选举机制内建在RM里(EmbeddedElectorService类),而NN HA是用单独的zkfc进程进行选举的。zkfc进程和NN进程通过RPC协议(ZKFCProtocol)进行通信。 zkfc的隔离性比较好。比如NN进程意外挂掉时,zkfc很快会监控到NN挂掉并重新发起选举。 如果是内建选举机制,可能会有bug,比如RM进程意外挂掉(比如直接kill -9),要等zk超时后才能再次选举。failover的时间会比较长。
为什么在Yarn中的ZKFC是线程级别的?为什么架构设计没有HDFS那么复杂?
因为Yarn主要是用来跑job任务,如果job挂了可以重新跑一次;然而数据是不可以丢失的,在HDFS是进程级别的,保证数据的高可靠性。