存储格式基本概念
官网介绍:
Hive supports several file formats:
* Text File
* SequenceFile
* RCFile
* Avro Files
* ORC Files
* Parquet
* Custom INPUTFORMAT and OUTPUTFORMAT
默认textfile的使用:
hive>create table t1(id int, name string) stored as textfile;
hive>create table t(id int, name string);
默认的存储格式是textfile,上面2条SQL语句是一样的效果。
hive>desc formatted t1;
默认为textfile格式时候的格式:
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
hive>desc formatted t;
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
产生的结果与textfile相同。 注意:inputformat与outputformat可以自己进行自定义
发展历程:
| TEXTFILE – (Default, depending on hive.default.fileformat configuration)
| RCFILE – (Note: Available in Hive 0.6.0 and later)
| ORC – (Note: Available in Hive 0.11.0 and later)
| PARQUET – (Note: Available in Hive 0.13.0 and later)
| AVRO – (Note: Available in Hive 0.14.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
建议:使用ORC和Parquet
行式存储 VS 列式存储
行式存储
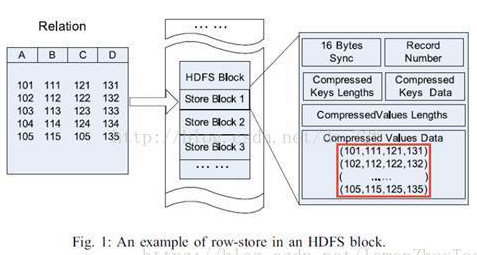
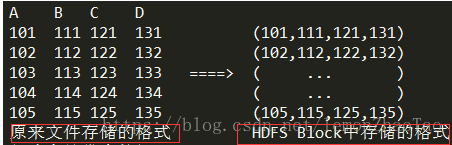
如上图所示,行式存储的结构: 假设文件中有ABCD 4列,5行数据
对应于HDFS里面就是Block
那么在Block里面是什么样的结构呢? 关注红框内的内容:
行式存储带来的好处 对于每一行数据的每一列,必然是在同一个Block里面的。
行式存储带来的坏处 因为每一行记录有很多列,每一列的数据类型可能会是不一样的。
-
如果每一列的数据类型都不一样,那么在压缩的时候,会带来麻烦, 每种类型的压缩比都不一样,无法达到每种类型数据压缩比达到最好的效果
-
select a,b from xxx; 对于行式存储,是需要将所有的列都给读取出来的 也就是说c和d我们虽然用不上,但是它也会去读,这样会造成IO的提升
列式存储
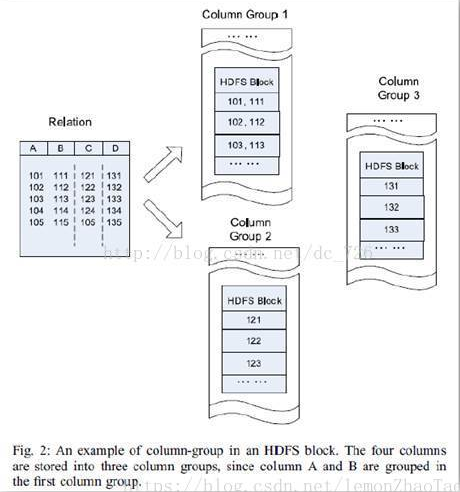
如上图所示,列式存储的结构: 把每一行中的列给拆开了,存放在不同的Block里面了,列式存储不能保证同一行记录的所有列在同一个Block里面的,AB两列存在1个Block里,C列存在1个Block里,D列存在1个Block里。
-
这样会带来一个很好的优势 既然是同一列的数据存储在同一个Block里面的,那么数据类型必然可以是一样的,就可以采用压缩比更高的方式进行压缩。
-
select c from xxx; 只需要拿走1个Block里面的数据就可以了,不用去碰其余两个Block里的数据 IO大幅度的减少
-
缺点: 查询的东西一多,要读取的Block多
===>
如果我们使用select * from xxx; 行式和列式可能没有多大的区别,如果我们查的是某些字段,那么列式的优势就体现出来了。
在我们的大数据场景来说:可能我们有几百列,但是我们所查询的就只有几列,这种场景下,使用列式存储更好。
TextFile
默认的存储格式 普通文件/jsion/xml ====> 使用TextFile进行压缩
注意:使用TextFile进行压缩,很多都是当作字符串来进行处理的
SequenceFile
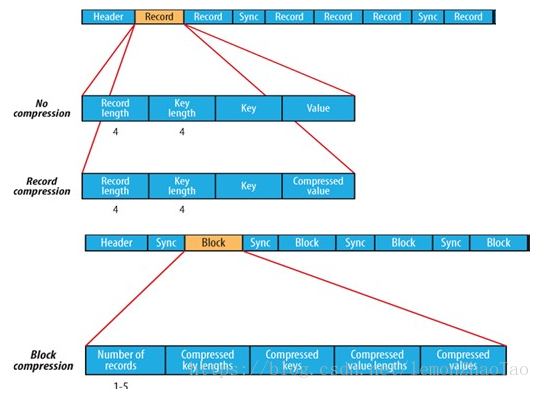
如上图所示,Record是真正存放数据的,有3种级别:
-
No compression的Record: RecordLength KeyLength Key Value
-
Record compression的Record: RecordLength KeyLength Key CompressedValue
-
Block compression的Record: Number of records CompressedKeyLength CompressedKeys CompressedValueLengths CompressedValues
假设: record length = 10,key length = 4,那么value的length就是6,按照SequenceFile的存储形式,当我们读value的时候,拿到RecordLength和KeyLength,可以直接 跳过Key,直接去拿Value。 ===> 这样在查询的时候可能会好很多。
注意:Sequence用得很少
性能测试:
hive>create table page_views_seq(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as sequencefile;
hive>LOAD DATA LOCAL INPATH '/home/hadoop/data/data.log' OVERWRITE INTO TABLE page_views_seq;
Loading data to table hive.page_views_seq
Failed with exception Wrong file format. Please check the file's format.
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask
hive>
会报错: Failed with exception Wrong file format. 原因: 对于SequenceFile来说,是不能直接load的 解决方法: 先在Hive表中创建一张textfile存储格式的表,然后再将这个表的数据给灌进来到SequenceFile为存储格式的表中来
hive>insert into table page_views_seq select * from page_views;
查看源文件大小
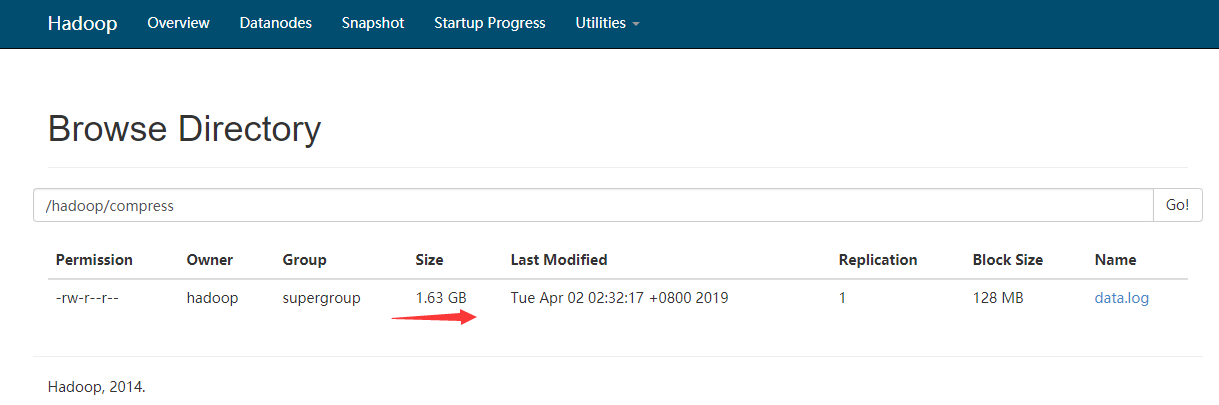
使用SequenceFile后
[hadoop@hadoop001 ~]$ hdfs dfs -du -h /user/hive/warehouse/hive.db/page_views_seq
266.0 M 266.0 M /user/hive/warehouse/hive.db/page_views_seq/000000_0
263.8 M 263.8 M /user/hive/warehouse/hive.db/page_views_seq/000001_0
263.8 M 263.8 M /user/hive/warehouse/hive.db/page_views_seq/000002_0
263.8 M 263.8 M /user/hive/warehouse/hive.db/page_views_seq/000003_0
263.8 M 263.8 M /user/hive/warehouse/hive.db/page_views_seq/000004_0
263.8 M 263.8 M /user/hive/warehouse/hive.db/page_views_seq/000005_0
141.8 M 141.8 M /user/hive/warehouse/hive.db/page_views_seq/000006_0
266 + 263.8 * 5 + 141.8 = 1726.8M > 1.63 *1024 = 1669.12M
为啥会比源文件大? 因为SequenceFile多了header等这些信息。SequenceFile是基于行式存储来做的现在生产环境上使用SequenceFile不多。并且是自动分片的,7个map。
RCFile(Record Columnar File)
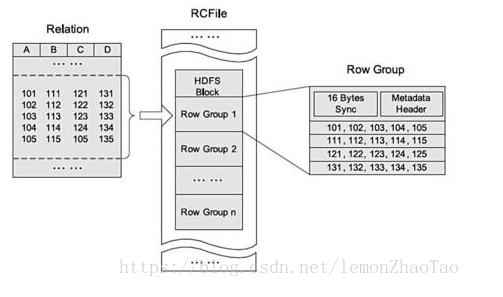
如上图所示,RCFile是Facebook开源的,FCFile是行列存储混合的(从上图也可以体现出来),一个Row Group 为4M。
性能测试
hive>create table page_views_rc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as rcfile;
hive>insert into table page_views_rc select * from page_views;
查看大小(使用RCFile)
[hadoop@hadoop001 ~]$ hdfs dfs -du -h /user/hive/warehouse/hive.db/page_views_rc/
229.5 M 229.5 M /user/hive/warehouse/hive.db/page_views_rc/000000_0
227.6 M 227.6 M /user/hive/warehouse/hive.db/page_views_rc/000001_0
227.6 M 227.6 M /user/hive/warehouse/hive.db/page_views_rc/000002_0
227.6 M 227.6 M /user/hive/warehouse/hive.db/page_views_rc/000003_0
227.6 M 227.6 M /user/hive/warehouse/hive.db/page_views_rc/000004_0
227.6 M 227.6 M /user/hive/warehouse/hive.db/page_views_rc/000005_0
122.4 M 122.4 M /user/hive/warehouse/hive.db/page_views_rc/000006_0
229.5 + 227.6 * 5 + 122.4 = 1489.9M < 1.63 *1024 = 1669.12M
注意:默认也是支持分片的,也是7个map
ORC
其中,O指的是:Optimized(优化)。(Optimized Record Columnar File)
ORC结构
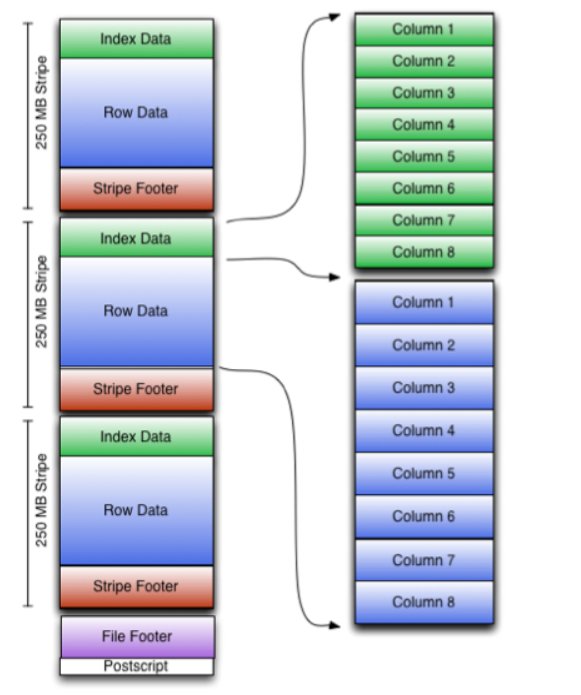
ORC存储结构如图所示,引入了以下几个概念: Stripe(一个Stripe为250M): Index Data + Row Data + Stripe Footer Index Data:轻量级的索引库,在一个Stripe里面,如果是数值类型的会存最大与最小值;如果是字符串会存前后缀; 这样存的好处是:
- 当你的SQL语句后面有个where,你写了个id > 100,如果第一个Stripe里存的是0 ~ 99;第2个Stripe里存的是100~199; 第3个Stripe里存的是200~299;那么我们刚刚那个SQL语句,第1个Stripe就不会去读了。这样子,查询的性能肯定是会有提升的。
Stripe Footer:存的是类型; 这个不用太去关注。 查询数据的时候,先去查索引,如果不满足,那么这个Stripe就不会去读取了。这样就提升了性能
性能测试
采用压缩(默认使用的是Zlib压缩)
查看大小(使用ORC之后,并且采用压缩),也是支持分片的,7个mappers
[hadoop@hadoop001 ~]$ hdfs dfs -du -h /user/hive/warehouse/hive.db/page_views_orc/
68.9 M 68.9 M /user/hive/warehouse/hive.db/page_views_orc/000000_0
68.3 M 68.3 M /user/hive/warehouse/hive.db/page_views_orc/000001_0
68.3 M 68.3 M /user/hive/warehouse/hive.db/page_views_orc/000002_0
68.3 M 68.3 M /user/hive/warehouse/hive.db/page_views_orc/000003_0
68.3 M 68.3 M /user/hive/warehouse/hive.db/page_views_orc/000004_0
68.3 M 68.3 M /user/hive/warehouse/hive.db/page_views_orc/000005_0
36.7 M 36.7 M /user/hive/warehouse/hive.db/page_views_orc/000006_0
68.9 + 68.3 * 5 + 36.7 = 477.2M < 1.63 *1024 = 1669.12M
不采用压缩
hive>create table page_views_orc_none
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
stored as orc TBLPROPERTIES("orc.compress"="NONE");
报错: FAILED: SemanticException [Error 10043]: Either list of columns or a custom serializer should be specified
原因:没有指定数据源
hive>create table page_views_orc_none
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
stored as orc TBLPROPERTIES("orc.compress"="NONE")
as select * from page_views;
查看大小(使用ORC之后,不采用压缩),也是支持分片的,7个map
[hadoop@hadoop001 ~]$ hdfs dfs -du -h /user/hive/warehouse/hive.db/page_views_orc_none/
182.0 M 182.0 M /user/hive/warehouse/hive.db/page_views_orc_none/000000_0
180.5 M 180.5 M /user/hive/warehouse/hive.db/page_views_orc_none/000001_0
180.5 M 180.5 M /user/hive/warehouse/hive.db/page_views_orc_none/000002_0
180.5 M 180.5 M /user/hive/warehouse/hive.db/page_views_orc_none/000003_0
180.5 M 180.5 M /user/hive/warehouse/hive.db/page_views_orc_none/000004_0
180.5 M 180.5 M /user/hive/warehouse/hive.db/page_views_orc_none/000005_0
97.0 M 97.0 M /user/hive/warehouse/hive.db/page_views_orc_none/000006_0
182 + 180.5 * 5 + 97 = 1181.5 M < 1.63 *1024 = 1669.12M
Parquet
性能测试
不采用压缩(默认是不采用压缩的)
hive>create table page_views_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as parquet;
hive>insert into table page_views_parquet select * from page_views;
查看大小(使用Parquet后,不采用压缩),也是支持分片的,7个map
[hadoop@hadoop001 ~]$ hdfs dfs -du -h /user/hive/warehouse/hive.db/page_views_parquet/
192.8 M 192.8 M /user/hive/warehouse/hive.db/page_views_parquet/000000_1
191.2 M 191.2 M /user/hive/warehouse/hive.db/page_views_parquet/000001_1
191.2 M 191.2 M /user/hive/warehouse/hive.db/page_views_parquet/000002_0
191.2 M 191.2 M /user/hive/warehouse/hive.db/page_views_parquet/000003_0
191.2 M 191.2 M /user/hive/warehouse/hive.db/page_views_parquet/000004_0
191.2 M 191.2 M /user/hive/warehouse/hive.db/page_views_parquet/000005_0
101.8 M 101.8 M /user/hive/warehouse/hive.db/page_views_parquet/000006_0
192.8 + 192.2 * 5 + 101.8 = 1255.6M < 1.63 * 1024 = 1669.12M
采用压缩(设置为Gzip压缩)
hive>set parquet.compression=GZIP; // 设置压缩方式
hive>create table page_views_parquet_gzip(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as parquet;
hive>insert into table page_views_parquet_gzip select * from page_views;
查看大小(使用ORC之后,采用压缩),默认也是支持分片的,7个map
[hadoop@hadoop001 ~]$ hdfs dfs -du -h /user/hive/warehouse/hive.db/page_views_parquet_gzip/
64.5 M 64.5 M /user/hive/warehouse/hive.db/page_views_parquet_gzip/000000_0
64.0 M 64.0 M /user/hive/warehouse/hive.db/page_views_parquet_gzip/000001_0
64.0 M 64.0 M /user/hive/warehouse/hive.db/page_views_parquet_gzip/000002_0
64.0 M 64.0 M /user/hive/warehouse/hive.db/page_views_parquet_gzip/000003_0
64.0 M 64.0 M /user/hive/warehouse/hive.db/page_views_parquet_gzip/000004_0
64.0 M 64.0 M /user/hive/warehouse/hive.db/page_views_parquet_gzip/000005_0
34.5 M 34.5 M /user/hive/warehouse/hive.db/page_views_parquet_gzip/000006_0
64.5 + 64.0 * 5 + 34.5 = 419M < 1.63 * 1024 = 1669.12M
各种存储格式的读性能测试
hive>select count(1) from page_views where session_id='xxxxxxx';
hive>select count(1) from page_views_seq where session_id='xxxxxxx';
hive>select count(1) from page_views_rc where session_id='xxxxxxx';
hive>select count(1) from page_views_orc where session_id='xxxxxxx';
hive>select count(1) from page_views_orc_none where session_id='xxxxxxx';
hive>select count(1) from page_views_parquet where session_id='xxxxxxx';
hive>select count(1) from page_views_parquet_gzip where session_id='xxxxxxx';
注: session_id以xxx代替,本文只是提供一种测试的思路
通过打印在控制台上的信息 去观察 HDFS Read,各种格式的对比如下:
| 存储格式 | 读的速度 |
|---|---|
| textfile | HDFS Read: 1755026906 |
| seq | HDFS Read: 1810686304 |
| rc | HDFS Read: 24384181 |
| orc_zlib | HDFS Read: 140918 |
| orc_none | HDFS Read: 1697274 |
| parquet | HDFS Read: 65041 |
| parquet_gzip | HDFS Read: 27936 |