1. Yarn 简介
Yarn 是 hadoop 集群的资源管理层。它允许不同的数据处理引擎(如图形处理、交互式 SQL、流处理、批处理)运行在 hadoop 集群中并处理 HDFS 中的数据(移动计算而非数据)。除了资源管理外,Yarn 还用于作业调用。
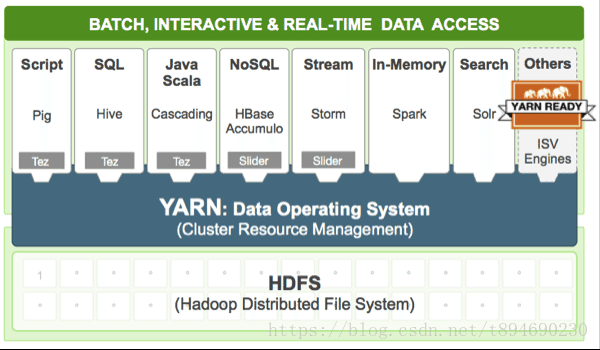
从资源管理方面看,Yarn 管理着由各个 NodeManager 节点的 vcore(CPU内核)和 RAM(运行时内存)共同组成的一组资源,比如我们的一个集群由35个 NodeManager 节点共560 vcores 和 3.4TiB的内存组成,那么 Yarn 管理的资源大小便是560 vcores + 3.4TiB RAM。当我们提交一个应用程序到 hadoop 集群时,Yarn 便会为这个应用程序分配一个资源池,这个资源池包含一定数量的 containers,每个 container 又包含一定数量的 vcores 和内存供应用程序运行。
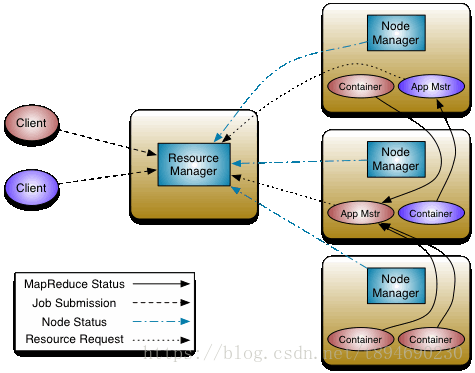
2. Yarn 组件
Yarn 采用传统的 master-slave 架构模式,其主要由 4 种组件组成,它们的主要功能如下:
- ResourceManager(RM):全局资源管理器,负责整个系统的资源管理和分配;
- ApplicationMaster(AM):负责应用程序(Application)的管理;
- NodeManager(NM):负责 slave 节点的资源管理和使用;
- Container(容器):对任务运行环境的一个抽象。
2.1 ResourceManager (RM)
ResourceManager 是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件组成:
- Scheduler:资源调度器,主要功能和特点如下:
- 负责将资源分配给各种正在运行的应用程序,这些应用程序受到容量、队列等限制;
- Scheduler 是纯调度程序,不会监视或跟踪应用程序的状态;
- 由于应用程序故障或硬件故障,它不提供有关重新启动失败任务的保证;
- Scheduler 根据应用程序的资源需求来执行其调度功能,它是基于资源容器的抽象概念来实现的,容器(Container)内包含内存、CPU、磁盘、网络等因素;
- Scheduler 是一个可插拔的插件(即可配置),负责在各种队列、应用程序等之间对集群资源进行区分。当前支持的Scheduler类包括:FairScheduler、FifoScheduler、CapacityScheduler;
- ApplicationsManager:负责接受 job 提交请求,为应用程序分配第一个 Container 以运行 ApplicationMaster,并提供失败时重新启动运行着 ApplicationMaster 的 Container 的服务。
2.2 ApplicationMaster(AM)
当用户提交一个应用程序时,将启动一个被称为 ApplcationMaster 的轻量级进程的实例,用以协调应用程序内所有任务的执行。它的主要工作包括:
- 向 ResourceManager 申请并以容器(Container)的形式提供计算资源;
- 管理在容器内运行的任务:
- 跟踪任务的状态并监视它们的执行;
- 遇到失败时,重新启动失败的任务;
- 推测性的运行缓慢的任务以及计算应用计数器的总值。
2.3 NodeManager(NM)
NodeManager 进程运行在集群中的节点上,是每个节点上的资源和任务管理器。它的主要功能包括:
- 接收 ResourceManager 的资源分配请求,并为应用程序分配具体的 Container;
- 定时地向 ResourceManager 汇报本节点上的资源使用情况和各个 Container 的运行状态,以确保整个集群平稳运行;
- 管理每个 Container 的生命周期;
- 管理每个节点上的日志;
- 接收并处理来自 ApplicationMaster 的 Container 启动/停止等请求。
2.4 Container(容器)
Container 是 Yarn 中的资源抽象,是执行具体应用的基本单位,它包含了某个 NodeManager 节点上的多维度资源,如内存、CPU、磁盘和网络 IO,当然目前仅支持内存和 CPU。
任何一个 Job 或应用程序必须运行在一个或多个 Container 中,在 Yarn 中,ResourceManager 只负责告诉 ApplicationMaster 哪些 Containers 可以用,ApplicationMaster 需要自己去找 NodeManager 请求分配具体的 Container。
Container 和集群节点的关系是:一个节点会运行多个 Container,但一个 Container 不会跨节点。
3. Yarn 工作流程(MapReduce提交应用程序)
3.1 进程
-
ResourceManager
-
NodeManager
3.2 命令
yarn application –list
yarn application –kill -applicationId <application ID>
yarn logs -applicationId <application ID>
[hadoop@hadoop001 bin]$ yarn
Usage: yarn [--config confdir] COMMAND
where COMMAND is one of:
resourcemanager -format-state-store deletes the RMStateStore
resourcemanager run the ResourceManager
nodemanager run a nodemanager on each slave
timelineserver run the timeline server
rmadmin admin tools
version print the version
jar <jar> run a jar file
application prints application(s)
report/kill application
applicationattempt prints applicationattempt(s)
report
container prints container(s) report
node prints node report(s)
queue prints queue information
logs dump container logs
classpath prints the class path needed to
get the Hadoop jar and the
required libraries
daemonlog get/set the log level for each
daemon
top run cluster usage tool
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
[hadoop@hadoop001 bin]$
[hadoop@hadoop001 bin]$ yarn application
19/03/18 20:27:28 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
19/03/18 20:27:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Invalid Command Usage :
usage: application
-appStates <States> Works with -list to filter applications
based on input comma-separated list of
application states. The valid application
state can be one of the following:
ALL,NEW,NEW_SAVING,SUBMITTED,ACCEPTED,RUN
NING,FINISHED,FAILED,KILLED
-appTypes <Types> Works with -list to filter applications
based on input comma-separated list of
application types.
-help Displays help for all commands.
-kill <Application ID> Kills the application.
-list List applications. Supports optional use
of -appTypes to filter applications based
on application type, and -appStates to
filter applications based on application
state.
-movetoqueue <Application ID> Moves the application to a different
queue.
-queue <Queue Name> Works with the movetoqueue command to
specify which queue to move an
application to.
-status <Application ID> Prints the status of the application.
[hadoop@hadoop001 bin]$
3.3 Yarn 工作流程(MR提交应用程序)
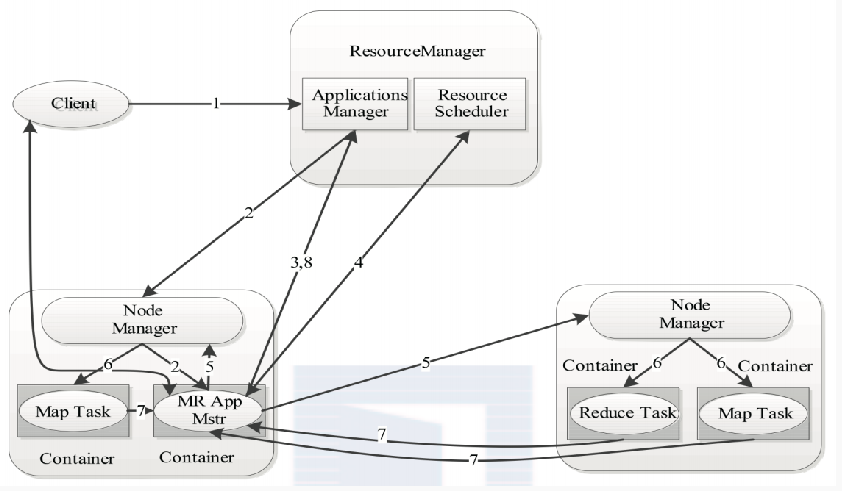
1: 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
2: ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个 Container中启动应用程序的ApplicationMaster。
3: ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的 运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
4: ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
5: 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
6: NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一 个脚本中,并通过运行该脚本启动任务。
7: 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握 各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向 ApplicationMaster查询应用程序的当前运行状态。
8: 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
a. 第一个阶段是启动ApplicationMaster;
b. 第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直 到运行完成。
3.4 Yarn 资源管理与调度、参数配置
在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负 责资源的分配,而NodeManager则负责资源的供给和隔离。
ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的资源调度)后,NodeManager需按 照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的 资源隔离。
3.5 Memory资源的调度和隔离
基于以上考虑,YARN允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上的内存会被若 干个服务共享,比如一部分给YARN,一部分给HDFS,一部分给HBase等,YARN配置的只是自己可以使用的,配置参数如下:
(1) yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB, 则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(2) yarn.nodemanager.vmem-pmem-ratio
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。
(3) yarn.nodemanager.pmem-check-enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(4) yarn.nodemanager.vmem-check-enabled 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(5) yarn.scheduler.minimum-allocation-mb 单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
(6) yarn.scheduler.maximum-allocation-mb 单个任务可申请的最多物理内存量,默认是8192(MB)。
默认情况下,YARN采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于Cgroups对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报OOM),而Java进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此YARN未提供Cgroups内存隔离机制。
3.6 CPU资源的调度和隔离
目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念, 初衷是,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。在YARN中,CPU 相关配置参数如下:
(1) yarn.nodemanager.resource.cpu-vcores
表示该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数
数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数。
(2) yarn.scheduler.minimum-allocation-vcores
单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应
的值改为这个数。
(3) yarn.scheduler.maximum-allocation-vcores
单个任务可申请的最多虚拟CPU个数,默认是32。
默认情况下,YARN是不会对CPU资源进行调度的,你需要配置相应的资源调度器。
4. 提交任务流程
4.1 客户端向RM提交任务流程
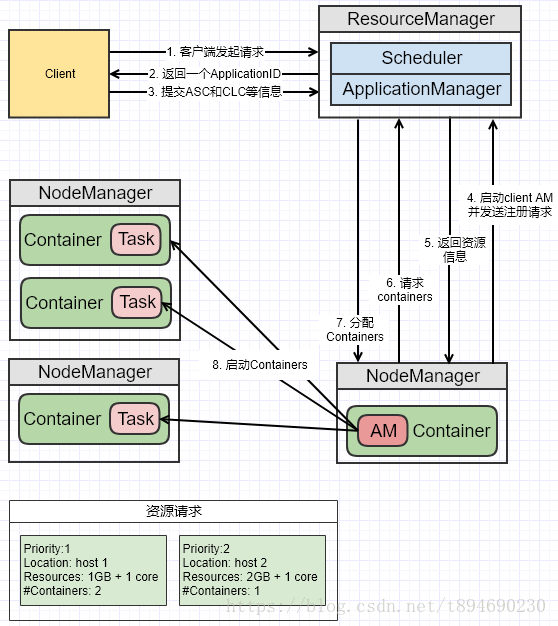
说明:
- 客户端向 RM 发出请求;
- RM 返回一个 ApplicationID 作为回应;
- 客户端向 RM 回应 Application Submission Context(ASC)和 Container Launch Context(CLC)信息。其中 ASC 包括 ApplicationID、user、queue,以及其它一些启动 AM 相关的信息,CLC 包含了资源请求数(内存与CPU),Job 文件,安全 token,以及其它一些用于在 NM 上启动 AM的信息;
- 当 ResourceManager 接受到 ASC 后,它会调度一个合适的 container 来启动 AM,这个 container 经常被称做 container 0。AM 需要请求其它的 container 来运行任务,如果没有合适的 RM,AM 就不能启动。当有合适的 container 时,RM 发请求到合适的 NM 上,来启动 AM。这时候,AM 的 PRC 与监控的 URL 就已经建立了;
- 当 AM 启动起来后,RM 回应给 AM 集群的最小与最大资源等信息。这时 AM 必须决定如何使用那么当前可用的资源。YARN 不像那些请求固定资源的 scheduler,它能够根据集群的当前状态动态调整;
- AM 根据从 RM 那里得知的可使用的资源,它会请求一些一定数目的 container。这个请求可以是非常具体的包括具有多个资源最小值的 Container(例如额外的内存等);
- RM 将会根据调度策略,尽可能的满足 AM 申请的 container;
- AM 根据分配的信息,去找NM启动对应的 container。
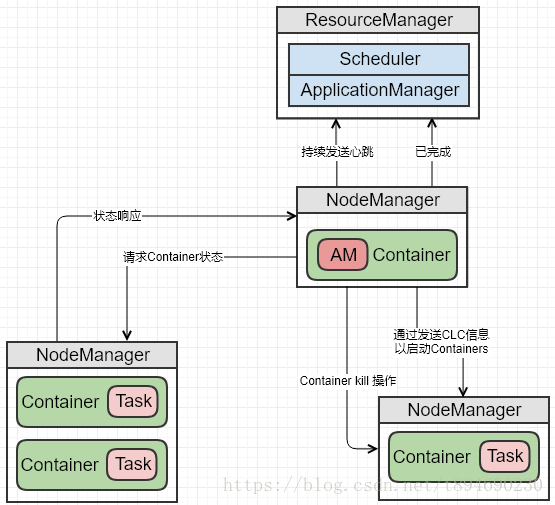
4.2 运行状态交互
当一个任务运行时,AM 会向 RM 汇报心跳与进度信息,在这些心跳过程中,AM 可能会去申请或者释放 Container。当任务完成时,AM 向 RM 发送一条任务结束信息然后退出。AM 与 RM 交互的示例如下图:
5. Yarn 三种调度器
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源。在Yarn中,负责给应用分配资源的就是Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,Yarn提供了多种调度器和可配置的策略供我们选择。
在Yarn中有三种调度器可以选择:FIFO Scheduler ,Capacity Scheduler,Fair Scheduler。
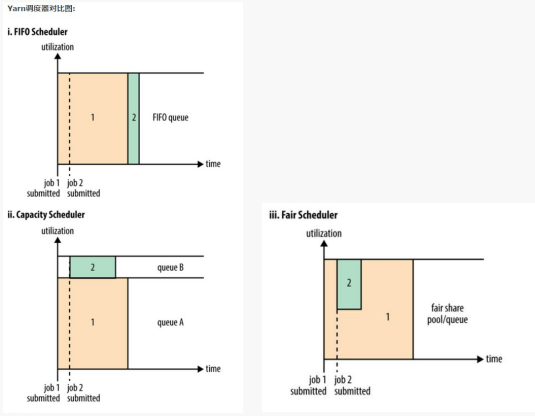
FIFO Scheduler 把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler 是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
在FIFO 调度器中,小任务会被大任务阻塞。她适合在任务数量不多的情况下使用。
而对于Capacity调度器,有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。她适用于有很多小的任务跑,需要占很多队列,不使用队列,会造成资源的浪费。
在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。如下图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。
6. 面试题
6.1 请问RresourceManager 节点上有Containere容器的说法对吗?
答案:错误。Container容器只运行在 Node Manager上面。
6.2 在AM中,job已经被分成一系列的task,并且是为每个task来startContainer。为什么NM上要存一个application的数据结构呢?
答案:在Yarn看来,他所维护的所有应用程序叫Application,但是到了计算框架这一层,各自有各自的名字,mapreduce叫job,storm叫topology等等,YARN是资源管理系统,不仅仅运行mapreduce,还有其他应用程序,mapreduce只是一种计算应用。但是yarn内部设有应用程序到计算框架应用程序的映射关系(通常是id的映射),你这里所说的应用程序,job属于不同层面的概念,切莫混淆,要记住,YARN是资源管理系统,可看做云操作系统,其他的东西,比如mapreduce,只是跑在yarn上的application,但是,mapreduce是应用层的东西,它可以有自己的属于,比如job task,但是yarn专业一层是不知道或者说看不到的。
6.3 是否只有负责启动ApplicationMaster的NodeManager才会维护一个Application对象?其他的NodeManager是否是根据ApplicationMaster发起的请求来启动属于这个Application的其他Container,这些NodeManager不需要维护Application的状态机?
答案:都需要维护,通过Application状态机可将节点上属于这个App的所有Container聚集在一起,当需要特殊操作,比如杀死Application时,可以将对应的所有Container销毁。另外,需要注意,一个应用程序的ApplicationMaster所在的节点也可以运行它的container,这都是随机的。
6.4 Container的节点随机性?
答案:Container的节点随机性,我的理解是Container运行的节点是由分配资源时集群中哪些节点正好是空闲的来决定的,ResourceManager在为ApplicationMaster分配所需的Container的时候,完全有可能出现ApplicationMaster的本地节点上出现了空闲资源,这样,如果分配成功之后,ApplicationMaster就和所属的Container运行在一个节点上了。
6.5 Yarn在维护的那个application数据结构中能够表示该application的哪部分正在运行?
答案:YARN不需要知道是job还是其他东西与它交互,在他看来,只有application,YARN为这些applicaiton提供了两类接口,一个是申请资源,具体申请到资源后,applicaiton用来干啥,跑map task还是跑MPI task,YARN不管,二是运行container的命令(container里面包的是task或者其他application内部要跑的东西),一般是一个shell命令,用于启动container(即启动task)。YARN看不到application什么时候运行完,他还有几个task没跑,这些只有applicaiton自己知道,当application运行结束后,会告诉YARN,YARN再将他所有信息抹掉。