1. Scala简介
官网:https://www.scala-lang.org/ Scala语言很强大,集成了面向对象和函数式编程的特点。Scala是多范式的编程语言(支持多种方式的编程)
- 使用面向对象编程
- 使用函数式编程:最大的特点
- 函数式编程的优点:使得代码非常简介
- 函数式编程的缺点:可读性太差,尤其是隐式类,隐式函数,隐式参数
运行在JVM(jdk)。 大数据中为什么学习scala? spark是scala语言编写。 python写spark 挺好的 java写spark 很糟糕(代码实在是太多了) scala写spark 很完美
1.1 Scala特点
(1)优雅 框架设计中第一个要考虑的问题就是API是否优雅。 精简的封装。 代码精简(少)。 (2)速度快 scala语言表达能力强。 一行代码=多行java代码,开发速度快。 (3)完美融合hadoop生态 scala是静态编译,表达能力强并且代码量少。
1.2 安装Scala
(1)下载 (2)解压 (3)配置环境变量 SCALA_HOME= path
1.3 Scala基础语法
(1)Scala程序的开始 helloworld
object HelloWorld {
def main(args: Array[String]): Unit = {
print("Hello world")
}
}
(2)Scala的数据类型 Scala与java一样,有8中数值类型: Byte/Char/Short/Int/Long/Float/Double/Boolean/ 和Unit类型(void),Nothing类型
注意:scala中无包装类型。
- Unit:表示无值,用于不返回任何结果的方法的结果类型。注意:类型要保持一致 Unit = ():()相当于什么都没有用()表示。
scala> val a:Unit = println("haha")
haha
a: Unit = ()
scala> val a = () # 小括号代表一个函数,没有返回值。
a: Unit = ()
- Nothing 一般来说,在执行的过程中,产生了Exception。
scala> def myfunction = throw new Exception("Some Error")
myfunction: Nothing
(3)Scala定义变量 两个关键字:val var
val:定义变量值不可变
scala> val a = 1
a: Int = 1
scala> a = 2
<console>:15: error: reassignment to val
a = 2
^
var:定义的变量值是可变的
scala> var b = 1
b: Int = 1
scala> b = 2
b: Int = 2
scala编译器会自动的推断类型! 指定类型: val str:String = “haha”
scala> val i = 1.2
i: Double = 1.2
scala> val j = i.asInstanceOf[Float]
j: Float = 1.2
scala> i.isInstanceOf[Int]
res8: Boolean = false
scala> i.isInstanceOf[Double]
res10: Boolean = true
scala> val j = 1L
j: Long = 1
scala> val a:Long = 1
a: Long = 1
scala> val i = 1.2
i: Double = 1.2
scala> val j = 1L
j: Long = 1
scala> val b:Int = 1.1 # 注意:指定为了Int类型后,不能再修改为Long类型
<console>:14: error: type mismatch;
found : Double(1.1)
required: Int
val b:Int = 1.1
^
scala> val b:String = "haha"
b: String = haha
asInstanceOf[ ]是做类型的转换,isInstanceOf[ ]是用来判断类型的。
(4)条件表达式 if:判断
scala> val x = 2
x: Int = 2
scala> val y = if(x>0) 1 else 2
y: Int = 1
scala> val z = if(x>0) "error" else 1
z: Any = error
注意:
Any:包含Anyval和AnyRef
Anyval:包含scala所有类型
AnyRef:Scala classes与Java Classes
Any相当于java的Object
scala> val m = if(x >= 2) 1
m: AnyVal = 1
scala> val m = if(x >= 2) 1 else ()
m: AnyVal = 1
# 注意:这2种的表达的意思是一样的,上面的是下面的简写。
scala> val k = if(x<0) 0 else if(x>=1) 1 else -1
k: Int = 1
scala> x
2
if和else if:多个条件的判断,符合条件看左侧,不符合条件看右侧
(5)块表达式
在scala中{}包含一系列表达式,块中的最后一个表达式的值就是块的值
object ScalaDemo01 {
def main(args: Array[String]): Unit = {
//块表达式
val a = 1
val rs = {
if(a > 2){
1
}else if (a < 2){
-1
}else {
0
}
}
print(rs)
}
}
(6)循环
scala> 1 to 10 # to 从1到10
res59: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
# 1 to 10 还可以写成 1.to(10)
scala> 1.to(10)
res2: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
# 1 是一个对象,to是一个方法
scala> for(x <- res59) println(x) # 用for循环操作
1
2
3
4
5
6
7
8
9
10
scala> val rs = 1 to 10
rs: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> for(i <- rs) print(i)
12345678910
# 求1到10之间的偶数的平方
scala> (1 to 10).filter(_ % 2 == 0).map(x=>(x*x))
res23: scala.collection.immutable.IndexedSeq[Int] = Vector(4, 16, 36, 64, 100)
scala> for(x <- 1 to 10 if x % 2 ==0) yield x*x
res15: scala.collection.immutable.IndexedSeq[Int] = Vector(4, 16, 36, 64, 100)
scala> (1 until 10).filter(_ % 2 == 0).map(x=>(x*x))
res37: scala.collection.immutable.IndexedSeq[Int] = Vector(4, 16, 36, 64)
# 遍历数组
scala> val arr = Array(1,3,5)
arr: Array[Int] = Array(1, 3, 5)
scala> for(i <- arr) println(i)
1
3
5
# 更复杂的for循环
scala> for(i <- 1 to 10;j <- 1 to 5 if i != j ) print((10*i+j)+"\t")
12 13 14 15 21 23 24 25 31 32 34 35 41 42 43
45 51 52 53 54 61 62 63 64 65 71 72 73 74 75
81 82 83 84 85 91 92 93 94 95 101 102 103 104 105
yield:生成一个新的集合关键字
scala> val rs = for(i <- 1 to 10) yield i * 10 # 类似于map
rs: scala.collection.immutable.IndexedSeq[Int] = Vector(10, 20, 30, 40, 50, 60, 70, 80, 90, 100)
scala> val a = for(i <- 1 to 10;if(i %2 ==1)) yield i
a: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 3, 5, 7, 9)
map:取出每个元素,并且为每个元素加上10。
注意:map取出元素;_表示元组
scala> 1.to(10).map(_+10)
res3: scala.collection.immutable.IndexedSeq[Int] = Vector(11, 12, 13, 14, 15, 16, 17, 18, 19, 20)
(7)方法定义 Scala中的 + - * / % 的作用和Java一样,但是特别的是,这些操作符实际上是方法。
object ScalaDemo02 {
def main(args: Array[String]): Unit = {
println(m1(1,9))
println(m2(2,3))
}
//加法
def m1(a:Int,b:Int):Int = {
a + b
}
//乘法
def m2(a:Int,b:Int):Int = a * b
}
执行上面代码运行的结果为:
10
6
注意:
def:定义方法的关键字, m1:方法名 ,a:参数列表, b:参数列表, Int:返回值类型, a + b:函数体
scala> def callHaha = println("Hello World") #定义无参的方法
callHaha: Unit
scala> callHaha
Hello World
scala> def m2(a:Int,b:Int):Int = a * b
m2: (a: Int, b: Int)Int
scala> m2(2,5)
res9: Int = 10
scala> def m3 = println("haha")
m3: Unit
scala> m3
haha
2.函数
2.1 函数简介
函数是Scala的头等公民。 [Scala 2.11.8 的官方文档地址]:(https://www.scala-lang.org/files/archive/api/2.11.8/#package)
- Scala 的内置函数:举例:求最大值
scala> max(2,4)
<console>:12: error: not found: value max
max(2,4)
^
scala> import scala.math._ # 需要导入包进来
import scala.math._
scala> max(2,4)
res1: Int = 4
scala> //本质是定义了 变量来保存执行的结果
scala> var a1:Int = max(1,2)
a1: Int = 2
scala> var a2 = max(1,2)
a2: Int = 2
1)方式1: 方法转换为函数,方法名 _
scala> def m2(a:Int,b:Int):Int = a * b
m2: (a: Int, b: Int)Int
scala> m2 _ # 可以直接将方法转化为函数
res17: (Int, Int) => Int = <function2>
# 说明:<function2>代表一个函数,并且有2个参数。(Int,Int)代表参数列表;Int代表返回值类型;=>代表函数
scala> m2_ # 注意:m2后面的空格
<console>:12: error: not found: value m2_
m2_
^
scala> def m1(a:String) = println(a)
m1: (a: String)Unit
scala> m1("hahaha")
hahaha
scala> m1 _
res20: String => Unit = <function1>
2)方式2: 定义函数
scala> (a:Int,b:Int) => a * b
res24: (Int, Int) => Int = <function2>
scala> res24(3,5)
res25: Int = 15
scala> val a = (a:Int,b:Int) => {a * b}
a: (Int, Int) => Int = <function2>
# 说明:a 为函数名;(a:Int,b:Int):函数的参数类型;{a * b} 为函数体
scala> a(3,5)
res26: Int = 15
- 举例:函数的求和运算 与 求阶乘,采用递归。
# 函数的求和运算
scala> def sum(x:Int,y:Int):Int = {x+y}
sum: (x: Int, y: Int)Int
scala> sum(10,20)
res2: Int = 30
scala> val a = sum(10,20)
a: Int = 30
# 求阶乘,采用递归
scala> def myFactor(x:Int):Int = {
| // 采用阶乘
| if (x <= 1)
| 1
| else
| //执行递归
| x * myFactor(x-1)
| }
myFactor: (x: Int)Int
scala> myFactor(5)
res3: Int = 120
注意: 函数没有return 子句,函数最后一句话就是函数的返回值。
2.2 传值调用和传名调用
object ZFBToPay {
var money = 1000
//吃一次饭花50元
def eat() = {
money = money - 50
}
//余额
def balance(): Int ={
//已调用一次eat方法
eat()
money
}
//此时余额减了5次,x: => Int 表示的是一个方法的签名,没有参数,返回值是int 类型的函数
def printMoney(x: => Int):Unit = {
for (i <- 1 to 5){
println(s"您的余额现在为:$x")
}
}
def main(args: Array[String]): Unit = {
eat()
println(balance())
printMoney(balance())
#printMoney(money) # 这样结果全部为900,因为没有调用eat() 方法
}
}
执行以上结果为:
900 # 因为在余额里面调用了一次eat() 方法,最后在主方法中又调用了一次eat();所以为1000-50*2
您的余额现在为:850
您的余额现在为:800
您的余额现在为:750
您的余额现在为:700
您的余额现在为:650
注意:函数式编程:方法的参数可以是一个函数
传值调用:
- 先计算balance的值
- 把这个值作为参数传递给printMoney
- 传名调用:传递的是函数 将balance方法的名称传递到方法内部执行
2.3 Scala的函数参数
2.3.1 可变参数函数
#java中的可变参数:用 ...
public class JavaTest {
//java中的可变参数
public static void m1(String ...args){
return;
}
public static void main(String[] args) {
m1("a");
m1("a","b","1");
}
}
# scala中的可变参数:用通配符 *
object Parms {
def sum(ints:Int*):Int = {
var sum = 0
for (v <- ints){
sum += v
}
sum
}
def setName(parms:Any*):Any = {
return parms
}
def main(args: Array[String]): Unit = {
println(sum(1,2))
println(sum(1,2,3,4))
println(setName("JustDoDT",18,180))
}
}
执行上面代码的结果为:
3
10
WrappedArray(JustDoDT, 18, 180)
2.3.2 默认参数函数
定义:将其他函数作为参数,或者其结果是函数的函数。
object DefaultParm {
/**
* 如果调用此方法就不给参数,要一个默认值
*/
def sum(a:Int = 3,b:Int = 7):Int = {
a + b
}
def main(args: Array[String]): Unit = {
//如果传递了参数,则使用传递的值;如果不传递参数,则使用默认值。
println(sum()) // 结果为10,没有传递参数
println(sum(2,4)) // 结果为6,传递了参数 ;使用了代名参数
}
}
2.3.3 代名参数
应用场景:当有多个默认参数的时候,通过代名参数可以确定是给哪一个参数赋值
scala> def func2(str:String="haha",name:String="Tom",age:Int=20)
| = str + name + age
func2: (str: String, name: String, age: Int)String
scala> func2() #直接调用,使用默认的参数
res4: String = hahaTom20
scala> func2(name="Mike")
res5: String = hahaMike20
2.3.3 函数参数的求值策略
- call by value 定义: :
对函数的实参求值,并且只求一次
- call by name 定义: : =>
函数的实参在函数体内部每次用到的时候,都会被求值
# call by value
scala> def test1(x:Int,y:Int):Int = x + x
test1: (x: Int, y: Int)Int
scala> test1(2+3,4)
res8: Int = 10
# 分析以上执行的步骤
1. test1(5,4)
2. 5+5
3. 10
# call by name
def test2(x: =>Int,y: =>Int):Int = x + x
test2(3+5,9)
res9: Int = 16
// 分析执行的步骤
1. (3+5)+(3+5)
2. 8 + (3+5)
3. 8+8
4. 16
# 一个更加复杂的例子
# 定义一个函数,接受2个参数,函数直接返回1;其中x是call by value,y是call by name
scala> def bar(x:Int,y: =>Int):Int = 1
bar: (x: Int, y: => Int)Int
scala> def loop():Int = loop
loop: ()Int
scala> bar(2,loop)
res10: Int = 1
scala> bar(loop,2) # 这次调用会出现死循环
2.5 部分参数应用函数
如果函数传递所有预期的函数,则表示完全应用它了。 如果只传递几个参数,并不是全部参数,那么将返回部分应用的函数。
2.6 字符串的格式化输出(插值操作)
文字插值器: f/s
scala> var s1:String = "Hello World"
s1: String = Hello World
# 字符串的插值操作:相当于拼加字符串
scala> "My name is Tom and ${s1}"
res1: String = My name is Tom and ${s1}
scala> s"My name is Tom and ${s1}"
res2: String = My name is Tom and Hello World
2.7 柯理化
指的是将原来接收的两个参数的函数变为一个新的接收一个参数的函数,这样的一个过程。 函数的通用性降低,但是适用性提高,在Spark源码中很常见。
scala> //柯里化
scala> //定义一个普通的函数
scala> def mul(x:Int,y:Int) = x*y
mul: (x: Int, y: Int)Int
scala> //柯里化函数
scala> def mul1(x:Int) = (y:Int) => x*y
mul1: (x: Int)Int => Int
scala> def mul2(x:Int)(y:Int) = x*y
mul2: (x: Int)(y: Int)Int
scala> mul(2,3)
res19: Int = 6
scala> mul1(2)(3)
res21: Int = 6
scala> mul2(2)(3)
res22: Int = 6
2.8 偏函数
被包在花括号内没有match的一组case语句的是一个偏函数。
PartialFunction[A,B] A:参数类型 B:返回类型 常用与模式匹配。
scala> val f: PartialFunction[Char, Int] = {
| case '+' => 1
| case '-' => -1
| }
f: PartialFunction[Char,Int] = <function1>
scala> println(f('-'))
-1
scala> println(f.isDefinedAt('0'))
false
scala> println(f('+'))
1
3. 循环
3.1 循环
object Demo1 {
def main(args: Array[String]): Unit = {
//for 循环
//定义一个集合
val list = List("Marry","Tom","Mike")
System.out.println("************for循环的第一种写法************")
for (x <- list) println(x)
// 注意:<- 表示Scala的提取符
System.out.println("************for循环的第二种写法************")
//加上一个判断条件,打印名字长度大于3的元素
for{
x <- list
if(x.length >3)
}println(x)
System.out.println("************for循环的第三种写法************")
//加上一个判断条件:打印名字长度小于等于3的元素
for (x <- list if x.length <= 3) println(x)
System.out.println("************for循环的第四种写法************")
//把list中的每个元素变成大写,返回一个新的集合
val newList = for {
x <- list
x1 = x.toUpperCase() //把名字全部改成大写
}yield x1
for (i <- newList) println(i)
System.out.println("************while写法************")
var i = 0
while (i < list.length){
println(list(i))
// 自增;注意,在scala中没有++或者--;
i += 1
}
System.out.println("************do....while写法************")
var j = 0
do{
println(list(j))
j += 1
}while(j < list.length)
//还可以使用foreach进行迭代,相当于循环
//也可以使用map函数
//foreach和map的区别:foreach没有返回值,map有返回值 -----Spark算子
System.out.println("************使用foreach************")
list.foreach(println)
}
}
执行以上代码的结果为:
************for循环的第一种写法************
Marry
Tom
Mike
************for循环的第二种写法************
Marry
Mike
************for循环的第三种写法************
Tom
************for循环的第四种写法************
MARRY
TOM
MIKE
************while写法************
Marry
Tom
Mike
************do....while写法************
Marry
Tom
Mike
************使用foreach************
Marry
Tom
Mike
3.2 . 懒值(lazy值)
常量如果是lazy的,他的初始化就会被推迟,推迟到第一次使用该常量的时候
铺垫:Spark的核心是RDD(数据集合),操作数据集合中的数据,需要使用算子(函数,方法)
- 算子有2种:
- Transformation : 延时加载,不会触发计算。
- Action : 会触发计算。
scala> val x = 10
x: Int = 10
scala> val y = x + 1
y: Int = 11
scala> //上面的特点是立即执行计算
scala> lazy val z:Int = x + 1
z: Int = <lazy>
scala> // 常量z 的初始化就被推迟了,没有触发计算。
scala> z
res6: Int = 11
# 更复杂一点儿的例子,读取文件
#(1)读取存在的文件
scala> val words = scala.io.Source.fromFile("E:/temp/students.txt").mkString
words: String =
1 Tom 23
2 Mary 26
3 Mike 24
4 Jone 21
scala> lazy val words = scala.io.Source.fromFile("E:/temp/students.txt").mkString
words: String = <lazy>
scala> words
res7: String =
1 Tom 23
2 Mary 26
3 Mike 24
4 Jone 21
# (2)读取不存在的文件
scala> lazy val words = scala.io.Source.fromFile("E:/temp/123").mkString
words: String = <lazy>
scala> words
java.io.FileNotFoundException: E:\temp\123 (系统找不到指定的文件。)
at java.io.FileInputStream.open0(Native Method)
at java.io.FileInputStream.open(FileInputStream.java:195)
at java.io.FileInputStream.<init>(FileInputStream.java:138)
at scala.io.Source$.fromFile(Source.scala:91)
at scala.io.Source$.fromFile(Source.scala:76)
at scala.io.Source$.fromFile(Source.scala:54)
at .words$lzycompute(<console>:11)
at .words(<console>:11)
... 32 elided
3.3 异常
Scala异常的工作机制和Java或者C++一样。直接使用throw关键字抛出异常。
scala> throw new Exception("Some Error Happened!")
java.lang.Exception: Some Error Happened!
... 32 elided
使用try …catch …finaly 来捕获和处理异常:
# 1.采用try catch finally来捕获异常和处理异常
try {
val words = scala.io.Source.fromFile("E:\\temp\\a.txt").mkString
}catch {
case ex:java.io.FileNotFoundException => {
println("File Not Found")
}
case ex:IllegalArgumentException => {
println("Illegal Argument Exception")
}
case _:Exception => {
println("******Others Exception ******")
}
}finally {
println("******final block****")
}
# 2. 如果一个函数的返回类型是Nothing,表示在函数执行的过程中产生了异常
scala> def func1 = throw new IllegalArgumentException("Some Error Happened")
func1: Nothing
# 3. if else 语句:如果在一个分支中产生了异常,则另一个分支的返回值,将作为if else 返回值的类型
val x = 10
if (x >= 0){
scala.math.sqrt(x)
}else{
throw new IllegalArgumentException("The value should be not")
}
res10: Double = 3.1622776601683795
4. 数组
4.1 定长数组:Array
scala> val a = new Array[Int](10)
a: Array[Int] = Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
scala> val b = new Array[String](5)
b: Array[String] = Array(null, null, null, null, null)
scala> val c = Array("Tom","Mary","Mike")
c: Array[String] = Array(Tom, Mary, Mike)
4.2 变长数组:ArrayBuffer
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> val d = ArrayBuffer[Int]()
d: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
scala> //往变长数组中添加元素
scala> d += 1
res11: d.type = ArrayBuffer(1)
scala> d += 2
res12: d.type = ArrayBuffer(1, 2)
scala> d += 3
res13: d.type = ArrayBuffer(1, 2, 3)
scala> //一次添加多个元素
scala> d += (10,20,30)
res14: d.type = ArrayBuffer(1, 2, 3, 10, 20, 30)
scala> //去掉第一个元素
scala> d.trimStart(1)
scala> d
res16: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 10, 20, 30)
#去掉最后一个元素
scala> d.trimEnd(1)
scala> d
res18: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 10, 20)
#截取字符串,和Python里面的strip类似
scala> var a = "mysql "
a: String = "mysql "
scala> a.trim()
res57: String = mysql
scala> a.stripSuffix("l")
res58: String = "mysql "
scala> a.stripSuffix("l ")
res59: String = "mysql "
scala> a.stripSuffix("l ")
res60: String = mysq
scala> a.stripPrefix("my")
res61: String = "sql "
4.3 遍历数组
scala> var a = Array("Tom","Mary","Mike")
a: Array[String] = Array(Tom, Mary, Mike)
scala> //使用for循环进行遍历
scala> for(s <- a) println(s)
Tom
Mary
Mike
scala> //对数组进行转换,生成一个新的数组 yield
scala> val b = for{
| s <- a
| s1 = s.toUpperCase
| }yield s1
b: Array[String] = Array(TOM, MARY, MIKE)
scala> //使用foreach进行循环输出
scala> a.foreach(println)
Tom
Mary
Mike
4.4 数组的常用操作
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> val myArray = Array(1,10,2,3,5,4)
myArray: Array[Int] = Array(1, 10, 2, 3, 5, 4)
scala> //求最大值
scala> myArray.max
res21: Int = 10
scala> //求最小值
scala> myArray.min
res23: Int = 1
scala> //求和
scala> myArray.sum
res27: Int = 25
# 降序
scala> myArray.sortWith(_ > _)
res28: Array[Int] = Array(10, 5, 4, 3, 2, 1)
scala> //升序
scala> myArray.sortWith(_ < _)
res29: Array[Int] = Array(1, 2, 3, 4, 5, 10)
#注意:
myArray.sortWith(_ > _) 的完整写法是
myArray.sortWith((a,b) => {if (a > b) true else false})
# 匿名函数:(a,b)=> {if(a>b) true else false} ----> 简写为: _ > _
# 把匿名函数作为了sortWith参数值,----> 把sortWith叫做高阶函数(Scala中的函数式编程)
4.5 多维数组
- Scala中的多维数组和Java一样,多维数组是通过数组的数组来实现的。
- 也可以创建不规则的数组,每一行的长度各不相同。
scala> //定义一个固定长度的二维数组
scala> val matrix = Array.ofDim[Int](3,4)
matrix: Array[Array[Int]] = Array(Array(0, 0, 0, 0), Array(0, 0, 0, 0), Array(0, 0, 0, 0))
scala> matrix(1)(2) = 10
scala> matrix
res31: Array[Array[Int]] = Array(Array(0, 0, 0, 0), Array(0, 0, 10, 0), Array(0, 0, 0, 0))
# 定义一个二维数组,其中每个元素是一个一维数组,其长度不固定
scala> val triangle = new Array[Array[Int]](10)
triangle: Array[Array[Int]] = Array(null, null, null, null, null, null, null, null, null, null)
scala> //通过一个循环赋值
scala> for(i <- 0 until triangle.length)
| triangle(i) = new Array[Int](i + 1)
scala> triangle
res33: Array[Array[Int]] = Array(Array(0), Array(0, 0), Array(0, 0, 0), Array(0, 0, 0, 0), Array(0, 0, 0, 0, 0), Array(0, 0, 0, 0, 0, 0), Array(0, 0, 0, 0, 0, 0, 0), Array(0, 0, 0, 0, 0, 0, 0, 0), Array(0, 0, 0, 0, 0, 0, 0, 0, 0), Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0))
4.6 映射
映射就是<Key Value>的对,用Map 来表示
scala> //创建一个Map(映射)
scala> val scores = Map("Tom"->80,"Mary"->85,"Mike"->82)
scores: scala.collection.immutable.Map[String,Int] = Map(Tom -> 80, Mary -> 85, Mike -> 82)
scala> //Scala中,映射有两种;1.不可变的Map 2.可变的Map
scala> //1.定义一个可变的Map,保存学生的语文成绩
scala> val chinese = scala.collection.mutable.Map(("Alice",80),("Bob",85),("Mary",90))
chinese: scala.collection.mutable.Map[String,Int] = Map(Bob -> 85, Alice -> 80, Mary -> 90)
scala> //也可以用最上面的 -> 这种来表示
scala> //1.获取映射中的值
scala> chinese("Bob")
res35: Int = 85
scala> chinese.get("Bob")
res36: Option[Int] = Some(85)
scala> //获取一个不存在的值
scala> chinese("Tom")
java.util.NoSuchElementException: key not found: Tom
at scala.collection.MapLike$class.default(MapLike.scala:228)
at scala.collection.AbstractMap.default(Map.scala:59)
at scala.collection.mutable.HashMap.apply(HashMap.scala:65)
... 32 elided
scala> //先判断一下Key是否存在 ,存在返回Tom对应的值,不存在则返回-1
scala> if (chinese.contains("Tom")){
| chinese("Tom")
| }else{
| -1
| }
res41: Int = -1
scala> //也可以简写为
scala> chinese.getOrElse("Tom",-1)
res42: Int = -1
scala> chinese.getOrElse("Bob",0)
res43: Int = 85
scala> //更新映射中的值:必须是可变的映射
scala> chinese("Bob")
res44: Int = 85
scala> chinese("Bob") = 100
scala> chinese.get("Bob")
res46: Option[Int] = Some(100)
scala> //如何进行迭代?类似数组;可以使用for,while,do...while,foreach
scala> for(s <- chinese)println(s)
(Bob,100)
(Alice,80)
(Mary,90)
scala> chinese.foreach(println)
(Bob,100)
(Alice,80)
(Mary,90)
4.7 元组:Tuple
- Tuple在Pig 中、在Storm、在Python中都有用到
- Scala中的Tuple是代表不同类型的集合
scala> //定义一个包含3个元素的tuple
scala> val t1 = (1,2,"Tom") # 方法一
t1: (Int, Int, String) = (1,2,Tom)
scala> val t1 = new Tuple3(1,2,"Tom") # 方法二
t1: (Int, Int, String) = (1,2,Tom)
# 注意:Tuple3 表示3个元素的Tuple;可以简写成方法一的形式。
scala> val t2 = Tuple2(2,"Hello")
t2: (Int, String) = (2,Hello)
scala> //访问Tuple2中的元素
scala> t2.
_1 canEqual equals invert productElement productPrefix toString zipped
_2 copy hashCode productArity productIterator swap x
scala> t2._1
res49: Int = 2
scala> t2._2
res50: String = Hello
scala> //遍历Tup中的元素;1.首先使用productIterator 2.再遍历
scala> t2.productIterator.foreach(println)
2
Hello
5. 面向对象
把数据及对数据的操作方法放在一起,作为一个相互依存的整体—–》对象。
面向对象的三大特征:
- 封装
- 继承
- 多态
(1)类的定义
简单类和无参方法:
class Counter{
private var value = 0
def increment() {value += 1}
def current() = value
}
注意:在class 前面没有public 关键字修饰。
//代表一个学生的信息
class Student1 {
//定义学生的属性
private var stuID:Int = 0
private var stuName:String = "Tom"
private var age:Int = 20
//定义成员方法(函数):get 和set
//定义名字和年龄的get和set
def getStuName():String = stuName
def setStuName(newName:String) = this.stuName = newName
def getStuAge():Int = age
def setStuAge(newAge:Int) = this.age = newAge
}
//测试Student1类,创建main函数(写到Object中)
//注意:object和class的名字可以不一样,如果一样了,这个object就叫做该class的伴生对象
object Student1{
def main(args: Array[String]): Unit = {
//创建学生对象
var s1 = new Student1
//第一次访问属性并输出
println(s1.getStuName()+"\t"+s1.getStuAge())
//访问set方法
s1.setStuName("Mary")
s1.setStuAge(22)
println(s1.getStuName()+"\t"+s1.getStuAge())
//再输出一次:直接访问私有的属性
println("*************直接访问私有的属性************")
println(s1.stuID +"\t"+ s1.stuName+"\t"+s1.age)
//注意:可以直接访问类的私有成员 为什么可以? ----> 属性的get和set方法
}
}
(2)属性的getter 和 setter 方法
-
当定义属性是private 时候,scala会自动为其生成对应的get 和 set 方法
-
private var stuName:String = "Tom" -
get 方法:
stuName——>s2.stuName()由于stuName是方法的名字,所以可以加上一个括号 -
set 方法:
stuName_ =——->stuName_=是方法的名字
-
-
定义属性:
private var money:Int = 1000希望money只有get 方法,没有 set 方法??- 方法:将其定义为常量
private val money:Int = 1000
- 方法:将其定义为常量
-
private[this]的用法:该属性只属于该对象私有,就不会生成对应的 set 和 get 方法。如果这样,就不能直接调用,例如:
s1.stuName—-> 错误
5.1 内部类(嵌套类)
我们可以在一个类的内部定义一个类,如下:我们在Student类中,再定义一个Course类用于保存学生选修的课程。
import scala.collection.mutable.ArrayBuffer
class Student3 {
//定义一个内部类:记录学生选修的课程信息
class Course(val courseName:String,val credit:Int) {
//定义其他方法,这里其实是定义了该类的主构造器
}
//属性
private var stuName:String = "Tom" //创建属性的时候定义默认值
private var stuAge:Int = 20
//定义一个ArrayBuffer记录该学生选修的所有课程
private var courseList = new ArrayBuffer[Course]()
//定义方法往学生信息中添加新的课程
def addNewCourse(cname:String,credit:Int): Unit ={
//创建新的课程
var c = new Course(cname,credit)
//将课程加入list
courseList += c
}
}
//测试
object Student3{
def main (args: Array[String] ): Unit = {
//创建学生对象
var s3 = new Student3
//给该学生添加新的课程
s3.addNewCourse("Chinese",2)
s3.addNewCourse("English",3)
s3.addNewCourse("Math",4)
//输出
println(s3.stuName+"\t"+s3.stuAge)
println("***************选修的课程********************")
for (s <- s3.courseList) println(s.courseName+"\t"+s.credit)
}
}
执行以上代码的结果为:
Tom 20
***************选修的课程********************
Chinese 2
English 3
Math 4
5.2 类的构造器
类的构造器分为:主构造器、辅助构造器
-
主构造器:和类的声明结合在一起,只能有一个主构造器
Student4(val stuName:String,val stuAge:Int) -
- 定义类的主构造器:两个参数
- 声明了两个属性:
stuName和stuAge和 对应的 get 和 set 方法
class Student4(val stuName:String,val stuAge:Int){
}
object Student4{
//创建Student4的一个对象
var s4 = new Student4("Tom",20) //调用了主构造器
println(s4.stuName+"\t"+s4.stuAge)
}
}
- 辅助构造器:可以有多个辅助构造器,通过关键字this来实现
class Student4(val stuName:String,val stuAge:Int){
//定义辅助构造器
def this(age:Int){
this("no name",age)
}
}
总的程序
class Student4(val stuName:String,val stuAge:Int){
//定义辅助构造器
def this(age:Int){
this("no name",age)
}
}
object Student4{
def main(args: Array[String]): Unit = {
//创建一个Student4的一个对象
var s4 = new Student4("Tom",20)
println(s4.stuName+"\t"+s4.stuAge)
//创建一个新的student4 的对象
var s42 = new Student4(24)
println(s42.stuName+"\t"+s42.stuAge)
}
}
执行以上代码的结果为:
Tom 20
no name 24
5.3 Scala 中的Object对象
- Object 对象,相当于Java 中的static
- Object中的内容都是静态的
- Scala中,没有静态修饰符static
- 如果class 的名字,跟object的名字一样,这时候就把这个object叫做类的伴生对象,该类叫做该object的伴生类。
- 使用object 实现单例模式:一个类只有一个对象;如果在Java中,构造器定义为private,提供getInstance方法
- Object内部的方法,我们可以直接通过 Object.method调用;类似于Java里面的static
//实现一个单例模式:自动生成卡号
object CreditCard {
//定义一个变量保存信用卡的卡号
private[this] var creditCardNumber:Long = 0
//定义函数来产生卡号
def generateCCNumber():Long = {
creditCardNumber += 1
//返回卡号
creditCardNumber
}
//测试程序
def main(args: Array[String]): Unit = {
//产生新的卡号
println(CreditCard.generateCCNumber())
println(CreditCard.generateCCNumber())
println(CreditCard.generateCCNumber())
println(CreditCard.generateCCNumber())
println(CreditCard.generateCCNumber())
}
}
执行上面的代码运行的结果为:
1
2
3
4
5
测试代码2
scala> object Timer {
|
| var count = 0
| def increment():Long = {
| count += 1
| count
| }
| }
defined object Timer
scala> Timer.increment
res14: Long = 1
scala> Timer.increment
res15: Long = 2
scala> Timer.increment
res16: Long = 3
- (2)使用
App对象:应用程序对象;好处是可以省略main方法
object HelloWorld extends App {
// override def main(args: Array[String]): Unit = {
// println("Hello World")
// }
//把main函数中的程序直接写到object中
println("Hello World")
//也可以直接通过args获取命令行的参数
if(args.length > 0){
println("有参数")
}else{
println("没有参数")
}
}
- 执行上面代码的运行的结果为:
Hello World
没有参数
5.4 Scala中的apply方法
遇到如下形式的表达式时,apply方法就会被调用:
Object(参数1,参数2,…….,参数N)
通常,这样一个apply方法返回的是伴生类的对象:其作用是为了省略new关键字
scala> //创建一个数组
scala> var myarray = Array(1,2,3)
myarray: Array[Int] = Array(1, 2, 3)
scala>//使用了apply方法;本质就是创建了一个Array对象,省略了new关键字
使用apply方法
//定义一个类
class Student3(var stuName:String)
object Student3 {
//定义Student3的apply方法
def apply(name:String)={
println("**********调用到了apply方法************")
new Student3(name) //调用到了主构造器
}
//测试程序
def main(args: Array[String]): Unit = {
//通过主构造器创建学生对象
var s1 = new Student3("Tom")
println(s1.stuName)
//通过apply方法创建学生对象
var s2 = Student3("Mary")
println(s2.stuName)
}
}
运行以上代码的结果为:
Tom
**********调用到了apply方法************
Mary
5.5 Scala中的继承
Scala和Java一样,使用extends关键字扩展类。
- 案例一:Employee类继承Person类
//继承1:父类 Person 人,子类 Employee 员工
//定义父类
class Person(val name:String,val age:Int){
//定义函数
def sayHello():String = "Hello" + name + "and the age is " + age
}
//定义子类
//override: 表示希望使用子类的值去覆盖父类中的值
class Employee(override val name:String,override val age:Int,val salary:Int) extends Person(name,age){
//在子类中,重写父类的函数
override def sayHello():String = "子类中的sayHello方法"
}
object Demo2 {
def main(args: Array[String]): Unit = {
//测试程序,创建一个Person对象
var p1 = new Person("Tom",20)
println(p1.name+"\t"+p1.age)
println(p1.sayHello())
//创建一个Employee的对象,可以使用子类对象
var p2:Person = new Employee("Mike",25,1000)
println(p2.sayHello())
//通过匿名子类实现继承:没有名字的子类
var p3:Person = new Person("Mary",25){
//在匿名子类中重写sayHello方法
override def sayHello():String = "匿名子类中的sayHello方法"
}
println(p3.sayHello())
}
}
执行上面代码的结果为:
Tom 20
HelloTomand the age is 20
子类中的sayHello方法
匿名子类中的sayHello方法
- 使用抽象类。抽象类中的包含抽象方法,抽象类只能用来继承。
//Scala中的抽象类
//父类:抽象类
abstract class Vehicle{
//定义抽象方法
def checkType():String
}
//子类
class Car extends Vehicle{
//实现checkType方法
def checkType():String = {"I am a car"}
}
class Bysical extends Vehicle{
//实现checkType方法
def checkType():String = {"I am a bike"}
}
object Demo2 {
def main(args: Array[String]): Unit = {
//定义两个交通工具
val v1:Vehicle = new Car
println(v1.checkType())
val v2: Bysical = new Bysical
println(v2.checkType())
}
}
执行以上代码的结果为:
I am a car
I am a bike
- 使用抽象字段。抽象字段就是一个没有初始值的字段
//抽象的父类
abstract class Person{
//第一个抽象的字段,并且只有get方法
val id:Int
//另一个抽象的字段,并且有get和set方法
var name:String
}
//如果子类中没有提供父类中抽象字段的初始值,这个子类也要申明成抽象的,否则编译会出错。
//子类:应该提供抽象字段的初始值,否则该子类也应该是抽象的
abstract class Employee1 extends Person{
var name:String = "No Name"
}
//还有一个办法:我们可以定义一个主构造器,接收一个id参数,注意名字要与父类中的名字一样。
class Employee2(val id:Int) extends Person{
//只提供了name的初始值
var name:String = "No Name"
}
object Demo2{
}
5.6 Scala中的trait(特质)
trait就是抽象类。trait跟抽象类最大的区别:trait支持多重继承。
//第一个trait
trait Human{
//抽象的字段
val id:Int
val name:String
//方法
def sayHello():String = "Hello " + name
}
//第二个trait
trait Actions{
//抽象的方法
def getActionNames():String
}
//子类
class Student(val id:Int,val name:String) extends Human with Actions{
override def getActionNames(): String = "Action is running"
}
object Demo2{
//测试程序
def main(args: Array[String]): Unit = {
//创建一个student的对象
var s1 = new Student(1,"Tom")
println(s1.sayHello())
println(s1.getActionNames())
}
}
执行以上代码的结果为:
Hello Tom
Action is running
5.7 包对象
包可以包含类、对象和特质,但不能包含函数或者变量的定义。很不幸,这是Java虚拟机的局限。
把工具函数或者常量添加到包而不是某个Utils对象,这是更加合理的做法。Scala中,包对象的出现正是为了解决这个局限。
Scala中的包对象:常量、变量、方法、类、对象、trait(特质)
/**
* Scala中的包对象:常量、变量、方法、类、对象、trait(特质)
*/
package class4
//定义一个包对象
package object MyPackageObject{
//常量
val x:Int = 0
//变量
var y:String = "Hello World"
//方法
def sayHelloWorld():String = "Hello World"
//类
class MyTestClass{
}
//对象object
object MyTestObject{
}
//trait 特质
trait MyTestTrait{
}
class Demo3{
//测试
def method() = {
//导入需要的包对象
import class4.MyPackageObject._
//定义MyTestClass的一个对象
var a = new MyTestClass
}
}
}
5.8 Scala中的文件访问
- 读取行
scala> val source = scala.io.Source.fromFile("E:\\temp\\b.txt")
source: scala.io.BufferedSource = non-empty iterator
scala> //1.将整个文件作为一个字符串
scala> println(source.mkString)
abcde
123
scala> //2.将文件中的每一行读入
scala> val lines = source.getLines()
lines: Iterator[String] = non-empty iterator
scala> for (a <- lines) println(a.toString)
abcde
123
- 读取字符
scala> //读取字符
scala> val source = scala.io.Source.fromFile("E:\\temp\\b.txt")
source: scala.io.BufferedSource = non-empty iterator
scala> for(b <- source) println(b)
a
b
c
d
e
1
2
3
其实这里的source就指向了这个文件中的每个字符。
- 从URL或其他源读取:注意指定字符集UTF-8 (百度网站)
scala> val source = scala.io.Source.fromURL("http://www.baidu.com","UTF-8")
source: scala.io.BufferedSource = non-empty iterator
scala> println(source.mkString)
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA- Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
- 读取二进制文件:Scala中并不支持直接读取二进制,但是可以通过调用Java的
InputStream来进行读入。
//读取二进制文件:Scala并不支持直接读取二进制文件
var file = new File("d:\\temp\\testds.war")
//构造一个InputStream
val in = new FileInputStream(file)
//构造一个buffer
val buffer = new Array[Byte](file.length().toInt)
//读取
in.read(buffer)
//关闭
in.close()
- 写入文本文件
import java.io.PrintWriter
val out = new PrintWriter("E:\\temp\\a.txt")
for (i <- 1 to 10) out.println(i)
out.close()
-
- 执行上面代码运行的结果为:
1
2
3
4
5
6
7
8
9
10
6. Scala的函数式编程
6.1 Scala中的函数
在Scala中,函数是“头等公民”,就和数字一样。可以在变量中存放函数,即:将函数作为变量的值(值函数)
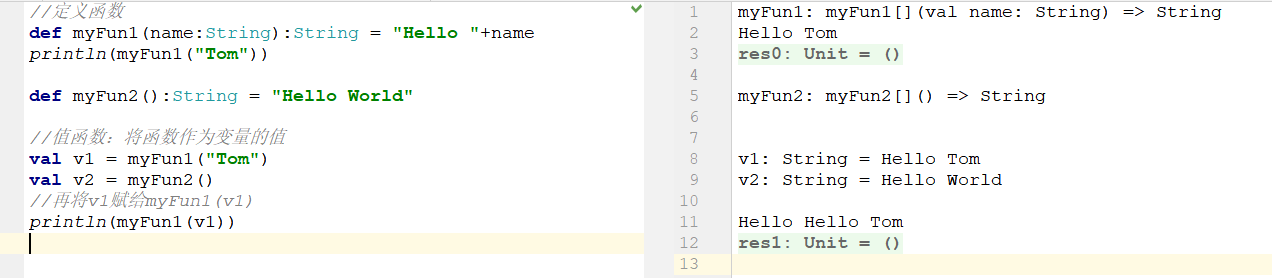
6.2 匿名函数

函数赋值给变量
scala> def sayHello(name:String):Unit={
| println("Hello " + name)
| }
sayHello: (name: String)Unit
scala> // 函数赋值给变量
scala> val sayHelloFunc = sayHello _
sayHelloFunc: String => Unit = $$Lambda$1163/1868931587@1d0b447b
scala> sayHelloFunc("JustDoDT")
Hello JustDoDT
匿名函数
(参数名:参数类型)=> 函数体
匿名函数赋值给变量
scala> (x:Int) => x+1
res2: Int => Int = $$Lambda$1168/1672524765@397dfbe8
scala> x:Int => x+1
<console>:1: error: ';' expected but '=>' found.
x:Int => x+1
^
scala> {x:Int => x+1}
res3: Int => Int = $$Lambda$1171/959378687@6ed7c178
scala> val a = (x:Int) => x+1
a: Int => Int = $$Lambda$1172/1018394275@7022fb5c
scala> a(2)
res4: Int = 3
scala> val b = {x:Int => x+1}
b: Int => Int = $$Lambda$1181/1454795974@6f076c53
scala> b(5)
res5: Int = 6
匿名函数赋值给函数
scala> def sum = (x:Int,y:Int)=>x+y
sum: (Int, Int) => Int
scala> sum(2,3)
res6: Int = 5
6.3 带函数参数的函数,即:高阶函数
示例1:
- 首先,定义一个最普通的函数

- 再定义一个高阶函数

- 分析这个高阶函数调用的过程

式例2:

在这个例子中,首先定义一个普通的函数mytest,然后定义一个高阶函数myFunction;myFunction接收3个参数:第一个f是函数参数,第二个是x,第三个是y。而f是一个函数参数,本身接收两个Int的参数,返回一个Int的值。
6.4 闭包
闭包就是函数的嵌套,即:在一个函数定义中,包含另外一个函数的定义;并且在内函数中可以访问外函数中的变量。

测试上面的函数

6.5 高阶函数示例

- 示例1:map
scala> //map
scala> //在列表中的每个元素上计算一个函数,并且返回一个包含相同数目元素的列表。
scala> val numbers = List(1,2,3,4,5,6,7,8,9,10)
numbers: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> numbers.map((i:Int) => i * 3)
res3: List[Int] = List(3, 6, 9, 12, 15, 18, 21, 24, 27, 30)
- 示例2:foreach
scala> //foreach和map相似,只不过它没有返回值,foreach只要是为了对参数进行作用
scala> val numbers = List(1,2,3,4,5,6,7,9,10)
numbers: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 9, 10)
scala> numbers.foreach((i:Int) => i * 2)
- 示例3:filter
scala> //移除任何使得传入的函数返回false的元素。
scala> val numbers = List(1,2,3,4,5,6,7,9,10)
numbers: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 9, 10)
scala> numbers.filter((i:Int) => i %2 ==0)
res5: List[Int] = List(2, 4, 6, 10)
- 示例4:zip
scala> //zip把两个列表的元素合成一个由元素对组成的列表里。
scala> List(1,2,3).zip(List(4,5,6))
res6: List[(Int, Int)] = List((1,4), (2,5), (3,6))
- 示例5:partition
scala> partition根据断言函数的返回值对列表进行拆分。
scala> numbers.partition((i:Int) => i%2 ==0)
res7: (List[Int], List[Int]) = (List(2, 4, 6, 10),List(1, 3, 5, 7, 9))
//在这个例子中,可以被2整除的被分到一个分区;不能被2整除的被分到另一个分区。
- 示例6:find
scala> find返回集合里面第一个匹配断言函数的元素。
scala> numbers.find(_ % 3 ==0)
res8: Option[Int] = Some(3)
- 示例7:flatten
scala> //flatten可以把嵌套的结构展开
scala> List(List(1,2,3),List(4,5,6)).flatten
res9: List[Int] = List(1, 2, 3, 4, 5, 6)
- 示例8:
flatMap
scala> //flatMap是把一个常用的combinator,它结合了map和flatten的功能。
scala> val myList = List(List(1,2,3),List(4,5,6))
myList: List[List[Int]] = List(List(1, 2, 3), List(4, 5, 6))
scala> myList.flatMap(x => x.map(_ * 2))
res10: List[Int] = List(2, 4, 6, 8, 10, 12)
//在这个例子中,分为两步操作:
//(1)将(1,2,3)和(4,5,6)这两个集合合并为一个集合。
//(2)再对每个元素乘以2
7. Scala中的集合
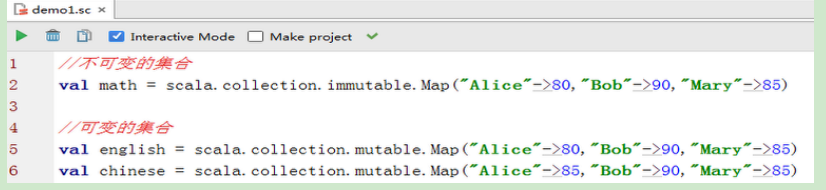
7.1 可变集合和不可变集合
-
可变集合
-
不可变集合:
-
-
集合从不改变,因此可以安全地共享其引用。
-
甚至是在一个多线程的应用程序当中也没有问题。
-
- 集合操作

7.2 列表
- 不可变列表(List)
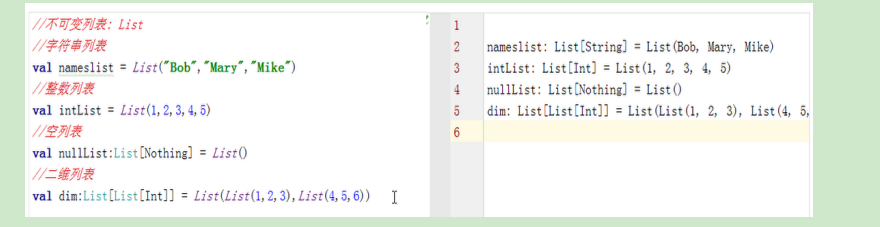
- 不可变列表的相关操作:

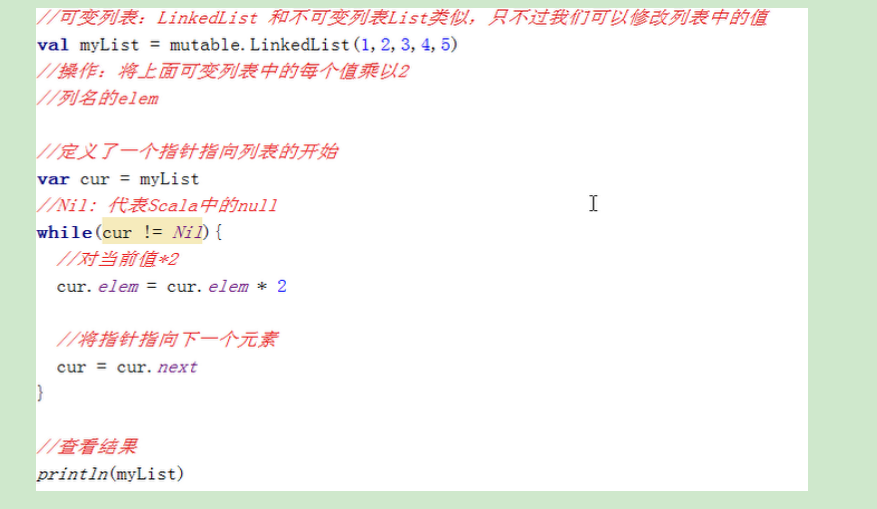
- 可变列表(
LinkedList):scala.collection.mutable
7.3 序列
常用的序列有:Vector和Range
- Vector是
ArrayBuffer的不可变版本,是一个带下标的序列。

- Range表示一个整数序列
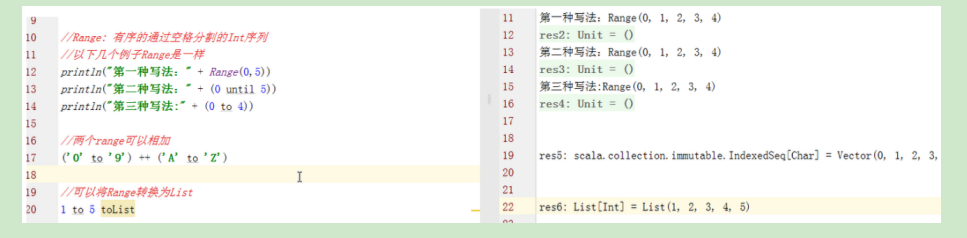
7.4 集(Set)和集的操作
- 集合Set是不重复元素的集合
- 和列表不同,集合并不保留元素插入的顺序。默认以Hash集合实现
示例1:创建集
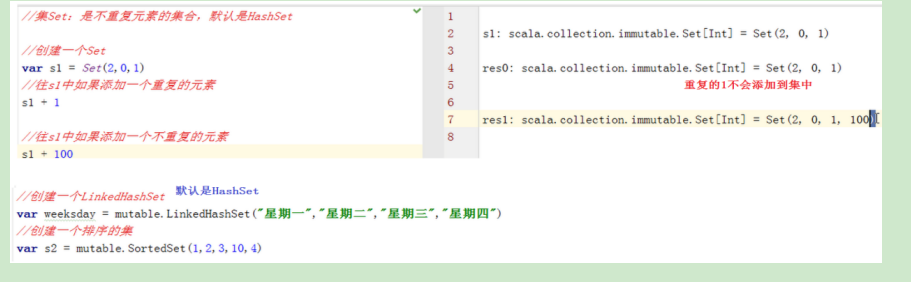
示例2:集合的操作

7.5 模式匹配
Scala有一个强大的模式匹配机制,可以应用在很多场合:
- switch语句
- 类型检查
Scala还提供了样本类(case class),对模式匹配进行了优化
模式匹配示例:
- 更好的switch

- Scala的守卫

- 模式匹配中的变量

- 类型匹配

- 匹配数组

- 匹配列表

7.6 样本类(Case Class)
简单的来说,Scala的case class 就是在普通的类定义前加case这个关键字,然后你可以对这些类来模式匹配。
case class 带来的最大好处是它们支持模式识别。
首先,回顾一下前面的模式匹配:

其次,如果我们想判断一个对象是否是某个类的对象,跟Java一样可以使用isInstanceOf

- 用case class
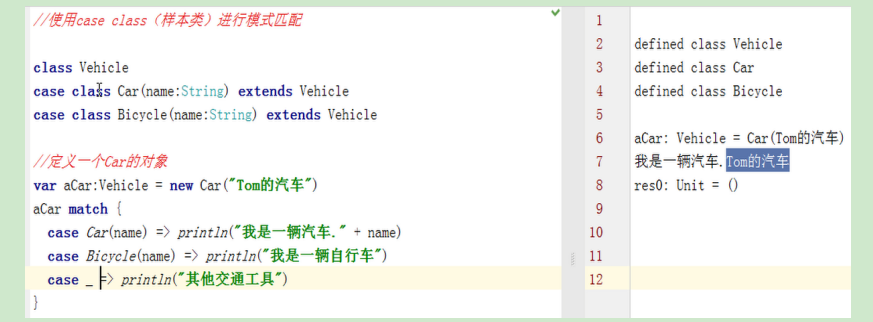
注意:需要在class 前面使用case 关键字
8. Scala语言的高级特性
8.1 什么是泛型类
和Java或者C++一样,类和特质可以带类型参数。在Scala中,使用方括号来定义类型参数

- 测试程序
//测试程序
object GenericClass{
def main(args: Array[String]): Unit = {
//定义一个Int整数类型的泛型类对象
var intGeneric = new GenericClass[Int]
intGeneric.set(123)
println("得到的值为:"+intGeneric.get())
//定义一个String类型的泛型类对象
var stringGeneric = new GenericClass[String]
stringGeneric.set("Hello Scala")
println("得到的值为:"+stringGeneric.get())
}
}
- 运行的结果为:
得到的值为:123
得到的值为:Hello Scala
8.2 什么是泛型函数
函数和方法也可以带类型参数。和泛型类一样,我们需要把类型参数放在方法名之后。
注意:这里的ClassTag是必须的,表示运行时的一些信息,比如类型。
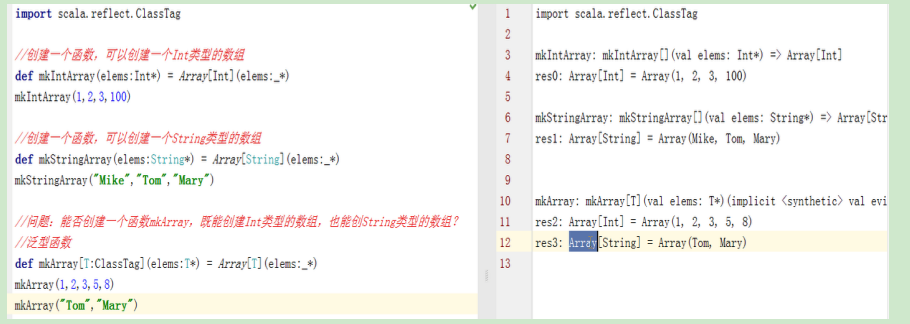
8.3 Upper Bounds 与 Lower Bounds
类型的上界和下界,是用来定义类型变量的范围。它们的含义如下:
-
S <:T
-
- 这是类型上界的定义。也就是S必须是类型T的子类(或本身,自己也可以认为是自己的子类)
-
U >: T
这是类型下界的定义。也就是U必须是类型T的父类(或本身,自己也可以认为是自己的父类)。
- 一个简单的例子:
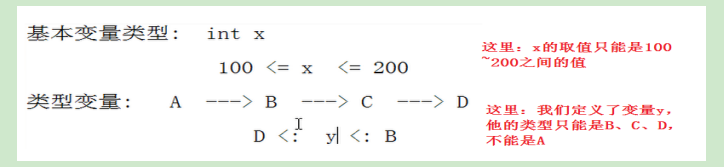
一个复杂一点的例子(上界):

- 执行上面代码运行的结果为:
Driving
Car Driving
例子2:

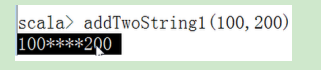
8.4 视图界定(View bounds)
它比 <: 适用的范围更广,除了所有的子类型,还允许隐式转换过去的类型。用 <% 表示。尽量使用视图界定,来取代泛型的上界,因为适用的范围更加广泛。
示例:
- 上面写过的一个列子。这里由于T的上界是String,当我们传递100和200的时候,就会出现类型不匹配。

- 但是100和200是可以转成字符串的,所以我们可以使用视图界定让
addTwoString方法接收更广泛的数据类型,即:字符串及其子类,可以转换成字符串的类型。
注意:使用的是 <%

但实际运行的时候,会出现错误

这是因为:Scala并没有定义如何将Int转换成String的规则,所以要使用视图界定,我们就必须创建转换的规则。
创建转换规则

运行成功
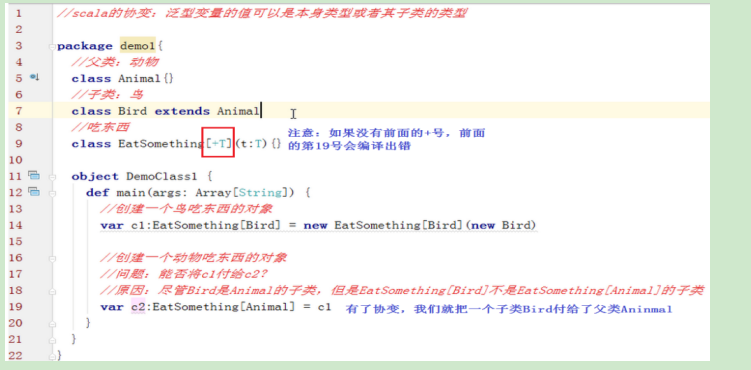
8.5 协变和逆变
- 协变:
Scala的类型或特征的泛型定义中,如果在类型参数前面加入 +符号 ,就可以使类或特征变为协变了。
- 逆变
在类或特征的定义中,在类型参数之前加上一个 -符号 ,就可定义逆变泛型类和特征了。
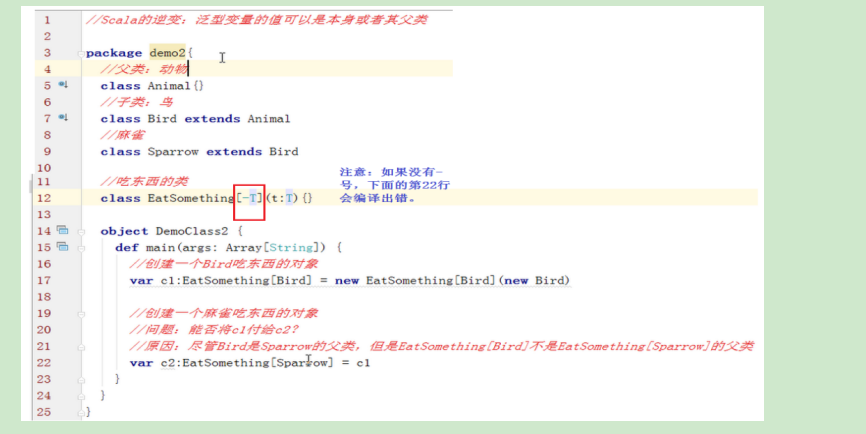
总结一下:
- Scala的协变:泛型变量的值可以是
本身类型或者其子类的类型。即可以把子类赋给父类 - Scala的逆变:泛型变量的值可以是
本身类型或者其父类的类型。即可以把父类赋给子类
8.6 隐式转换函数
隐士: 偷偷摸摸的 目的:悄悄的为一个类的方法进行增强 Man ===> Superman 在Java中可以用Proxy来实现 例子1
object ImplicitApp {
def main(args: Array[String]): Unit = {
//定义隐士转换
implicit def man2superman(man:Man):Superman = new Superman(man.name)
val man = new Man("JustDoDT")
man.fly()
}
}
class Man(val name:String){
def eat():Unit={
println("Man eat")
}
}
class Superman(val name:String){
def fly():Unit ={
println(s"$name fly")
}
}
运行结果为:
JustDoDT fly
例子2:
import java.io.File
import scala.io.Source
object ImplicitApp {
def main(args: Array[String]): Unit = {
implicit def file2RichFile(file:File):RichFile = new RichFile(file)
val file = new File("E:/temp/students.txt")
val context = file.read()
println(context)
}
}
class RichFile(val file:File){
def read() = Source.fromFile(file.getPath).mkString
}
运行结果
1 Tom 23
2 Mary 26
3 Mike 24
4 Jone 21
在工作中可以把封装一下所有经常要用到的隐士转换
import java.io.File
object ImplicitAspect {
implicit def man2superman(a:Man):Superman = new Superman(a.name)
implicit def file2RichFile(haha:File):RichFile = new RichFile(haha)
}
直接调用
import java.io.File
import scala.io.Source
import ImplicitAspect._
object ImplicitApp {
def main(args: Array[String]): Unit = {
val man = new Man("JustDoDT")
man.fly()
val file = new File("E:/temp/students.txt")
val context = file.read()
println(context)
}
}
class RichFile(val file:File){
def read() = Source.fromFile(file.getPath).mkString
}
class Man(val name:String){
def eat():Unit={
println("Man eat")
}
}
class Superman(val name:String){
def fly():Unit ={
println(s"$name fly")
}
}
所谓隐式转换函数指的是以implicit关键字申明的带有单个参数的函数。
- 前面讲视图界定时候的一个例子:

- 再来一个例子:我们把Fruit对象转换成了Monkey对象
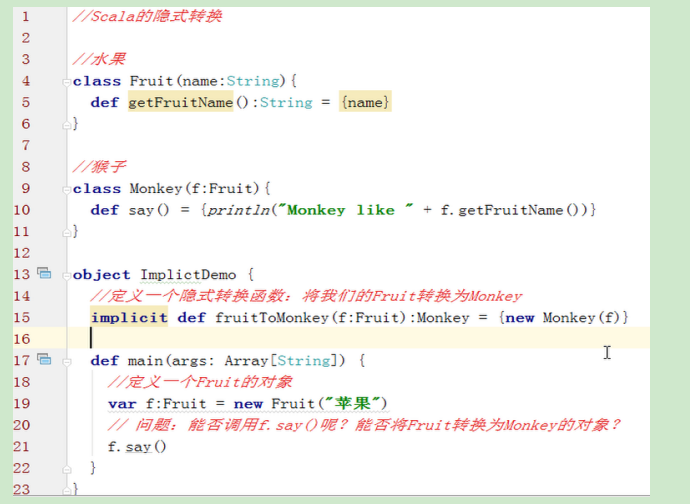
8.7 隐式参数
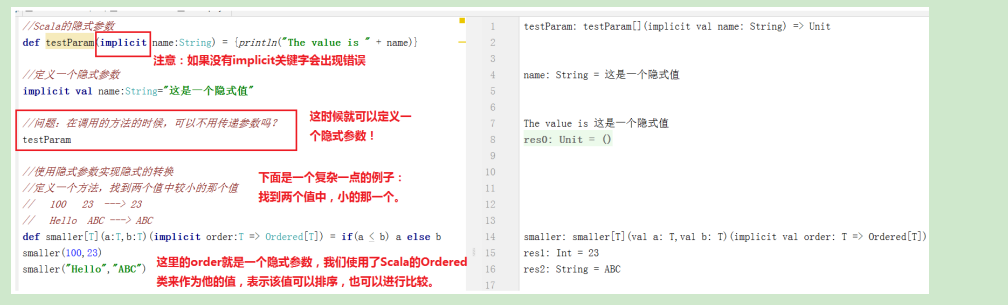
使用implicit申明的函数参数叫做隐式参数。我们也可以使用隐式参数实现隐式的转换
8.8 隐式类
所谓隐式类:就是对类增加**implict限定的类,其作用主要是对类的功能加强

- 运行以上代码的结果为:
两个数字的和:4
9. 并发编程模型AKKA
Spark 使用底层的通信框架AKKA
- 分布式
- master
- worker
Hadoop使用的是rpc
akka简介
写并发程序很难的,AKKA解决Spark这个问题。akka构建在JVM平台上,是一种高并发、分布式、并且容错的应用工具包。akka用Scala语言编写,同时还提供了scala和java的开发接口,akka可以开发一些高并发的程序。
Akka的Actor模型
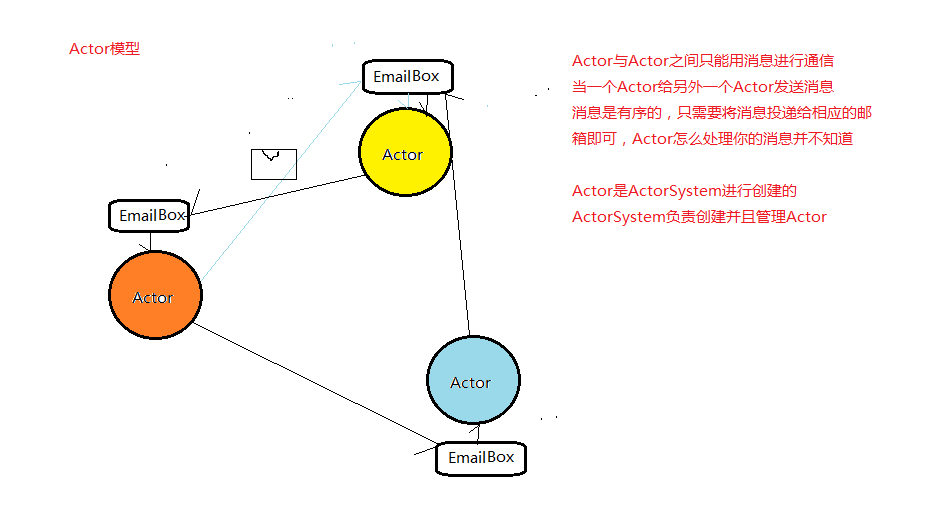
- Akka处理并发的方法是基于actor模型
- 在基于actor的系统中,所有事物都是actor。
- actor作为一个并发模型设计和架构的,面向对象则不是这样。
- actor与actor之间只能通过消息通信。
AKka的特点
- 对并发模型进行了更高的抽象
- 异步,非阻塞、高性能的事件驱动编程模型
- 轻量级事件处理(
1G内存可以容纳百万级别的Actor)
啥是同步?阻塞(发消息一直等待消息)
啥是异步?不阻塞(发消息,不等待,该干嘛干嘛)
Actor的工作机制
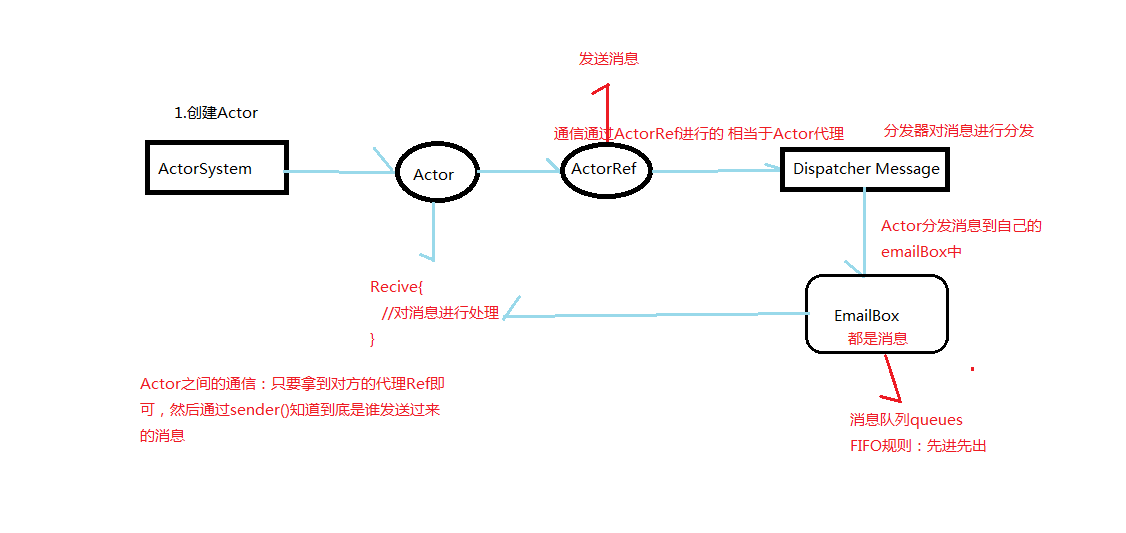
Actor模型
示例1:
import akka.actor.{Actor, ActorSystem, Props}
object CallMe {
//1.创建ActorSystem 用ActorSystem创建Actor
private val acFactor = ActorSystem("AcFactor")
//2.Actor发送消息通过ActorRef
private val callRef = acFactor.actorOf(Props[CallMe],"CallMe")
def main(args: Array[String]): Unit = {
//3.发送消息
callRef ! "Haha很帅"
callRef ! "Haha不帅"
callRef ! "stop"
}
}
class CallMe extends Actor{
//Receive用户接受消息并且处理消息
override def receive:Receive = {
case "Haha很帅" => println("你是对的")
case "Haha不帅" => println("你是错的")
case "stop" => {
//关闭代理ActorRef
context.stop(self)
//关闭ActorSystem
context.system.terminate()
}
}
}
- 执行上面代码的结果为:
你是对的
你是错的