1. Spark运行架构
1.1 基本概念和架构设计
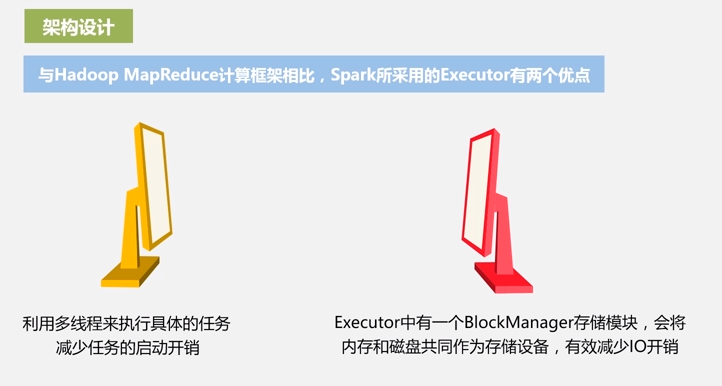
BlockManager存储模块,当内存不够的时候才会写磁盘,有效的减少了IO开销。
1.2 Spark 中各种概念之间的相互关系
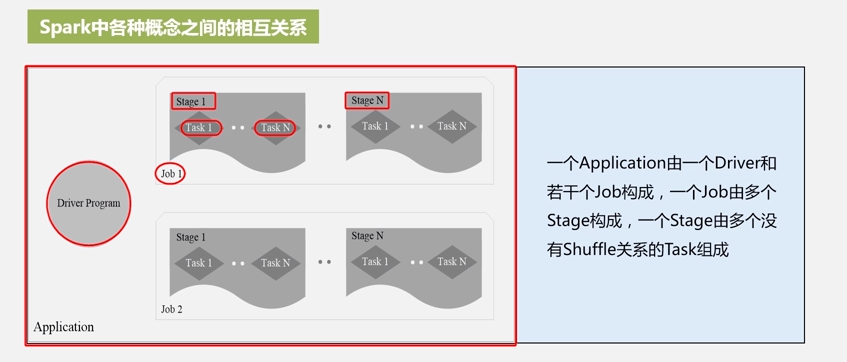
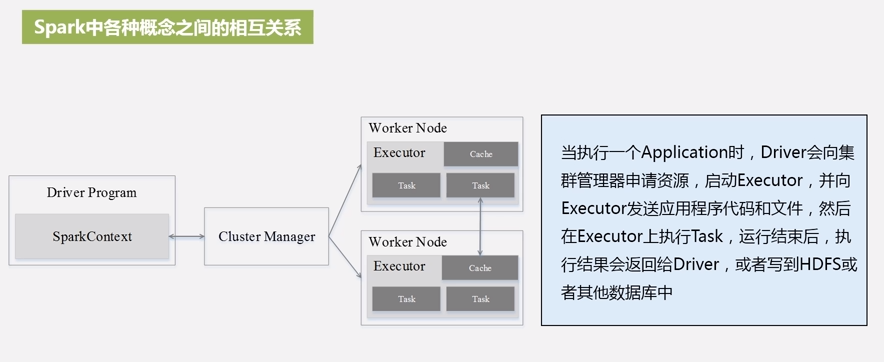
1.3 Spark 架构图说明
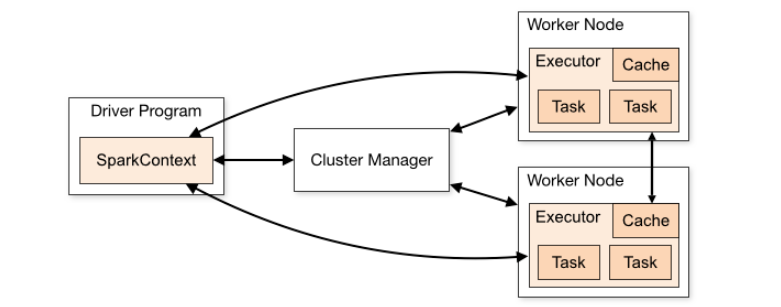
查看官网
| Term | Meaning |
|---|---|
Application |
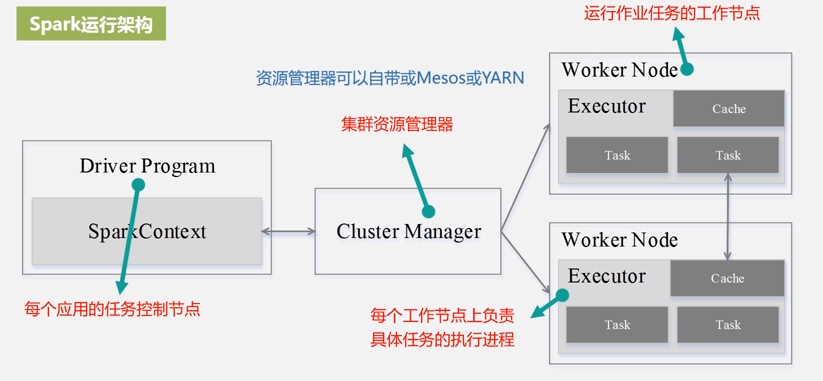
User program built on Spark. Consists of a driver program and executors on the cluster。(用户程序构建在Spark上。她包含一个driver program 和 多个executors在集群中。) |
Driver program |
The process running the main() function of the application and creating the SparkContext。(她是一个运行Application的main()方法和创建SparkContext对象的进程) |
Cluster manager |
An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN) (她是一个用于获取集群资源的外部服务;因为Spark可以运行在local,standalone,yarn,k8s上) |
Deploy mode |
Distinguishes where the driver process runs. In “cluster” mode, the framework launches the driver inside of the cluster. In “client” mode, the submitter launches the driver outside of the cluster. (区分diver运行的方式;以client模式的时候,运行在local上;以cluster模式的时候,表示运行在cluster模式;默认以local模式) |
Worker node |
Any node that can run application code in the cluster。相当于yarn中的node manager |
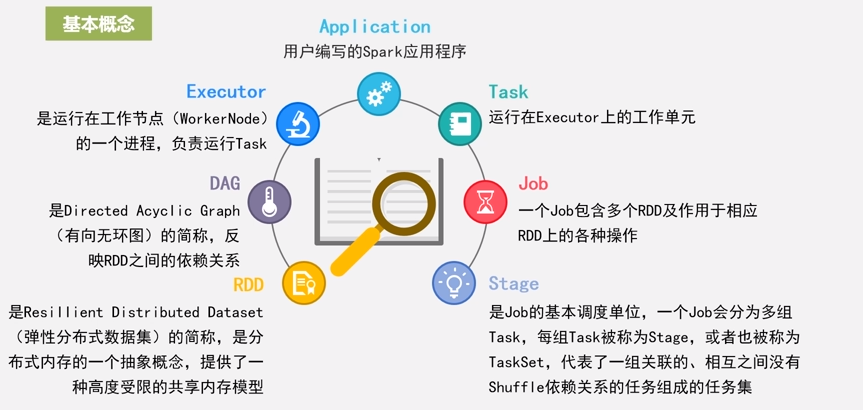
Executor |
A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. (她是worker node的一个应用程序,运行tasks;每个应用程序有自己的executors。在worker node中,运行task任务;如果spark运行在yarn上,则表示为container) |
Task |
A unit of work that will be sent to one executor。(一个work的基本单元,将分送到executor执行。) |
Job |
A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs. (由多个任务组成的并行计算,这些任务是为了响应Spark动作而产生的(例如,保存,收集); 你会在驱动程序的日志中看到这个术语;RDD的action算子会触发Job) |
Stage |
Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs. (每个作业被分成较小的任务集合,称为阶段,彼此依赖(类似于MapReduce中的map和reduce阶段); 你会在驱动程序的日志中看到这个术语。遇到Shuffle类的算子会拆分Stage) |
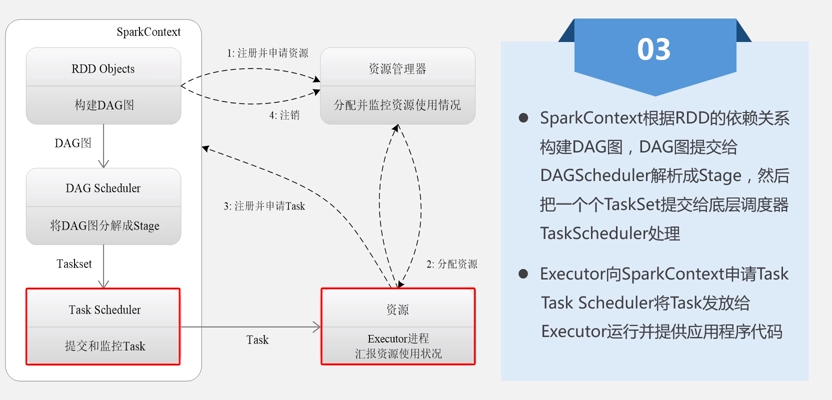
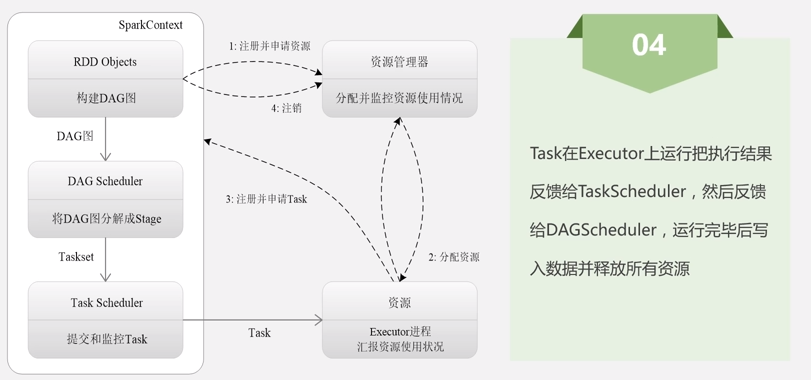
2.1 Spark运行基本流程
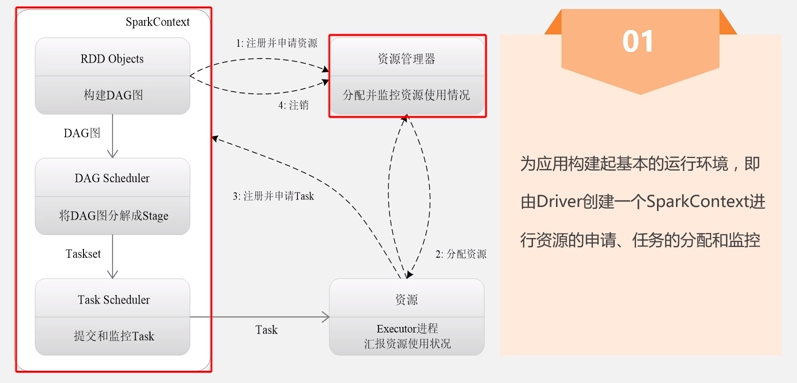
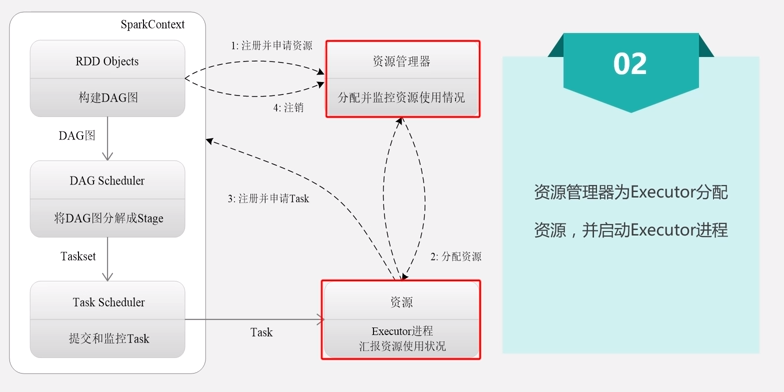
2.2 Spark运行架构特点:
①每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。
②Spark任务与cluster manager无关,只要能够获取executor进程,并能保持相互通信就可以了。
③提交SparkContext的Client应该靠近worker nodes(运行Executor的节点),最好是在同一个Rack里,因为Spark程序运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。Task采用了数据本地性和推测执行的优化机制。
④driver program必须在其生命周期内监听并接受来自其executors的传入连接(例如,请参阅网络配置部分中的spark.driver.port)。 因此,driver program必须和worker nodes保持网络通信。