1. 概述
Yarn 是一种统一的资源管理机制,在其上面可以运行多套计算框架。目前的大数据技术世界,大多数公司除了使用Spark来进行数据计算,由于历史原因或者单方面业务处理的性能考虑而使用着其他的计算框架,比如MapReduce、Storm等计算框架。Spark基于此种情况开发了Spark on YARN的运行模式,由于借助了YARN良好的弹性资源管理机制,不仅部署Application更加方便,而且用户在YARN集群中运行的服务和Application的资源也完全隔离,更具实践应用价值的是YARN可以通过队列的方式,管理同时运行在集群中的多个服务。
具体可以参考博客:Yarn概述及其原理
注意:Spark 仅仅只是一个客户端而已,可以提交作业到YARN上,K8S等
Spark on YARN Overview
MR: base-process
each task in its own process: MapTask Reduce Task
when a task completes,the process goes away
Spark: base thread
many tasks can run concurrently in a single process
this process sticks around for the lifetime of the Spark Application even no jobs are running
Advantage:
speed
tasks can start up very quickly
in-memory
Cluster Manager
Spark Application ===> Cluster Manager
Local standalone YARN Mesos K8S ===> Pluggable(可插拔)
ApplicationMaster:AM
YARN Application ===> AM(first container)
Worker
在YARN中没有;executor runs in container(memory of container > executor memory)2. YARN-Client
Yarn-Client模式中,Driver在客户端本地运行,这种模式可以使得Spark Application和客户端进行交互,因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://hadoop1:4040访问,而YARN通过http:// hadoop1:8088访问。
YARN-client的工作流程分为以下几个步骤:
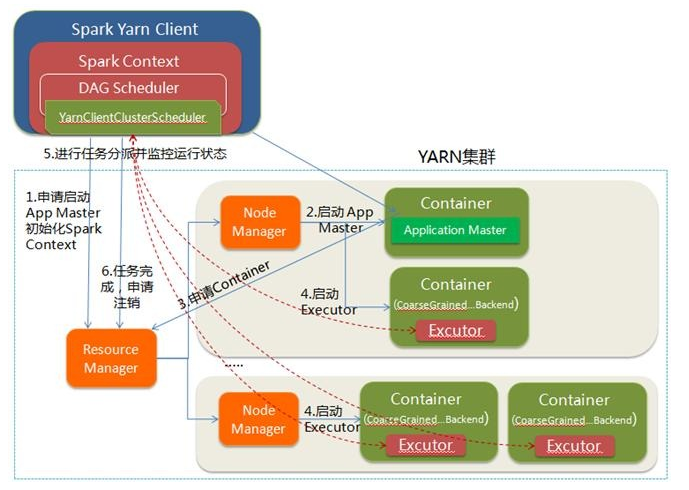
1.Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
2.ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
3.Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5.Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6.应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
3. YARN-Cluster
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分为两个阶段运行该应用程序:
- 第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN中先启动
- 第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成。
YARN-cluster的工作流程分为以下几个步骤:
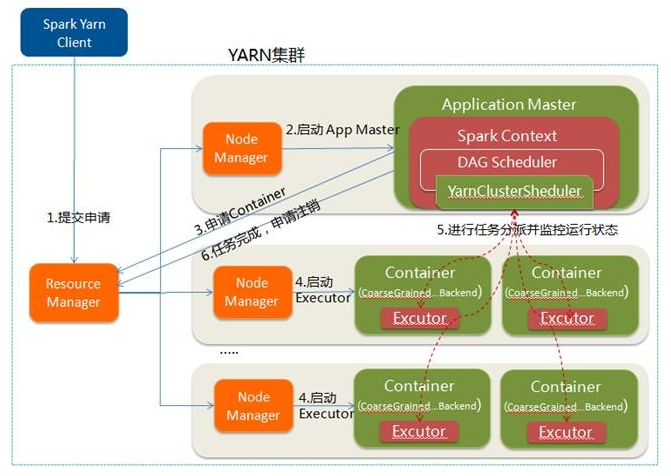
-
Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
-
ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
-
ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
-
一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
-
ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
-
应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
4. YARN-Client 与 YARN-Cluster 的区别
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业;
YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。
官网对于YARN-Clent 与 YARN-Cluster的描述
In cluster mode, the Spark driver runs inside an application master process which is managed by YARN on the cluster, and the client can go away after initiating the application. In client mode, the driver runs in the client process, and the application master is only used for requesting resources from YARN.
Spark on Yarn 用Client模式
[hadoop@hadoop001 ~]$ spark-shell --master yarn
Exception in thread "main" org.apache.spark.SparkException: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
at org.apache.spark.deploy.SparkSubmitArguments.error(SparkSubmitArguments.scala:657)
at org.apache.spark.deploy.SparkSubmitArguments.validateSubmitArguments(SparkSubmitArguments.scala:290)
at org.apache.spark.deploy.SparkSubmitArguments.validateArguments(SparkSubmitArguments.scala:251)
at org.apache.spark.deploy.SparkSubmitArguments.<init>(SparkSubmitArguments.scala:120)
at org.apache.spark.deploy.SparkSubmit$$anon$2$$anon$1.<init>(SparkSubmit.scala:911)
at org.apache.spark.deploy.SparkSubmit$$anon$2.parseArguments(SparkSubmit.scala:911)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:81)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
[hadoop@hadoop001 ~]$
[hadoop@hadoop001 ~]$ export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/
[hadoop@hadoop001 ~]$ spark-shell --master yarn
19/04/18 20:12:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
19/04/18 20:13:10 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
Spark context Web UI available at http://hadoop001:4040
Spark context available as 'sc' (master = yarn, app id = application_1555235291975_0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
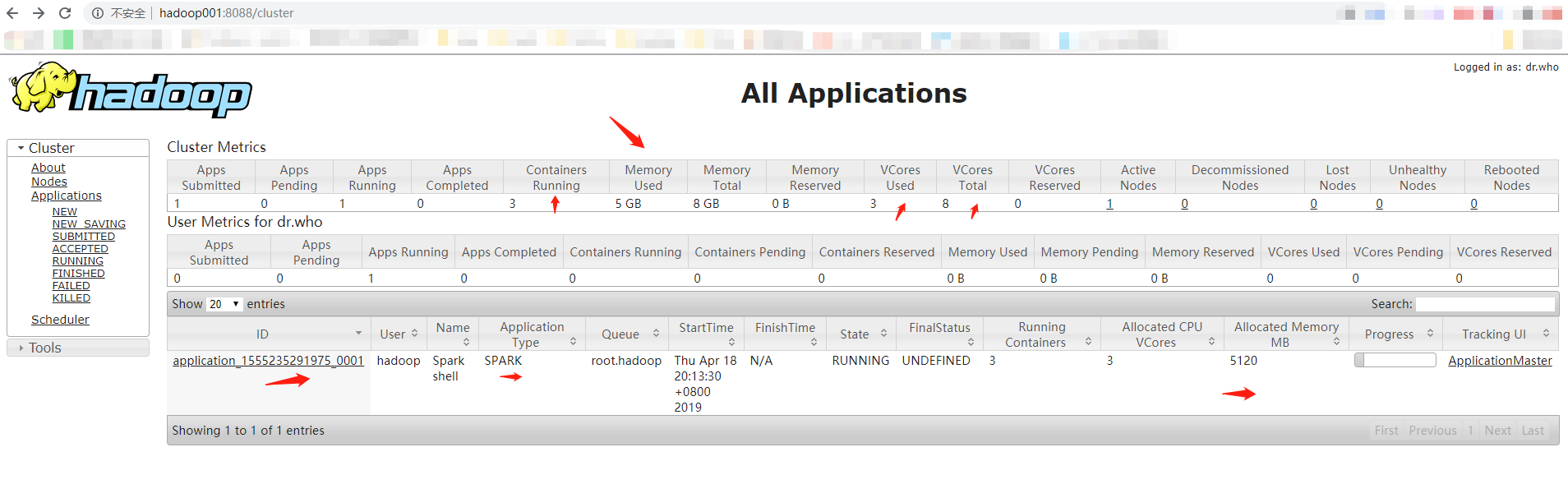
注意:为什么是3个container,3个Vcore,Allocated Memory = 5120MB ?
答案:
yarn.scheduler.minimum-allocation-vcores 单个任务可申请的最小虚拟CPU个数,默认是1,表示每个Container容器在处理任务的时候可申请的最少CPU个数为1个。
yarn.scheduler.maximum-allocation-vcores 单个任务可申请的最多虚拟CPU个数,默认是4,表示每个Container容器在处理任务的时候可申请的最少CPU个数为4个。
所以就是3个container—>3个Vcore
在spark-defaults.conf中spark.driver.memory默认为5g,所以Allocated Memory = 5120MB
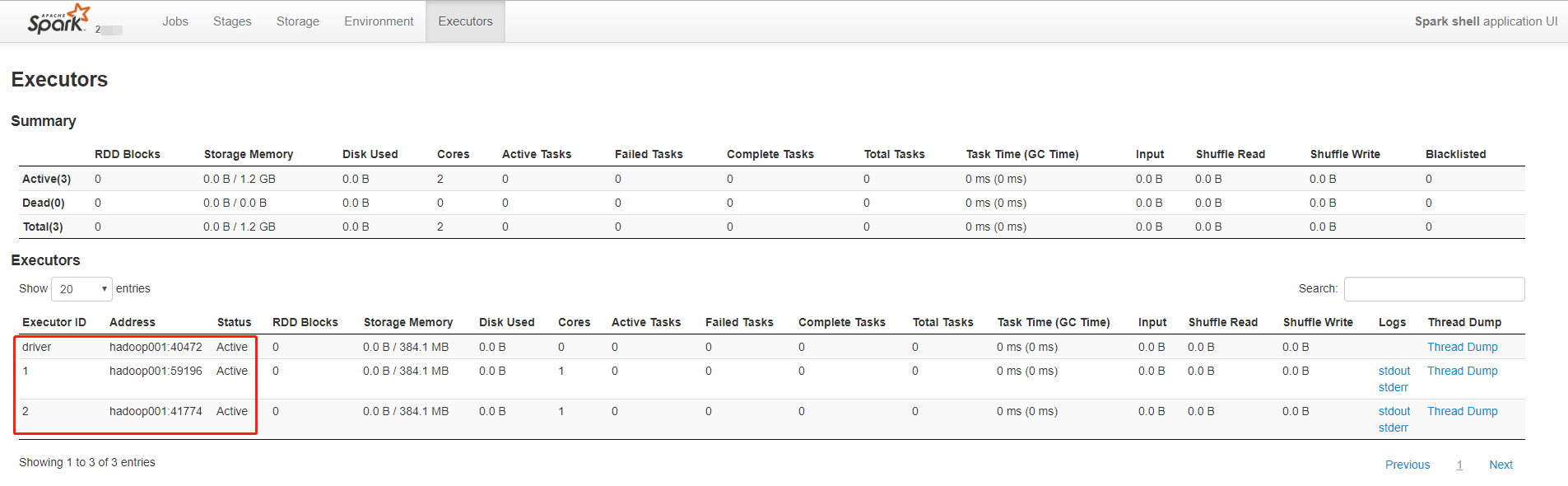
[hadoop@hadoop001 hadoop]$ spark-shell --help
Usage: ./bin/spark-shell [options]
.
.
.
YARN-only:
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
默认是2个executor,再加上一个diver;在yarn中,executor运行在一个container,所以是3个container;
[hadoop@hadoop001 hadoop]$ jps
4672 SecondaryNameNode
4496 DataNode
4832 ResourceManager
48100 Jps
47702 CoarseGrainedExecutorBackend
47641 ExecutorLauncher
4363 NameNode
47515 SparkSubmit
4940 NodeManager
47711 CoarseGrainedExecutorBackend
[hadoop@hadoop001 hadoop]$ ps -ef | grep 47702
hadoop 47702 47692 0 20:13 ? 00:00:20 /usr/java/jdk1.8.0_144/bin/java -server -Xmx1024m -Djava.io.tmpdir=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/nm-local-dir/usercache/hadoop/appcache/application_1555235291975_0001/container_1555235291975_0001_01_000002/tmp -Dspark.driver.port=33381 -Dspark.yarn.app.container.log.dir=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/userlogs/application_1555235291975_0001/container_1555235291975_0001_01_000002 -XX:OnOutOfMemoryError=kill %p org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@hadoop001:33381 --executor-id 1 --hostname hadoop001 --cores 1 --app-id application_1555235291975_0001 --user-class-path file:/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/nm-local-dir/usercache/hadoop/appcache/application_1555235291975_0001/container_1555235291975_0001_01_000002/__app__.jar
hadoop 48119 47418 0 21:09 pts/7 00:00:00 grep 47702
[hadoop@hadoop001 hadoop]$ ps -ef | grep 47711
hadoop 47711 47699 0 20:13 ? 00:00:20 /usr/java/jdk1.8.0_144/bin/java -server -Xmx1024m -Djava.io.tmpdir=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/nm-local-dir/usercache/hadoop/appcache/application_1555235291975_0001/container_1555235291975_0001_01_000003/tmp -Dspark.driver.port=33381 -Dspark.yarn.app.container.log.dir=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/userlogs/application_1555235291975_0001/container_1555235291975_0001_01_000003 -XX:OnOutOfMemoryError=kill %p org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@hadoop001:33381 --executor-id 2 --hostname hadoop001 --cores 1 --app-id application_1555235291975_0001 --user-class-path file:/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/nm-local-dir/usercache/hadoop/appcache/application_1555235291975_0001/container_1555235291975_0001_01_000003/__app__.jar
hadoop 48125 47418 0 21:10 pts/7 00:00:00 grep 47711
[hadoop@hadoop001 hadoop]$ ps -ef|grep 47641
hadoop 47641 47637 0 20:13 ? 00:00:27 /usr/java/jdk1.8.0_144/bin/java -server -Xmx512m -Djava.io.tmpdir=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/nm-local-dir/usercache/hadoop/appcache/application_1555235291975_0001/container_1555235291975_0001_01_000001/tmp -Dspark.yarn.app.container.log.dir=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/userlogs/application_1555235291975_0001/container_1555235291975_0001_01_000001 org.apache.spark.deploy.yarn.ExecutorLauncher --arg hadoop001:33381 --properties-file /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/data/nm-local-dir/usercache/hadoop/appcache/application_1555235291975_0001/container_1555235291975_0001_01_000001/__spark_conf__/__spark_conf__.properties
hadoop 48127 47418 0 21:10 pts/7 00:00:00 grep 47641
用yarn client演示一个wordcount
scala> sc.textFile("hdfs://hadoop001:8020/input/wordcount.txt").flatMap(x=>x.split(",")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((Hello,4), (World,3), (China,2), (Hi,1))
为啥不能用spark-shell 启动yarn cluster?
[hadoop@hadoop001 ~]$ spark-shell --master yarn --deploy-mode cluster
Exception in thread "main" org.apache.spark.SparkException: Cluster deploy mode is not applicable to Spark shells.
at org.apache.spark.deploy.SparkSubmit.error(SparkSubmit.scala:857)
at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala:292)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:143)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Spark on yarn cluster 求pi
[hadoop@hadoop001 spark-2.4.2-bin-2.6.0-cdh5.7.0]$ spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --dr
iver-memory 2g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
19/04/18 23:36:27 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:28 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:29 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:30 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:31 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:32 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:33 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:34 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:35 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:36 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:37 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:38 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:39 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:40 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:41 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:42 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:43 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:44 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:45 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:46 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:47 INFO yarn.Client: Application report for application_1555597553345_0009 (state: ACCEPTED)
19/04/18 23:36:48 INFO yarn.Client: Application report for application_1555597553345_0009 (state: KILLED)
19/04/18 23:36:48 INFO yarn.Client:
client token: N/A
diagnostics: Application killed by user.
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: root.hadoop
start time: 1555601354249
final status: KILLED
tracking URL: http://hadoop001:8088/cluster/app/application_1555597553345_0009
user: hadoop
19/04/18 23:36:48 INFO yarn.Client: Deleted staging directory hdfs://hadoop001:8020/user/hadoop/.sparkStaging/application_1555597553345_0009
Exception in thread "main" org.apache.spark.SparkException: Application application_1555597553345_0009 is killed
at org.apache.spark.deploy.yarn.Client.run(Client.scala:1152)
at org.apache.spark.deploy.yarn.YarnClusterApplication.start(Client.scala:1526)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
19/04/18 23:36:48 INFO util.ShutdownHookManager: Shutdown hook called
19/04/18 23:36:48 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-ea7fed61-d179-4df8-99c2-cc49e4e89011
19/04/18 23:36:48 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-865cb6f0-2eec-49d6-a106-f83edfbb4c78
检查错误,发现内存占满了
[hadoop@hadoop001 hadoop]$ free -g
total used free shared buffers cached
Mem: 3 3 0 0 0 1
-/+ buffers/cache: 1 1
Swap: 1 0 1
[hadoop@hadoop001 hadoop]$ yarn application -list
19/04/18 23:34:12 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Total number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):5
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1555597553345_0007 org.apache.spark.examples.SparkPi SPARK hadoop root.hadoop ACCEPTED UNDEFINED 0% N/A
application_1555597553345_0006 org.apache.spark.examples.SparkPi SPARK hadoop root.thequeue ACCEPTED UNDEFINED 0% N/A
application_1555597553345_0004 org.apache.spark.examples.SparkPi SPARK hadoop root.thequeue ACCEPTED UNDEFINED 0% N/A
application_1555597553345_0009 org.apache.spark.examples.SparkPi SPARK hadoop root.hadoop ACCEPTED UNDEFINED 0% N/A
application_1555597553345_0008 org.apache.spark.examples.SparkPi SPARK hadoop root.hadoop ACCEPTED UNDEFINED 0% N/A
Kill 掉application_id
[hadoop@hadoop001 hadoop]$ yarn application -kill application_1555597553345_0007
19/04/18 23:36:34 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Killing application application_1555597553345_0007
19/04/18 23:36:35 INFO impl.YarnClientImpl: Killed application application_1555597553345_0007
[hadoop@hadoop001 hadoop]$ yarn application -kill application_1555597553345_0006
19/04/18 23:36:41 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Killing application application_1555597553345_0006
19/04/18 23:36:42 INFO impl.YarnClientImpl: Killed application application_1555597553345_0006
[hadoop@hadoop001 hadoop]$ yarn application -kill application_1555597553345_0009
19/04/18 23:36:47 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Killing application application_1555597553345_0009
19/04/18 23:36:48 INFO impl.YarnClientImpl: Killed application application_1555597553345_0009
[hadoop@hadoop001 hadoop]$ yarn application -kill application_1555597553345_0008
19/04/18 23:36:53 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Killing application application_1555597553345_0008
19/04/18 23:36:54 INFO impl.YarnClientImpl: Killed application application_1555597553345_0008
[hadoop@hadoop001 hadoop]$
[hadoop@hadoop001 hadoop]$ yarn application -list
19/04/18 23:36:59 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Total number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1555597553345_0004 org.apache.spark.examples.SparkPi SPARK hadoop root.thequeue ACCEPTED UNDEFINED 0% N/A
[hadoop@hadoop001 hadoop]$ yarn application -kill application_1555597553345_0004
19/04/18 23:37:11 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Killing application application_1555597553345_0004
19/04/18 23:37:12 INFO impl.YarnClientImpl: Killed application application_1555597553345_0004
[hadoop@hadoop001 hadoop]$ yarn application -list
19/04/18 23:37:15 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Total number of applications (application-types: [] and states: [SUBMITTED, ACCEPTED, RUNNING]):0
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
[hadoop@hadoop001 spark-2.4.2-bin-2.6.0-cdh5.7.0]$ spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --dr
iver-memory 2g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
19/04/18 23:37:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
19/04/18 23:37:27 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
19/04/18 23:37:28 INFO yarn.Client: Requesting a new application from cluster with 1 NodeManagers
19/04/18 23:37:28 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
19/04/18 23:37:28 INFO yarn.Client: Will allocate AM container, with 2432 MB memory including 384 MB overhead
19/04/18 23:37:28 INFO yarn.Client: Setting up container launch context for our AM
19/04/18 23:37:28 INFO yarn.Client: Setting up the launch environment for our AM container
19/04/18 23:37:28 INFO yarn.Client: Preparing resources for our AM container
19/04/18 23:37:28 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
19/04/18 23:37:32 INFO yarn.Client: Uploading resource file:/tmp/spark-415e4366-1327-4645-b67f-6ced33deba08/__spark_libs__15132054032703849.zip -> hdfs://hadoop001:8020/user/hadoop/.sparkStaging/application_1555597553345_0010/__spark_libs__15132054032703849.zip
19/04/18 23:37:34 INFO yarn.Client: Uploading resource file:/home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.4.2.jar -> hdfs://hadoop001:8020/user/hadoop/.sparkStaging/application_1555597553345_0010/spark-examples_2.11-2.4.2.jar
19/04/18 23:37:34 INFO yarn.Client: Uploading resource file:/tmp/spark-415e4366-1327-4645-b67f-6ced33deba08/__spark_conf__8018852380361477831.zip -> hdfs://hadoop001:8020/user/hadoop/.sparkStaging/application_1555597553345_0010/__spark_conf__.zip
19/04/18 23:37:34 INFO spark.SecurityManager: Changing view acls to: hadoop
19/04/18 23:37:34 INFO spark.SecurityManager: Changing modify acls to: hadoop
19/04/18 23:37:34 INFO spark.SecurityManager: Changing view acls groups to:
19/04/18 23:37:34 INFO spark.SecurityManager: Changing modify acls groups to:
19/04/18 23:37:34 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set()
19/04/18 23:37:36 INFO yarn.Client: Submitting application application_1555597553345_0010 to ResourceManager
19/04/18 23:37:36 INFO impl.YarnClientImpl: Submitted application application_1555597553345_0010
19/04/18 23:37:37 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:37 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: root.hadoop
start time: 1555601856826
final status: UNDEFINED
tracking URL: http://hadoop001:8088/proxy/application_1555597553345_0010/
user: hadoop
19/04/18 23:37:38 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:39 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:40 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:41 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:42 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:43 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:44 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:45 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:46 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:47 INFO yarn.Client: Application report for application_1555597553345_0010 (state: ACCEPTED)
19/04/18 23:37:48 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:48 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop001
ApplicationMaster RPC port: 43325
queue: root.hadoop
start time: 1555601856826
final status: UNDEFINED
tracking URL: http://hadoop001:8088/proxy/application_1555597553345_0010/
user: hadoop
19/04/18 23:37:49 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:50 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:51 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:52 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:53 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:54 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:55 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:56 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:57 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:58 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:37:59 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:38:00 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:38:01 INFO yarn.Client: Application report for application_1555597553345_0010 (state: RUNNING)
19/04/18 23:38:02 INFO yarn.Client: Application report for application_1555597553345_0010 (state: FINISHED)
19/04/18 23:38:02 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: hadoop001
ApplicationMaster RPC port: 43325
queue: root.hadoop
start time: 1555601856826
final status: SUCCEEDED
tracking URL: http://hadoop001:8088/proxy/application_1555597553345_0010/A
user: hadoop
19/04/18 23:38:02 INFO util.ShutdownHookManager: Shutdown hook called
19/04/18 23:38:02 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-415e4366-1327-4645-b67f-6ced33deba08
19/04/18 23:38:02 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-e90376df-ef41-4046-8852-f05235f8900e
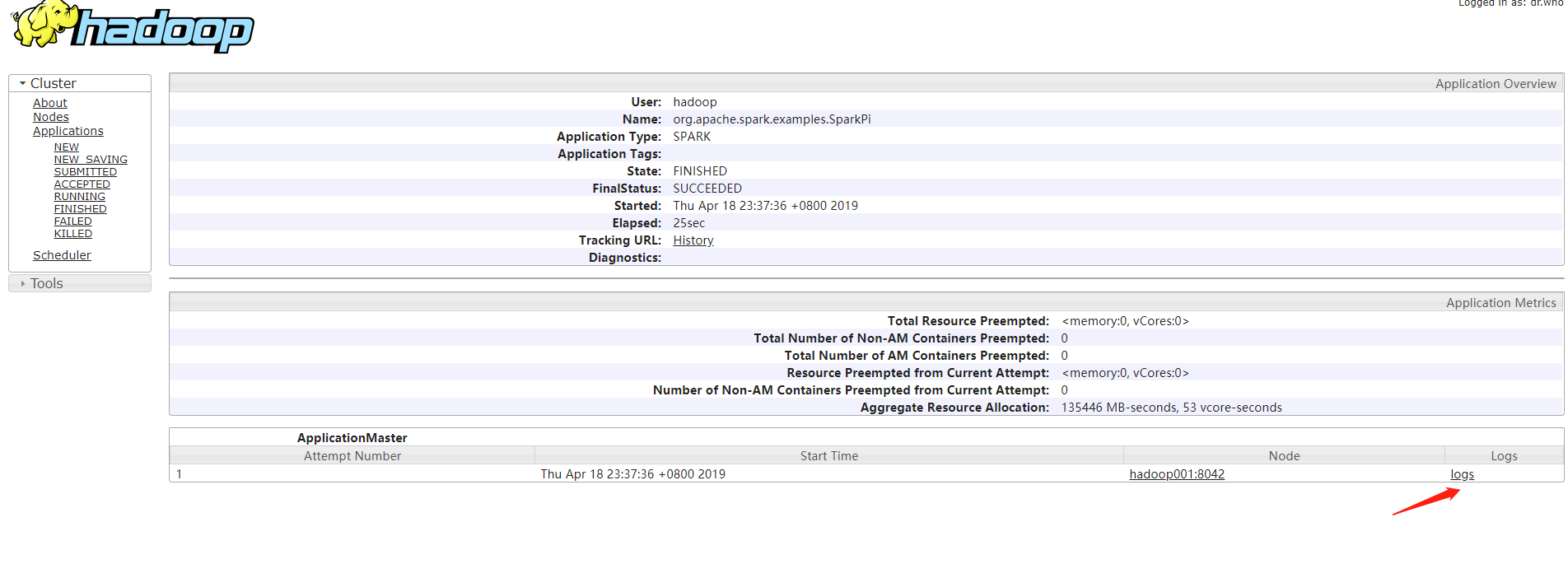
成功了,在Web UI 上查看结果

参考文章
spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)