1. RDD 是什么?
源码中对RDD的描述
/**
* A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable,
* partitioned collection of elements that can be operated on in parallel. This class contains the
* basic operations available on all RDDs, such as `map`, `filter`, and `persist`. In addition,
* [[org.apache.spark.rdd.PairRDDFunctions]] contains operations available only on RDDs of key-value
* pairs, such as `groupByKey` and `join`;
* [[org.apache.spark.rdd.DoubleRDDFunctions]] contains operations available only on RDDs of
* Doubles; and
* [[org.apache.spark.rdd.SequenceFileRDDFunctions]] contains operations available on RDDs that
* can be saved as SequenceFiles.
* All operations are automatically available on any RDD of the right type (e.g. RDD[(Int, Int)])
* through implicit.
*/
RDD 源码定义
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
if (classOf[RDD[_]].isAssignableFrom(elementClassTag.runtimeClass)) {
// This is a warning instead of an exception in order to avoid breaking user programs that
// might have defined nested RDDs without running jobs with them.
logWarning("Spark does not support nested RDDs (see SPARK-5063)")
}
一个RDD就是一个分布式对象的集合,本质上是一个只读文件的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个 RDD的不同分区可以被保存到集群中的不同节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型,即 RDD是只读的记录分区的集合,不能直接被修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作 (如map、join、group by等)而创建得到新的RDD。
RDD的优点:惰性调用,管道化,避免同步等待,不需要保存中间结果,每次操作变得简单。
一个RDD转换完以后,数据输出直接可以作为下一个RDD操作的输入,然后直接作为下一个RDD操作的输入,形成流水线化,可以管道化的方式, 中间就不需要去存储,这个中间结果是不需要落到磁盘里面去的,可以一直以管道化的流一直往下流,这里面每次操作也变得非常简单, 把一个复杂的操作分解成非常多的这种转换操作,每一次转换任务都非常简单,比如这次转换时个map,下次转换是filter, 把整个复杂的应用程序逻辑,分解成非常多的转换操作,这些转换操作构成这么一个血缘关系,对于每一步转换操作,执行逻辑就非常的简单了, 只需要执行一个map或者filter就可以了,实际上对于整个系统的健壮性来讲就非常有帮助了;像MapReduce在每一步操作的时候, 需要在map和reduce函数里面写入非常复杂的逻辑,程序就变得比较难编写了,而经过这么设计后,生成一个DAG图,DAG图当中的每一次转换操作, 都是一个非常简单的操作,编写程序更加简单。
2. RDD的特性
2.1 源码中对RDD特性的描述
Internally, each RDD is characterized by five main properties:
(1)A list of partitions
(2)A function for computing each split
(3)A list of dependencies on other RDDs
(4)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
(5)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
All of the scheduling and execution in Spark is done based on these methods, allowing each RDD
to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for reading data from a new storage system) by overriding these functions. Please refer to the
<a href="http://people.csail.mit.edu/matei/papers/2012/nsdi_spark.pdf">Spark paper</a>
for more details on RDD internals.
-
一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被计算任务处理,并决定并行计算的粒度。用户可以在创建RDD 时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。 -
一个计算分区的函数。Spark中的RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合, 不需要保存每次计算的结果。 -
RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时, Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新的计算。 -
一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于 范围的RangePartitioner。只有对于Key-Value的RDD,才会有Partitioner,非Key-Value的RDD的Partitioner的值是None。 Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。 -
一个列表,存储存取每个Partion的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partion所在的块的位置。按照”移动数据不如移动计算“的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块地存储位置。
2.2 RDD五大特性在源码中的体现
protected def getPartitions: Array[Partition] //对应第一个特性
def compute(split: Partition, context: TaskContext): Iterator[T] //对应第二个特性
protected def getDependencies: Seq[Dependency[_]] = deps //对应第三个特性
@transient val partitioner: Option[Partitioner] = None //对应第四个特性
protected def getPreferredLocations(split: Partition): Seq[String] = Nil //对应第五个特性
2.3 为什么RDD具有天生的容错性?
讨论RDD的容错性,首先我们先看其他分布式怎么实现容错性的。
其他分布式系统怎么实现容错的呢?
一般就是借助数据复制和日志记录,冗余的复制一份,主节点坏了就用从节点的数据;或者日志重做。但是在数据密集型的应用中, 用这种数据复制或者日志记录的方式,去对她进行数据容错的话,代价是非常昂贵的,会涉及到大量的数据传输开销,尤其在不同节点之间通过 网络传输,开销是非常大的。
RDD的设计方式会构成一张DAG图,每次转换都会得到下一个RDD,如果某一个RDD坏掉,只要从她父RDD重新计算转换一下就可以得到丢失 的分区,非常简单,根本不需要其他那样进行数据复制和日志记录;它这种血缘方式的设计方式,可以在整个DAG图当中,任何一个RDD当中的任何一个 分区出了问题,出了错误都可以通过往前追溯找到它的父亲RDD和分区,通过再次执行转换操作又得到丢失的分区。所以采用这种血缘关系和依赖关系 具有天生的容错机制,都不需要记录日志和数据复制。
3. 如何创建RDD
There are two ways to create RDDs:
- parallelizing an existing collection in your driver program,
- or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat.
方法1:用Parallelized Collections 创建RDD
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
方法2:用External Datasets 创建RDD
scala> val distFile = sc.textFile("data.txt")
distFile: org.apache.spark.rdd.RDD[String] = data.txt MapPartitionsRDD[10] at textFile at <console>:26
scala> val distFile = sc.textFile("file:///home/hadoop/data/dept.txt") # 读取Linux 中的
val distFile = sc.textFile("hdfs://hadoop001:8020/user/hive/warehouse/hive.db/page_views_seq/000006_0") #读取hdfs中的
distFile.split("\t").map(x=>(x,1)).reducebykey(_+_).collect
# 读取HDFS上的Sequencefile
val distFile = sc.textFile("hdfs://hadoop001:8020/mapreduce/input/orders.csv")
val rdd = sc.wholeTextFiles("hdfs://hadoop001:8020/mapreduce/input/orders.csv")
scala> rdd.collect
res11: Array[(String, String)] =
Array((hdfs://hadoop001:8020/mapreduce/input/orders.csv,"3,A,12.95,02-Jun-2018
1,B,88.25,20-May-2018
2,C,32.00,30-Nov-2017
4,D,25.02,22-Jan-2019
")) # 可以返回文件的名称
data.saveAsSequenceFile("file:///home/hadoop/data/")
4. RDD的运行原理
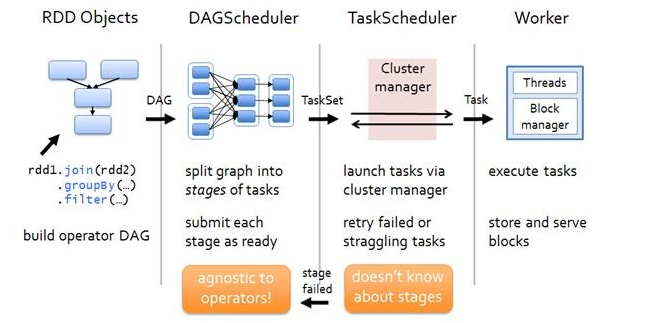
那么RDD在Spark架构中是如何运行的呢?总高层次来看,主要分为三步:
1.创建 RDD 对象
2.DAGScheduler模块介入运算,计算RDD之间的依赖关系。RDD之间的依赖关系就形成了DAG
3.每一个JOB被分为多个Stage,划分Stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个Stage,避免多个Stage之间的消息传递开销。
以下面一个按 A-Z 首字母分类,查找相同首字母下不同姓名总个数的例子来看一下 RDD 是如何运行起来的。
scala> sc.textFile("hdfs:/names").map(name =>(name.charAt(0),name)).groupByKey().mapValues(names => names.toSet.size).collect
res3: Array[(Char, Int)] = Array((P,1), (A,2))
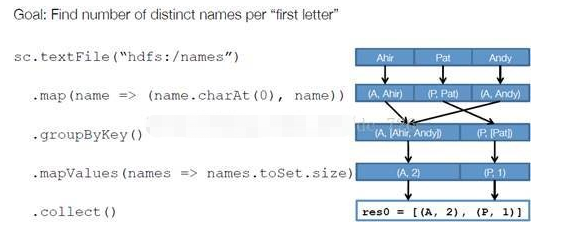
步骤 1 :创建 RDD 上面的例子除去最后一个 collect 是个动作,不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。因此第一步就是创建好 所有 RDD( 内部的五项信息 ) 。
步骤 2 :创建执行计划 Spark 会尽可能地管道化,并基于是否要重新组织数据(宽依赖或者shuffle)来划分阶段 (stage) ,例如本例中的 groupBy() 转换就会将整个 执行计划划分成两阶段执行。最终会产生一个 DAG(directed acyclic graph ,有向无环图 ) 作为逻辑执行计划。
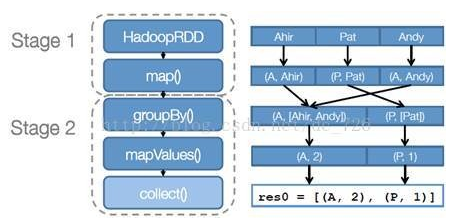
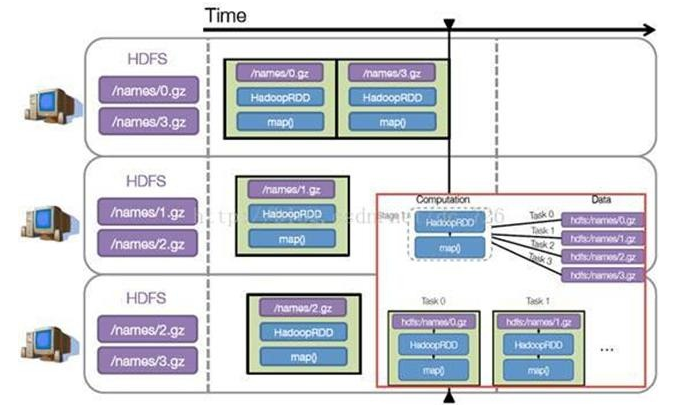
步骤 3 :调度任务 将各阶段划分成不同的 任务 (task) ,每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。 因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续。
假设本例中的 hdfs://names 下有四个文件块,那么 HadoopRDD 中 partitions 就会有四个分区对应这四个块数据,同时 preferedLocations 会指明这四个块的最佳位置。现在,就可以创建出四个任务,并调度到合适的集群结点上。
5. RDD的依赖
5.1 RDD的依赖概述
RDD的成员之一是依赖集,依赖集也关系到任务调度。
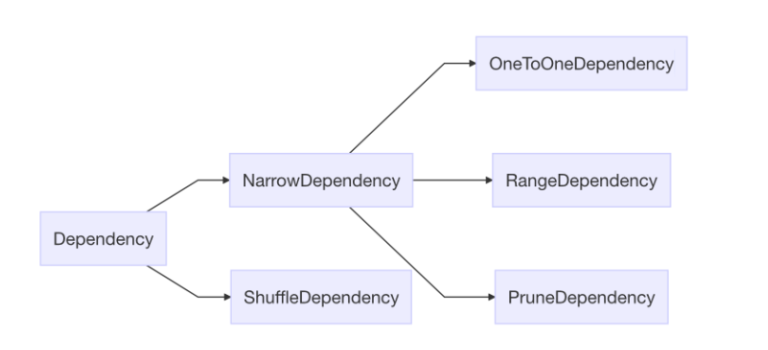
[RDD Dependency.scala源码](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/shuffle/sort/SortShuffleManager.scala)
# 在Dependency.scala中
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD
* @param outStart the start of the range in the child RDD
* @param length the length of the range
*/
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
在PartitionPruningRDDPartition.scala中
# 在PartitionPruningRDDPartition.scala中
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD
* @param outStart the start of the range in the child RDD
* @param length the length of the range
*/
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
5.2 RDD的窄依赖
/**
* :: DeveloperApi ::
* Base class for dependencies where each partition of the child RDD depends on a small number
* of partitions of the parent RDD. Narrow dependencies allow for pipelined execution.
*/
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}
5.3 宽依赖
/**
* :: DeveloperApi ::
* Represents a dependency on the output of a shuffle stage. Note that in the case of shuffle,
* the RDD is transient since we don't need it on the executor side.
*
* @param _rdd the parent RDD
* @param partitioner partitioner used to partition the shuffle output
* @param serializer [[org.apache.spark.serializer.Serializer Serializer]] to use. If not set
* explicitly then the default serializer, as specified by `spark.serializer`
* config option, will be used.
* @param keyOrdering key ordering for RDD's shuffles
* @param aggregator map/reduce-side aggregator for RDD's shuffle
* @param mapSideCombine whether to perform partial aggregation (also known as map-side combine)
* @param shuffleWriterProcessor the processor to control the write behavior in ShuffleMapTask
*/
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false,
val shuffleWriterProcessor: ShuffleWriteProcessor = new ShuffleWriteProcessor)
extends Dependency[Product2[K, V]] {
if (mapSideCombine) {
require(aggregator.isDefined, "Map-side combine without Aggregator specified!")
}
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}
通过阅读以上代码可以得到以下信息:
- 依赖的根类是Dependency,只有一个RDD 成员,表示依赖的对象。这类继承了Serializable类,是可以序列化的。
- 依赖分为两大种,一个叫窄依赖(Narrow),另一个就洗牌依赖(Shuffle,很多材料也叫作“宽”依赖)。
- 从数量关系上说,“1-to-1”(OneToOne)、“n-to-1”(Range)、“1-to-部分分区”(Prune,剪枝)是窄依赖,宽依赖是“n-to-n”的。
- “1-to-1”是RDD的默认依赖。上节中的MapPartitionRDD是一对一的转换,就包含“1-to-1“依赖。
- ”n-to-1“的依赖只有一个使用场景——UnionRDD,“交”运算,多个 RDD 合并到一个 RDD 中。
- 剪枝依赖是个私有对象,用于优化,减少数据载入。
- 洗牌依赖复杂一些。
通过阅读宽依赖可以得出下面结论
- 这个类有三个泛型类型,K=key,V=value,C=combiner;
- 洗牌依赖只能用于Product2[K, V]及其父类,即 KV 数据;
- 成员有 分区器(partitioner) 、序列器(serializer)、排序器(keyOrdering)、聚合器(aggregator)、map 端聚合开关(mapSideCombine);
- _rdd.context.newShuffleId() 获得一个自增的 ID;
- _rdd.context.env.shuffleManager.registerShuffle 获得几个洗牌的句柄。通过core/shuffle/sort/SortShuffleManager代码可以知道,一共有三种句柄:
- 分区数很少(小于变量spark.shuffle.sort.bypassMergeThreshold,默认200)时,用BypassMergeSortShuffleHandle,直接发送数据合并,不用耗时的序列化和反序列化;
- 否则,如果能序列化,则用SerializedShuffleHandle,用序列化和反序列化,降低网络 IO;
- 否则,使用基础的BaseShuffleHandle。
RDD依赖关系结论
- 在 RDD 的转换时,会用到依赖
- 依赖包括窄依赖(1-to-1、n-to-1关系)、洗牌依赖(n-to-n 关系)
- 洗牌依赖包含分区器、序列器、排序器、聚合器、map聚合开关、ID、洗牌类型句柄等成分组成。洗牌类型句柄有三种。
窄依赖:一个父RDD的partition只能被子RDD的某个partition使用一次宽依赖:一个父RDD的partition只能被子RDD的partition使用多次Stage的划分是由宽依赖(shuffle类算子)决定的