1. 概述
作为区别于 Hadoop 的一个重要 feature,cache 机制保证了需要访问重复数据的应用(如迭代型算法和交互式应用)可以运行的更快。与 Hadoop MapReduce job 不同的是 Spark 的逻辑/物理执行图可能很庞大,task 中 computing chain 可能会很长,计算某些 RDD 也可能会很耗时。这时,如果 task 中途运行出错,那么 task 的整个 computing chain 需要重算,代价太高。因此,有必要将计算代价较大的 RDD checkpoint 一下,这样,当下游 RDD 计算出错时,可以直接从 checkpoint 过的 RDD 那里读取数据继续算。
2. Cache机制
RDD通过persist方法或者cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
2.1 源码中对cache的介绍
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StroageLevel中的定义的。
**
* Various [[org.apache.spark.storage.StorageLevel]] defined and utility functions for creating
* new storage levels.
*/
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
缓存有可能会丢失数据,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失数据,RDD也能正确执行。通过基于RDD的一系列转换,丢失数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
2.2 问题思考
-
问题:哪些 RDD 需要 cache?会被重复使用的(但不能太大)。
-
问题:用户怎么设定哪些 RDD 要 cache?用户只与driver program打交道,因此只能用rdd.cache()去cache用户能看到的RDD。所谓能看到指的是
调用transformation()后生成的RDD,而某些transformation()算子生成的RDD是不能被用户直接cache的,
比如reduceByKey()中会生成的ShuffledRDD、MapPartionsRDD是不能被用户直接cache的。
-
问题:driver program 设定 rdd.cache() 后,系统怎么对 RDD 进行 cache?先不看实现,自己来想象一下如何完成 cache:当 task 计算得到 RDD 的某个 partition 的第一个 record 后,就去判断该 RDD 是否要被 cache,如果要被 cache 的话,将这个 record 及后续计算的到的 records 直接丢给本地 blockManager 的 memoryStore,如果 memoryStore 存不下就交给 diskStore 存放到磁盘。
实际实现与设想的基本类似,区别在于:将要计算 RDD partition 的时候(而不是已经计算得到第一个 record 的时候)就去判断 partition 要不要被 cache。如果要被 cache 的话,先将 partition 计算出来,然后 cache 到内存。cache 只使用 memory,写磁盘的话那就叫 checkpoint 了。
调用 rdd.cache() 后, rdd 就变成 persistRDD 了,其 StorageLevel 为 MEMORY_ONLY。persistRDD 会告知 driver 说自己是需要被 persist 的。
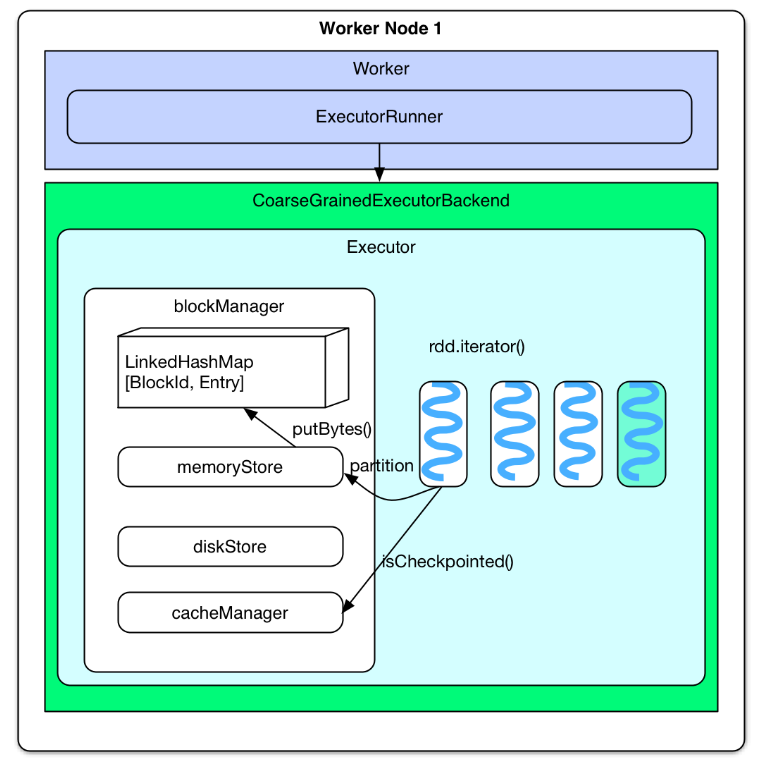
-
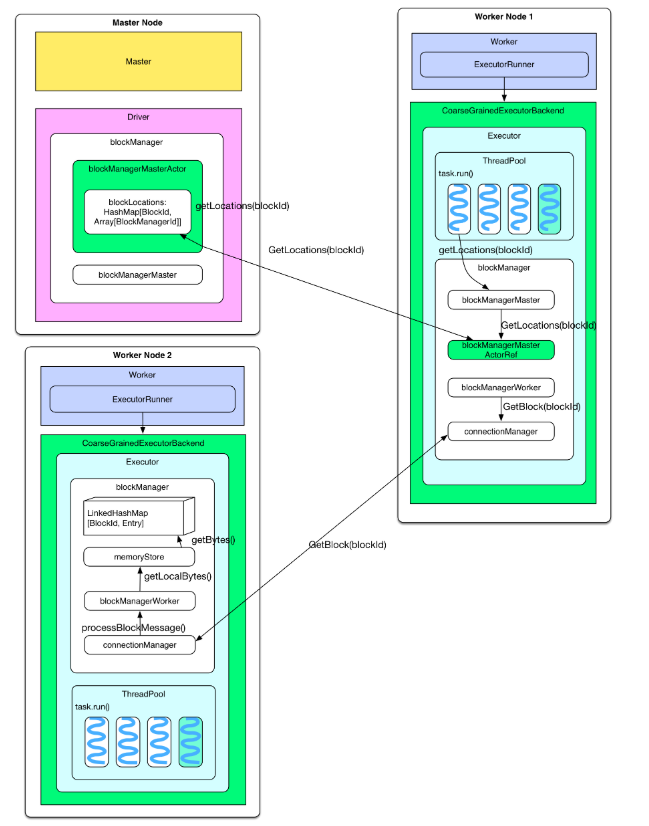
问题:cached RDD 怎么被读取?下次计算(一般是同一 application 的下一个 job 计算)时如果用到 cached RDD,task 会直接去 blockManager 的 memoryStore 中读取。具体地讲,当要计算某个 rdd 中的 partition 时候(通过调用 rdd.iterator())会先去 blockManager 里面查找是否已经被 cache 了,如果 partition 被 cache 在本地,就直接使用 blockManager.getLocal() 去本地 memoryStore 里读取。如果该 partition 被其他节点上 blockManager cache 了,会通过 blockManager.getRemote() 去其他节点上读取,读取过程如下图。
2.3 生产上用啥存储级别
官网介绍
Which Storage Level to Choose?
Spark’s storage levels are meant to provide different trade-offs between memory usage and CPU efficiency. We recommend going through the following process to select one:
- If your RDDs fit comfortably with the default storage level (
MEMORY_ONLY), leave them that way. This is the most CPU-efficient option, allowing operations on the RDDs to run as fast as possible. - If not, try using
MEMORY_ONLY_SERand selecting a fast serialization library to make the objects much more space-efficient, but still reasonably fast to access. (Java and Scala) - Don’t spill to disk unless the functions that computed your datasets are expensive, or they filter a large amount of the data. Otherwise, recomputing a partition may be as fast as reading it from disk.
- Use the replicated storage levels if you want fast fault recovery (e.g. if using Spark to serve requests from a web application). All the storage levels provide full fault tolerance by recomputing lost data, but the replicated ones let you continue running tasks on the RDD without waiting to recompute a lost partition.
根据官网上的介绍可得出,在生产上不用存到磁盘的,最好的存储级别是MEMORY_ONLY,也是默认的;然后是用
MEMORY_ONLY_SER,并选择快速序列化库(Java serialization 或者 Kryo serialization ;注意:Spark还可以使用Kryo库(版本4)更快地序列化对象。 Kryo比Java序列化(通常高达10倍)明显更快,更紧凑,但不支持所有Serializable类型,并且要求您提前注册您将在程序中使用的类以获得最佳性能。),以使对象更节省空间,但仍然可以快速访问。
Spark 官网对序列化的介绍 Data Serialization
3. Checkpoint
3.1 checkpoint概述
源码中对checkpoint的介绍
/**
* Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint
* directory set with `SparkContext#setCheckpointDir` and all references to its parent
* RDDs will be removed. This function must be called before any job has been
* executed on this RDD. It is strongly recommended that this RDD is persisted in
* memory, otherwise saving it on a file will require recomputation.
*/
def checkpoint(): Unit = RDDCheckpointData.synchronized {
// NOTE: we use a global lock here due to complexities downstream with ensuring
// children RDD partitions point to the correct parent partitions. In the future
// we should revisit this consideration.
if (context.checkpointDir.isEmpty) {
throw new SparkException("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new ReliableRDDCheckpointData(this))
}
}
检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage(血统)做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失数据,从做检查点的RDD开始重做LIneage,就会减少开销。
设置checkpoint的目录,可以是本地文件夹、也可以是HDFS。一般是在具有容错能力,高可靠的文件系统上(比如HDFS、S3等)设置一个检查点路径,用于保存检查点数据。
其他系统的checkpoint Spark RDD,MySQL,HDFS,Oracle的checkpoint之间的对比
3.2 关于checkpoint的问题
-
问题:哪些 RDD 需要 checkpoint?运算时间很长或者运算量太大才能得到的RDD,computing chain 过长或依赖其他RDD很多的RDD。
实际上,将ShuffleMapTask的输出结果存放到本地磁盘也算是checkpoint,只不过这个checkpoint的主要目的是取partition输出数据。
-
问题:什么时候checkpoint?cache机制是每计算出一个要cache的partition就直接将其cache到内存了。但是checkpoint没有使用这种第一次计算得到就存储的方法,而是等到job结束后另外启动专门的job去完成checkpoint。也就是说需要checkpoint的RDD会被计算2次。因此,在使用rdd.checkpoint()的时候,建议加上rdd.cache(),这样第二次运行的job就不用再去计算该rdd了,直接读取cache写磁盘。其实Spark提供了rdd.persist(StroageLevel.DISK_ONLY)这样的方法,相当于cache到了磁盘上,但是这个persist和checkpoint有很多的不同。
-
问题:checkpoint 怎么实现?RDD 需要经过 [ Initialized –> marked for checkpointing –> checkpointing in progress –> checkpointed ] 这几个阶段才能被 checkpoint。
Initialized: 首先 driver program 需要使用 rdd.checkpoint() 去设定哪些 rdd 需要 checkpoint,设定后,该 rdd 就接受 RDDCheckpointData 管理。用户还要设定 checkpoint 的存储路径,一般在 HDFS 上。
marked for checkpointing:初始化后,RDDCheckpointData 会将 rdd 标记为 MarkedForCheckpoint。
checkpointing in progress:每个 job 运行结束后会调用 finalRdd.doCheckpoint(),finalRdd 会顺着 computing chain 回溯扫描,碰到要 checkpoint 的 RDD 就将其标记为 CheckpointingInProgress,然后将写磁盘(比如写 HDFS)需要的配置文件(如 core-site.xml 等)broadcast 到其他 worker 节点上的 blockManager。完成以后,启动一个 job 来完成 checkpoint(使用
rdd.context.runJob(rdd, CheckpointRDD.writeToFile(path.toString, broadcastedConf)))。checkpointed:job 完成 checkpoint 后,将该 rdd 的 dependency 全部清掉,并设定该 rdd 状态为 checkpointed。然后,为该 rdd 强加一个依赖,设置该 rdd 的 parent rdd 为 CheckpointRDD,该 CheckpointRDD 负责以后读取在文件系统上的 checkpoint 文件,生成该 rdd 的 partition。
-
问题:怎么读取 checkpoint 过的 RDD?在 runJob() 的时候会先调用 finalRDD 的 partitions() 来确定最后会有多个 task。rdd.partitions() 会去检查(通过 RDDCheckpointData 去检查,因为它负责管理被 checkpoint 过的 rdd)该 rdd 是会否被 checkpoint 过了,如果该 rdd 已经被 checkpoint 过了,直接返回该 rdd 的 partitions 也就是 Array[Partition]。
当调用 rdd.iterator() 去计算该 rdd 的 partition 的时候,会调用 computeOrReadCheckpoint(split: Partition) 去查看该 rdd 是否被 checkpoint 过了,如果是,就调用该 rdd 的 parent rdd 的 iterator() 也就是 CheckpointRDD.iterator(),CheckpointRDD 负责读取文件系统上的文件,生成该 rdd 的 partition。这就解释了为什么那么 trickly 地为 checkpointed rdd 添加一个 parent CheckpointRDD。
-
问题:cache 与 checkpoint 的区别?关于这个问题,Tathagata Das 有一段回答: There is a significant difference between cache and checkpoint. Cache materializes the RDD and keeps it in memory and/or disk(其实只有 memory). But the lineage(也就是 computing chain) of RDD (that is, seq of operations that generated the RDD) will be remembered, so that if there are node failures and parts of the cached RDDs are lost, they can be regenerated. However, checkpoint saves the RDD to an HDFS file and actually forgets the lineage completely. This is allows long lineages to be truncated and the data to be saved reliably in HDFS (which is naturally fault tolerant by replication).
-
问题:checkpoint 与 persist to a disk的区别?Persist
- Persisting or caching with StorageLevel.DISK_ONLY cause the generation of RDD to be computed and stored in a location such that subsequent use of that RDD will not go beyond that points in recomputing the linage.
- After persist is called, Spark still remembers the lineage of the RDD even though it doesn’t call it.
- Secondly, after the application terminates, the cache is cleared or file destroyed
Checkpointing
- Checkpointing stores the rdd physically to hdfs and destroys the lineage that created it.
- The checkpoint file won’t be deleted even after the Spark application terminated.
- Checkpoint files can be used in subsequent job run or driver program
- Checkpointing an RDD causes double computation because the operation will first call a cache before doing the actual job of computing and writing to the checkpoint directory.
总结
Hadoop MapReduce 在执行 job 的时候,不停地做持久化,每个 task 运行结束做一次,每个 job 运行结束做一次(写到 HDFS)。在 task 运行过程中也不停地在内存和磁盘间 swap 来 swap 去。 可是讽刺的是,Hadoop 中的 task 太傻,中途出错需要完全重新运行,比如 shuffle 了一半的数据存放到了磁盘,下次重新运行时仍然要重新 shuffle。Spark 好的一点在于尽量不去持久化,所以使用 pipeline,cache 等机制。用户如果感觉 job 可能会出错可以手动去 checkpoint 一些 critical 的 RDD,job 如果出错,下次运行时直接从 checkpoint 中读取数据。唯一不足的是,checkpoint 需要两次运行 job。