1. ReduceByKey
1.1 源码中介绍
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce.
*/
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce. Output will be hash-partitioned with numPartitions partitions.
*/
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] = self.withScope {
reduceByKey(new HashPartitioner(numPartitions), func)
}
由源码可以得出,reduceByKey在每个mapper中进行合并然后发送到reducer,相当于MapReduce的combiner
1.2 测试
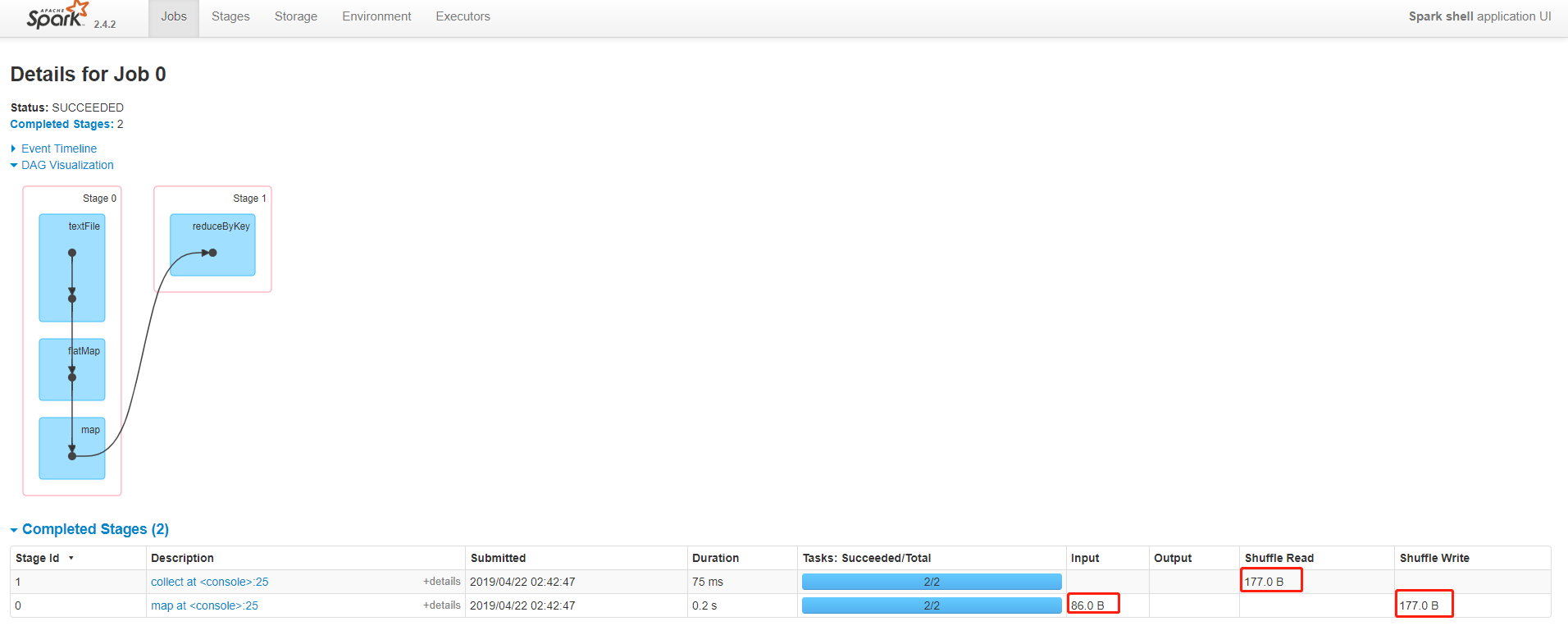
scala> sc.textFile("file:///home/hadoop/data/wordcount.txt").flatMap(x=>x.split(",")).map((_,1)).reduceByKey(_+_).collect
res1: Array[(String, Int)] = Array((Hello,4), (World,3), (China,2), (Hi,1))
查看生成的DAG图
2. groupByKey
2.1 源码中介绍
/**
* Group the values for each key in the RDD into a single sequence. Hash-partitions the
* resulting RDD with the existing partitioner/parallelism level. The ordering of elements
* within each group is not guaranteed, and may even differ each time the resulting RDD is
* evaluated.
*
* @note This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using `PairRDDFunctions.aggregateByKey`
* or `PairRDDFunctions.reduceByKey` will provide much better performance.
*/
def groupByKey(): RDD[(K, Iterable[V])] = self.withScope {
groupByKey(defaultPartitioner(self))
}
源码中说了,此操作代价可能非常昂贵,对于求和或者求平均值的情况;她是将RDD中的每个key分组为单个序列
2.2 测试
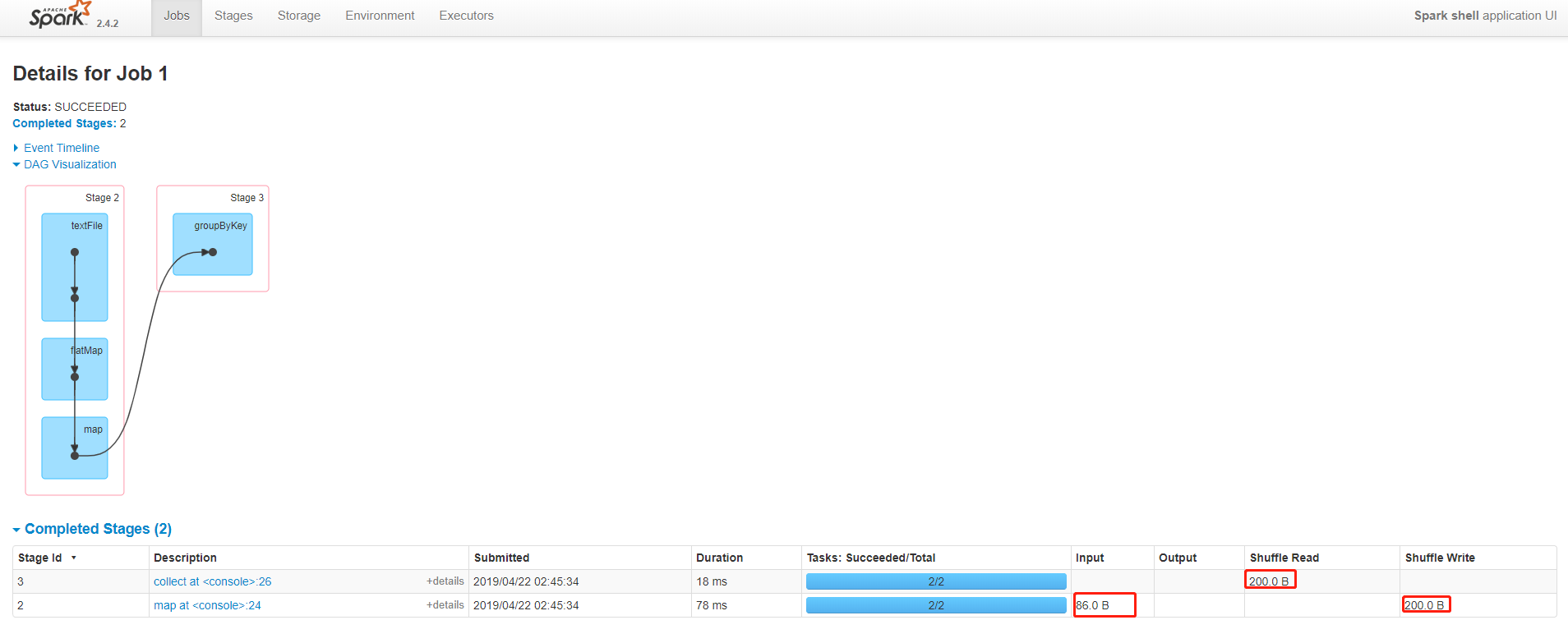
scala> val data = sc.textFile("file:///home/hadoop/data/wordcount.txt").flatMap(x=>x.split(",")).map((_,1)).groupByKey()
data: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[9] at groupByKey at <console>:24
scala> data.collect
res2: Array[(String, Iterable[Int])] = Array((Hello,CompactBuffer(1, 1, 1, 1)), (World,CompactBuffer(1, 1, 1)), (China,CompactBuffer(1, 1)), (Hi,CompactBuffer(1)))
scala> data.map(x=>(x._1,x._2.sum)).collect
res4: Array[(String, Int)] = Array((Hello,4), (World,3), (China,2), (Hi,1))
### 方法二,用reduce(_+_)
scala> val data = sc.textFile("file:///home/hadoop/data/wordcount.txt").flatMap(x=>x.split(",")).map((_,1)).groupByKey()
data: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[17] at groupByKey at <console>:24
scala> data.map(x=>(x._1,x._2.reduce(_+_)))
res16: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[18] at map at <console>:26
scala> data.map(x=>(x._1,x._2.reduce(_+_))).collect
res17: Array[(String, Int)] = Array((Hello,4), (World,3), (China,2), (Hi,1))
查看生成的DAG图
2.3 reduceByKey与groupByKey的差异
根据DAG图可以看出来,reduceByKey在的shuffle数量明显小于groupByKey数量,因为在源码中已经做了说明,reduceByKey在每个mapper中进行合并然后发送到reducer,相当于MapReduce的combiner;而groupByKey在mapper中未做合并操作。
注意:reduceByKey和groupByKey都是PairRDDFunctions类里面的
2.4 PairRDDFunctions类
**
* Extra functions available on RDDs of (key, value) pairs through an implicit conversion.
*/
class PairRDDFunctions[K, V](self: RDD[(K, V)])
(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null)
extends Logging with Serializable {
PairRDDFunctions通过隐式转换在(键,值)对的RDD上可用的额外功能。
3. count算子
查看源码
/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
返回RDD元素中的个数
4. collect 算子
查看源码
/**
* Return an array that contains all of the elements in this RDD.
*
* @note This method should only be used if the resulting array is expected to be small, as
* all the data is loaded into the driver's memory.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
返回RDD中的所有元素,注意,这个方法仅当期望结果数组较小时才应使用此方法,因为所有数据都已加载到驱动程序的内存中。
注意:count和collect都是action算子,因为在源码中,他们都有runJob;也就是说action算子都有runJob方法