概述
由于生产中大多数情况是用的自己编译的Spark版本,编译的Spark中并没有日志目录,对应用程序的日志没有记录;用二进制tar包解压即可用的 Spark中是有logs目录的;在Hadoop中也有 mr-jobhistory-daemon.sh,她用于查看历史的Job情况,同理在Spark中也有Spark HistoryServer。
Web Interfaces方式的监控
配置history job
# 在$SPARK_HOME/conf/spark-defaults.conf中配置如下参数
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop001:8020/SparkLog
修改spark-env.sh
# 在$SPARK_HOME/conf/spark-env.sh 中添加如下内容
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop001:8020/SparkLog"
启动
$SPARK_HOME/sbin/start-history-server.sh
查看进程
[hadoop@hadoop001 sbin]$ jps
5458 DataNode
5666 SecondaryNameNode
6644 Jps
6486 HistoryServer
5928 NodeManager
5355 NameNode
5820 ResourceManager
4862 SparkSubmit
查看后台日志
[hadoop@hadoop001 spark-2.4.2-bin-2.6.0-cdh5.7.0]$ ll
total 60
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 12 08:31 bin
drwxrwxr-x. 2 hadoop hadoop 4096 Apr 22 08:37 conf
drwxr-xr-x. 5 hadoop hadoop 4096 Apr 12 08:31 data
drwxrwxr-x. 4 hadoop hadoop 4096 Apr 12 08:31 examples
drwxrwxr-x. 2 hadoop hadoop 16384 Apr 12 08:31 jars
drwxrwxr-x. 4 hadoop hadoop 4096 Apr 12 08:31 kubernetes
drwxrwxr-x. 2 hadoop hadoop 4096 Apr 22 08:37 logs
drwxr-xr-x. 7 hadoop hadoop 4096 Apr 12 08:31 python
-rw-r--r--. 1 hadoop hadoop 3952 Apr 12 08:31 README.md
-rw-rw-r--. 1 hadoop hadoop 149 Apr 12 08:31 RELEASE
drwxr-xr-x. 2 hadoop hadoop 4096 Apr 12 08:31 sbin
drwxrwxr-x. 2 hadoop hadoop 4096 Apr 12 08:31 yarn
[hadoop@hadoop001 spark-2.4.2-bin-2.6.0-cdh5.7.0]$
### 注意:以前是没有logs目录的
[hadoop@hadoop001 spark-2.4.2-bin-2.6.0-cdh5.7.0]$ cd logs/
[hadoop@hadoop001 logs]$ tail -f 20 spark-hadoop-org.apache.spark.deploy.history.HistoryServer-1-hadoop00
1.out
tail: cannot open `20' for reading: No such file or directory
==> spark-hadoop-org.apache.spark.deploy.history.HistoryServer-1-hadoop001.out <==
19/04/22 08:37:18 INFO server.Server: jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown
19/04/22 08:37:18 INFO server.Server: Started @4420ms
19/04/22 08:37:18 INFO server.AbstractConnector: Started ServerConnector@58a55449{HTTP/1.1,[http/1.1]}{0.0.0.0:18080}
19/04/22 08:37:18 INFO util.Utils: Successfully started service on port 18080.
19/04/22 08:37:18 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@e72dba7{/,null,AVAILABLE,@Spark}
19/04/22 08:37:18 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5cbf9e9f{/json,null,AVAILABLE,@Spark}
19/04/22 08:37:18 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@18e8473e{/api,null,AVAILABLE,@Spark}
19/04/22 08:37:18 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@42deb43a{/static,null,AVAILABLE,@Spark}
19/04/22 08:37:18 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3301500b{/history,null,AVAILABLE,@Spark}
19/04/22 08:37:18 INFO history.HistoryServer: Bound HistoryServer to 0.0.0.0, and started at http://hadoop001:18080
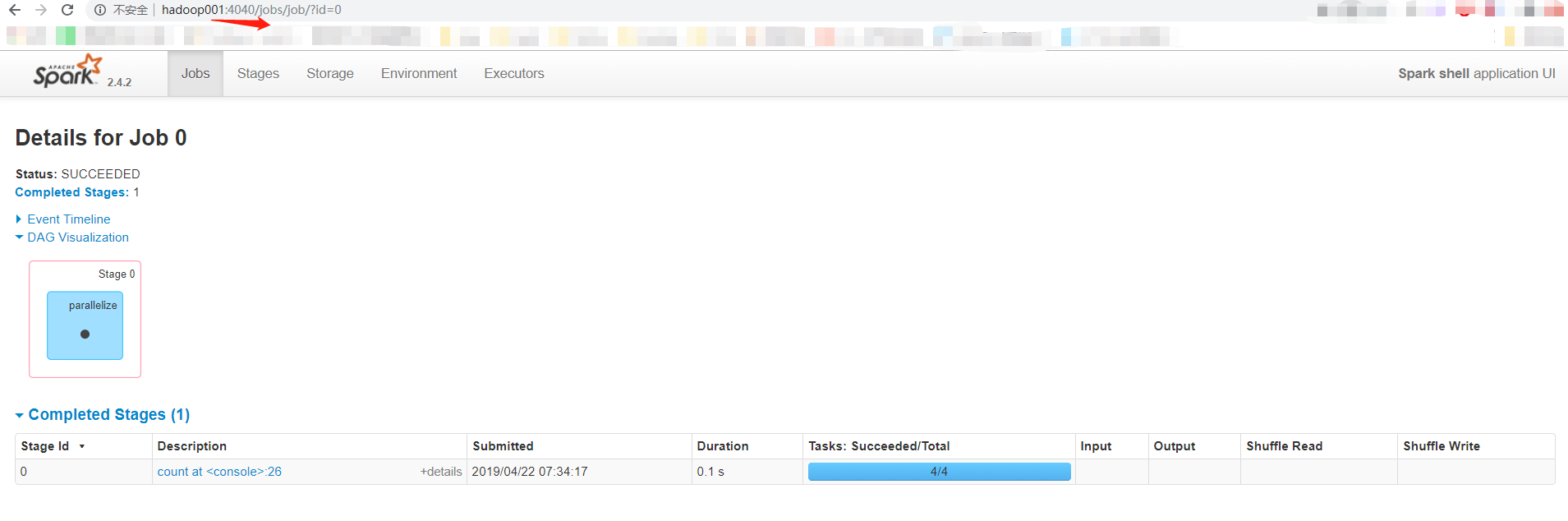
在spark-shell中启动一个spark程序
scala> sc.parallelize(List(1,2,3,4)).count
res0: Long = 4
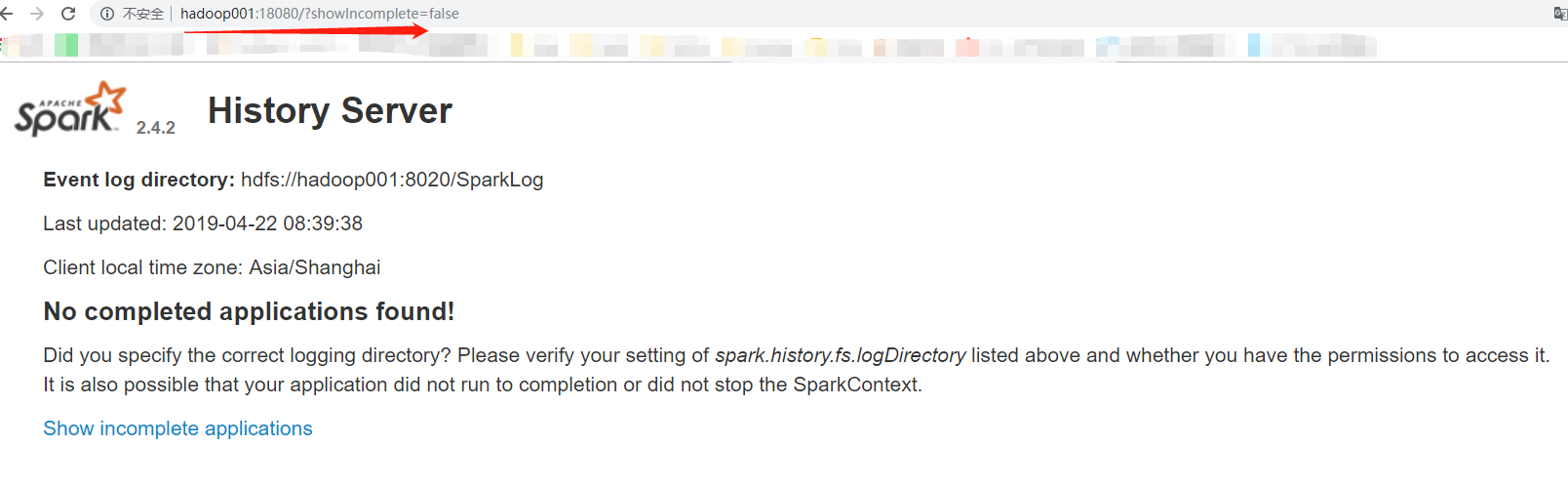
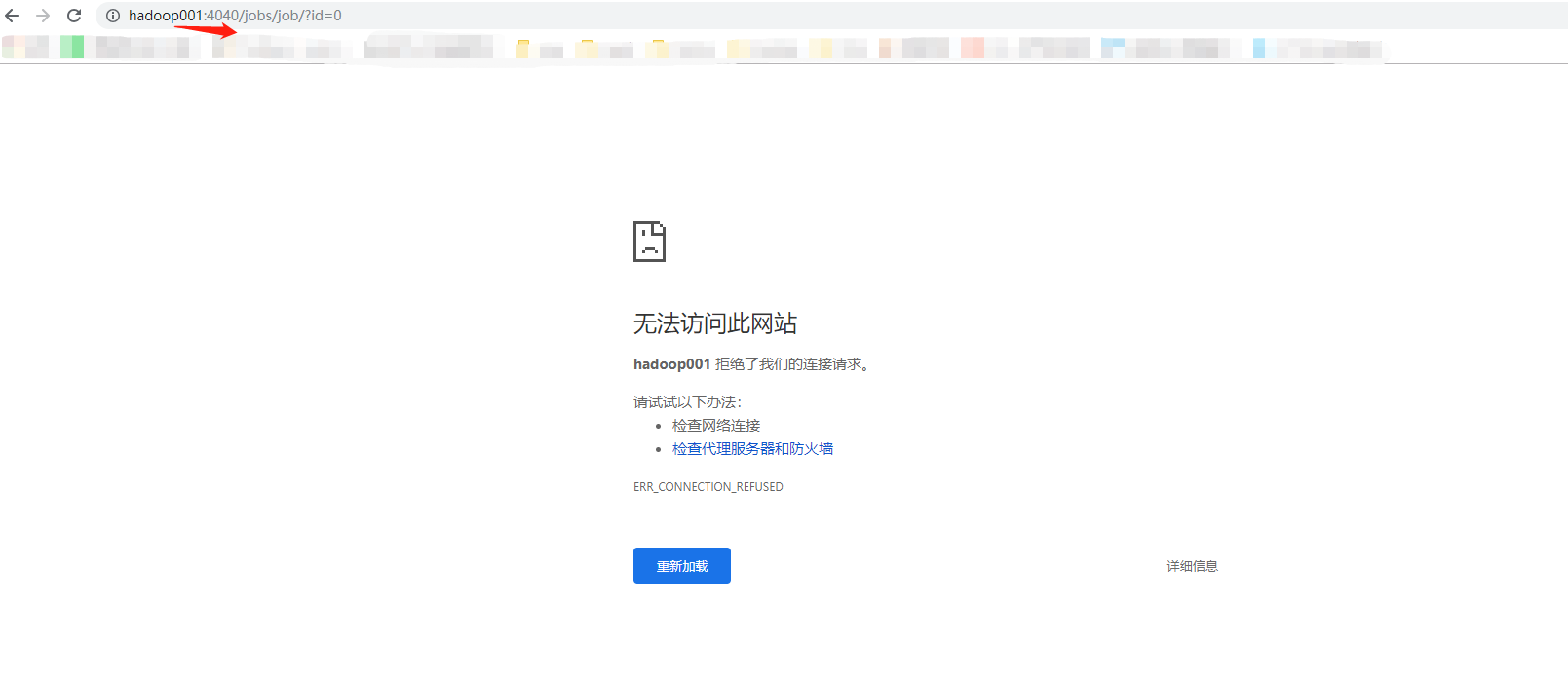
在4040上查看
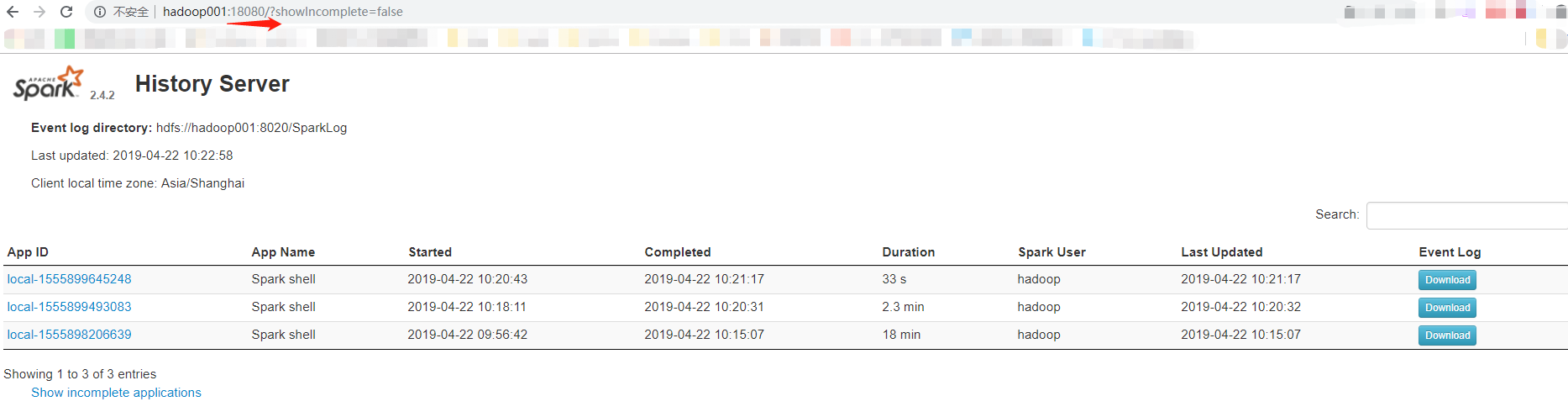
在18080上查看
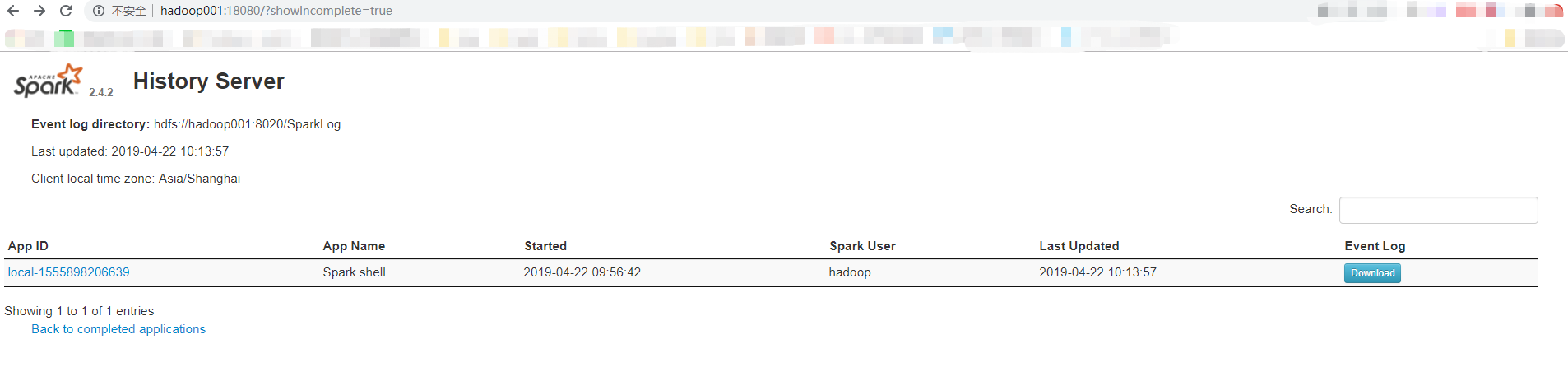
停掉sc
scala> sc.stop
在4040上查看
在18080上查看,发现还是可以打开的
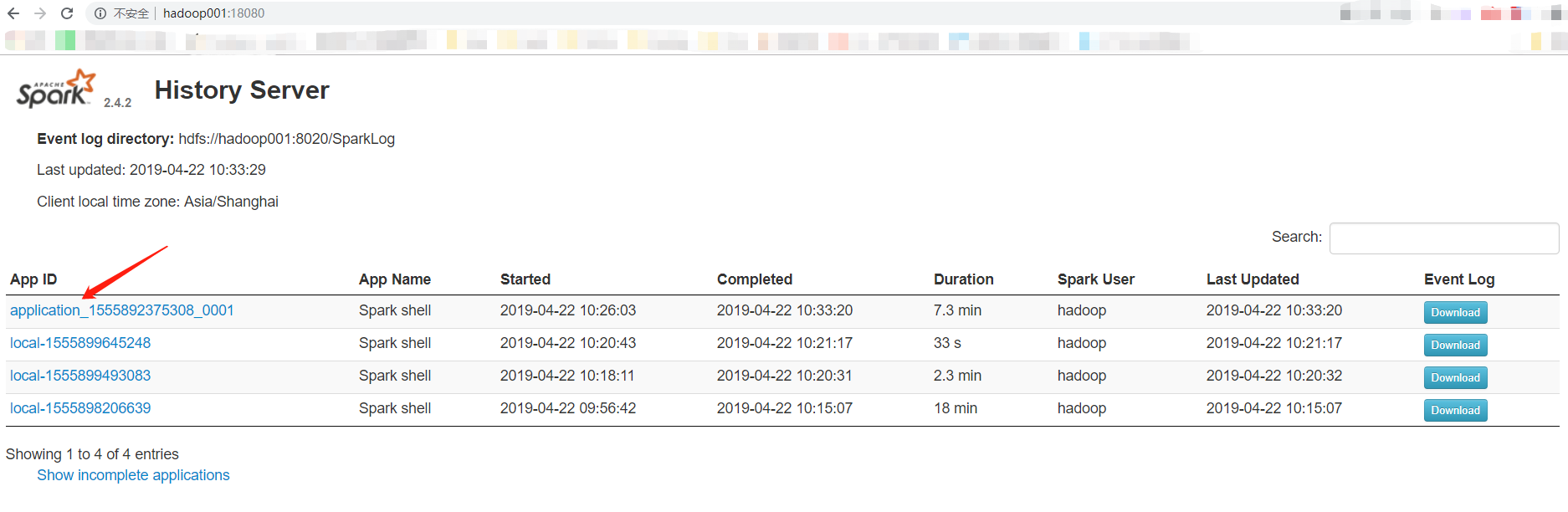
注意:以local模式的local,以yarn模式的为app
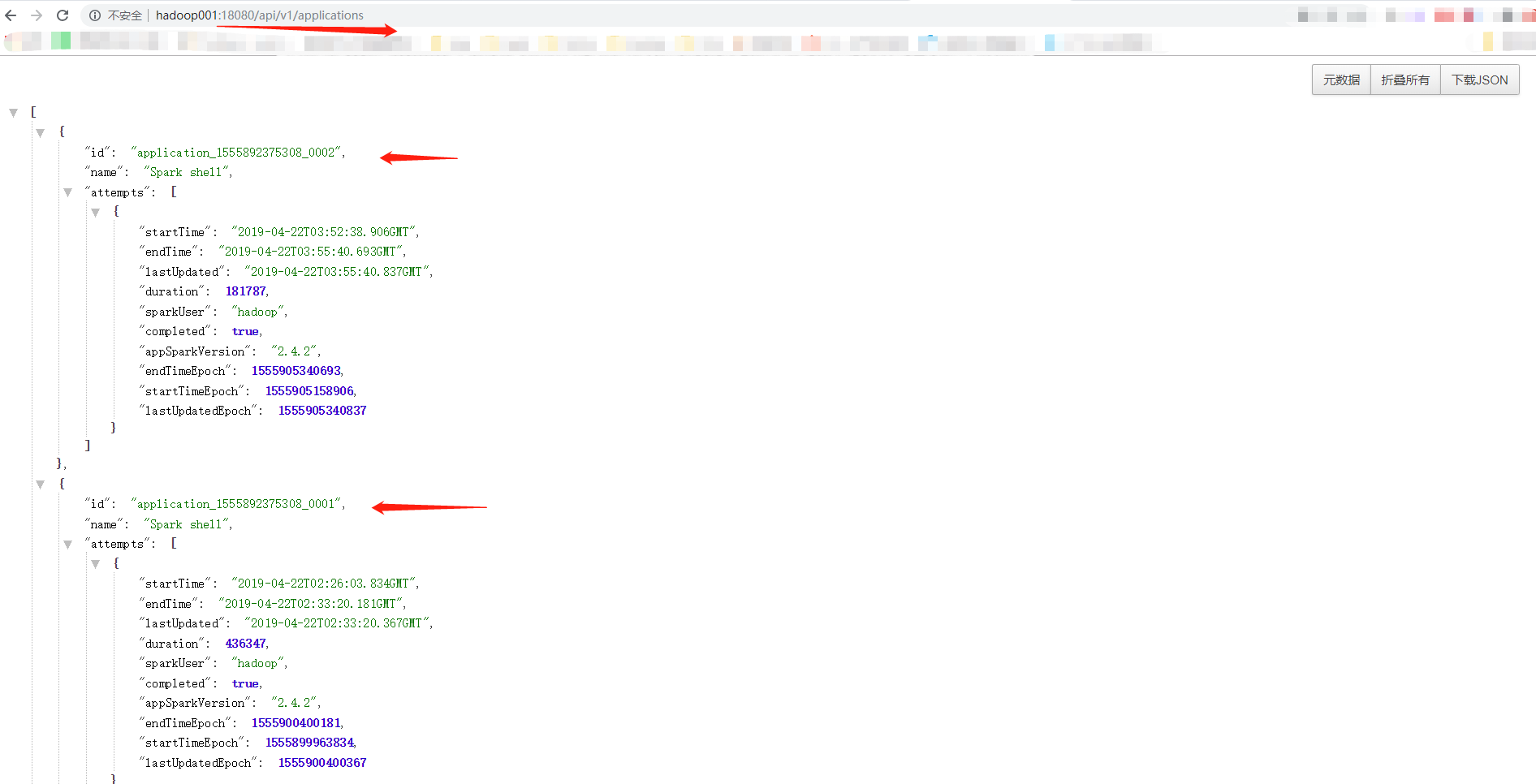
REST API
在4040/api/v1/applications
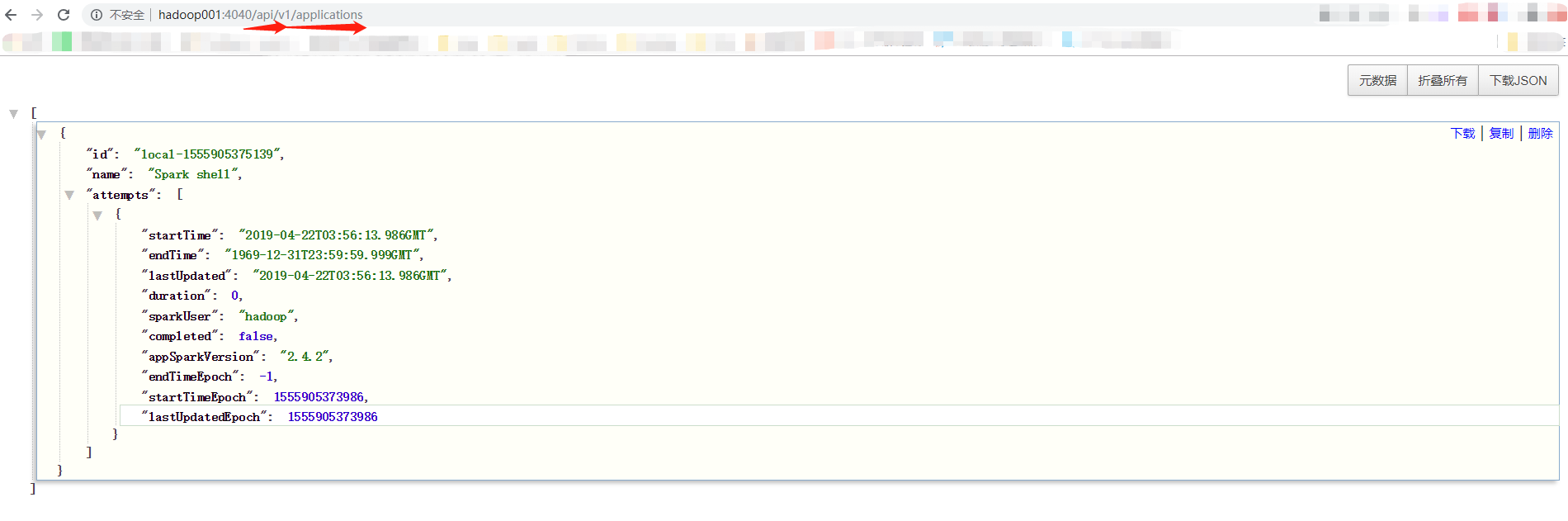
还可以加上其他的参数参看,比如/applications/[app-id]/jobs 等等, 具体的参数详见官网
也可以在18080上查看历史的信息