共享变量
首先来看官方的描述
Normally, when a function passed to a Spark operation (such as map or reduce) is executed on a remote cluster node, it works on separate copies of all the variables used in the function. These variables are copied to each machine, and no updates to the variables on the remote machine are propagated back to the driver program. Supporting general, read- write shared variables across tasks would be inefficient. However, Spark does provide two limited types of shared variables for two common usage patterns: broadcast variables and accumulators.
中文解释
通常,当在远程集群节点上执行传递给Spark操作(例如map或reduce)的函数时,它将在函数中使用的所有变量的单独副本上工作。 这些变量将复制到每台计算机,并且远程计算机上的变量的更新不会传播回驱动程序。 支持跨任务的通用,读写共享变量效率低下。 但是,Spark确实为两种常见的使用模式提供了两种有限类型的共享变量:广播变量和累加器。
累加器
首先看官方描述
Accumulators are variables that are only “added” to through an associative and commutative operation and can therefore be efficiently supported in parallel. They can be used to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric types, and programmers can add support for new types.
As a user, you can create named or unnamed accumulators. As seen in the image below, a named accumulator (in this instance counter) will display in the web UI for the stage that modifies that accumulator. Spark displays the value for each accumulator modified by a task in the “Tasks” table.
中文解释
累加器是仅通过关联和交换操作“添加”的变量,因此可以并行有效地支持。 它们可用于实现计数器(如MapReduce)或总和。 Spark本身支持数值类型的累加器,程序员可以添加对新类型的支持。
作为用户,您可以创建命名或未命名的累加器。 如下图所示,命名累加器(在此实例计数器中)将显示在Web UI中,用于修改该累加器的阶段。 Spark显示“任务”表中任务修改的每个累加器的值。
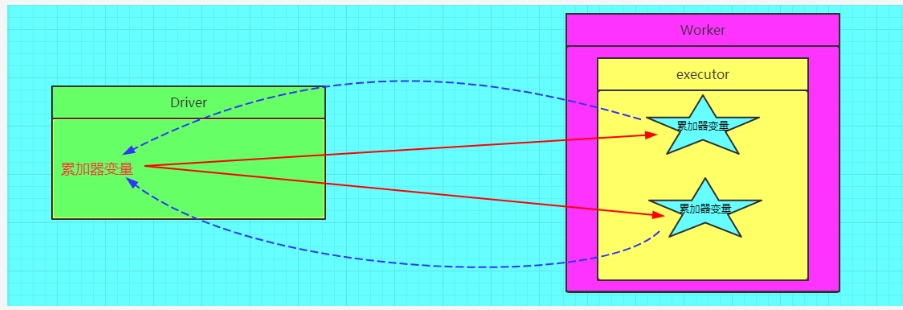
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能。但是确给我们提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取它的值。只有Driver程序可以读取Accumulator的值。
非常类似于在MR中的一个Counter计数器,主要用于统计各个程序片段被调用的次数,和整体进行比较,来对数据进行一个评估。
测试代码1:
// 创建一个accumulator变量,即累加器变量
scala> val acc = sc.accumulator(0, "Accumulator")
warning: there were two deprecation warnings; re-run with -deprecation for details
acc: org.apache.spark.Accumulator[Int] = 0
// add方法可以相加
scala> sc.parallelize(Array(1,2,3,4,5)).foreach(x => acc.add(x))
scala> acc
res13: org.apache.spark.Accumulator[Int] = 15
scala> acc.value
res14: Int = 15
// 也可以用"+="对累加器继续相加
scala> sc.parallelize(Array(1,2,3,4,5)).foreach(x => acc += x)
scala> acc
res16: org.apache.spark.Accumulator[Int] = 30
scala> acc.value
res17: Int = 30
在Web UI 上查看Stages
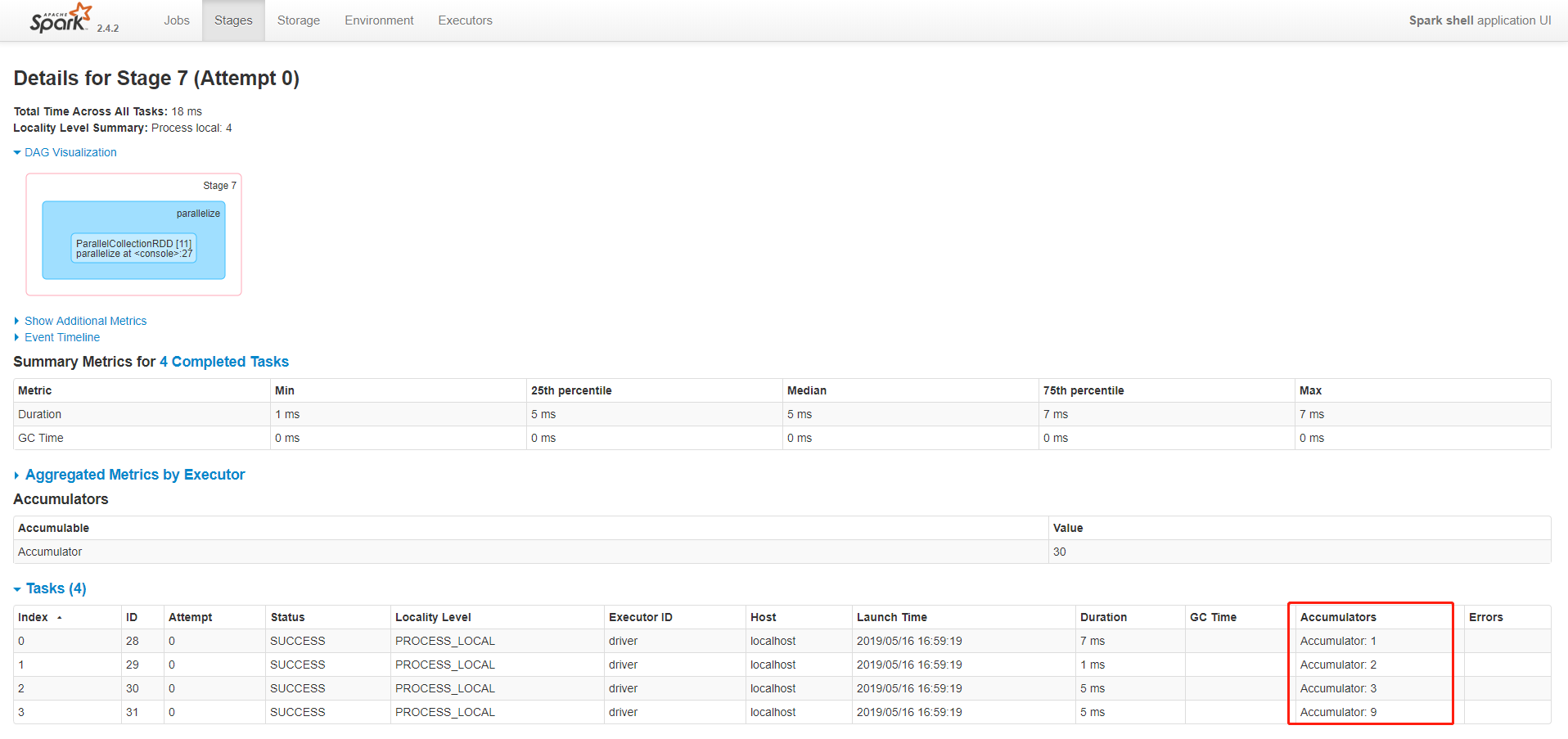
注意:累加器并没有改变Spark的lazy求值的模型。如果它们被RDD上的操作更新,它们的值只有当RDD为action算子被计算时才被更新。因此,当执行一个惰性的转换操作,比如map时,不能保证对累加器值的更新被实际执行了。下面的代码可以清晰地看到此特点。
测试代码2:
scala> val data = sc.parallelize(Array(1, 2, 3))
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:24
scala> data.map(x => acc += x)
res18: org.apache.spark.rdd.RDD[Unit] = MapPartitionsRDD[13] at map at <console>:28
// 由此可见acc的值未改变
scala> acc.value
res19: Int = 30
scala> acc
res20: org.apache.spark.Accumulator[Int] = 30
特别注意:
- 累加器的值只有在驱动器程序中访问,所以检查也应当在驱动器程序中完成。
- 对于行动操作中使用的累加器,Spark只会把每个任务对各累加器的修改应用一次。因此如果想要一个无论在失败还是在重新计算时候都绝对可靠的累加器,必须把它放在foreach()这样的行动操作中。
测试代码2:对每个元素乘以3,并且求出可以被7整除的个数
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark共享变量之累加器Accumulator
*
* 需要注意的是,累加器的执行必须需要Action触发
*/
object _04SparkAccumulatorOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(_01SparkPersistOps.getClass.getSimpleName())
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
// 要对这些变量都*7,同时统计能够被3整除的数字的个数
val list = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13)
val listRDD:RDD[Int] = sc.parallelize(list)
var counter = 0 //外部变量
val counterAcc = sc.accumulator[Int](0)
val mapRDD = listRDD.map(num => {
counter += 1
if(num % 3 == 0) {
counterAcc.add(1)
}
num * 7
})
mapRDD.foreach(println)
println("counter===" + counter)
println("counterAcc===" + counterAcc.value)
sc.stop()
}
}
输出结果为:
49
56
7
63
14
70
21
77
28
84
35
91
42
counter===0
counterAcc===4
图解累加器
广播变量
首先看官网的介绍
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost.
Spark提供的Broadcast Variable,是只读的。并且在每个节点上只会有一份副本,而不会为每个task都拷贝一份副本。因此其最大作用,就是减少 变量到各个节点的网络传输消耗,以及在各个节点上的内存消耗。此外,spark自己内部也使用了高效的广播算法来减少网络消耗。
测试代码1:
// 定义一个广播变量
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(8)
// 取出广播变量对应的值
scala> broadcastVar.value
res21: Array[Int] = Array(1, 2, 3)
测试代码2:
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.{SparkConf, SparkContext}
object SampleSpark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${SampleSpark.getClass.getSimpleName}")
.setMaster("local[2]")
val sc = new SparkContext(conf)
val genderMap = Map("0" -> "女", "1" -> "男")
val genderMapBC:Broadcast[Map[String, String]] = sc.broadcast(genderMap)
val rdd = sc.parallelize(Seq(("0", "Amy"), ("0", "Spring"), ("0", "Sunny"), ("1", "Mike"), ("1", "xpleaf")))
val retRDD = rdd.map{
case (sex, name) =>
val genderMapValue = genderMapBC.value
(genderMapValue.getOrElse(sex, "男"), name)
}
retRDD.foreach(println)
sc.stop()
}
}
输出结果:
(女,Amy)
(女,Sunny)
(女,Spring)
(男,Mike)
(男,xpleaf)
测试代码3:普通的Join
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastAPP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("BroadcastAPP").setMaster("local[2]")
val sc = new SparkContext(conf)
commonJoin(sc)
sc.stop()
}
def commonJoin(sc:SparkContext):Unit = {
val data1 = sc.parallelize(List(("1","A"),("2","B")))
val data2 = sc.parallelize(List(("1","C"),("3","D"),("4","E")))
data1.join(data2).foreach(println)
}
}
测试结果:
(1,(A,C))
测试代码4:Value个数不一样的Join:
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastAPP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("BroadcastAPP").setMaster("local[2]")
val sc = new SparkContext(conf)
commonJoin(sc)
sc.stop()
}
def commonJoin(sc:SparkContext):Unit = {
val data1 = sc.parallelize(List(("1","A"),("2","B")))
val data2 = sc.parallelize(List(("1","C","20"),("3","D","21"),("4","E","22")))
.map(x=>(x._1,x))
data1.join(data2).foreach(println)
}
}
输出结果为:
(1,(A,(1,C,20)))
测试代码5:基于测试4中的Join
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastAPP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("BroadcastAPP").setMaster("local[2]")
val sc = new SparkContext(conf)
commonJoin(sc)
sc.stop()
}
def commonJoin(sc:SparkContext):Unit = {
val data1 = sc.parallelize(List(("1","A"),("2","B")))
val data2 = sc.parallelize(List(("1","C","20"),("3","D","21"),("4","E","22")))
.map(x=>(x._1,x))
data1.join(data2).map(x=>{
x._1 + "," + x._2._1 + "," + x._2._2._2
}).foreach(println)
}
}
测试结果为:
1,A,C
在测试5中的代码加上Thread.sleep(2000000);可以通过Spark Web UI查看DAG图
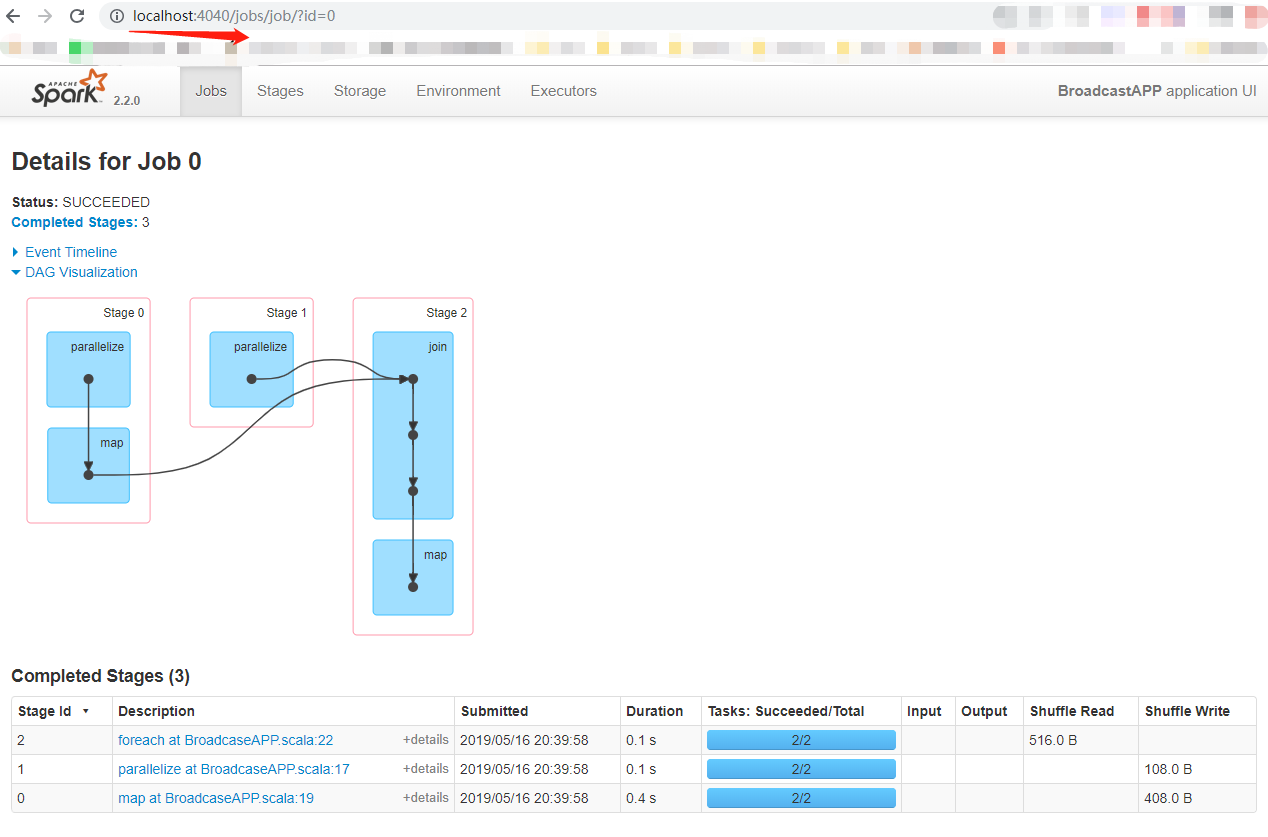
可以从上面的DAG图形中发现,Join是会产生shuffle的
测试代码6:使用广播变量来Join
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastAPP {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("BroadcastAPP").setMaster("local[2]")
val sc = new SparkContext(conf)
broadcastJoin(sc)
Thread.sleep(200000)
sc.stop()
}
def broadcastJoin(sc:SparkContext):Unit = {
// 把小表广播出去
val data1 = sc.parallelize(List(("1","A"),("2","B")))
.collectAsMap() //得到了map()类型,最后可以通过get(key)得到value
val data1Broadcast = sc.broadcast(data1)
// 大表
val data2 = sc.parallelize(List(("1","C","20"),("3","D","21"),("4","E","22")))
.map(x=>(x._1,x))
// Broadcast出去以后就不会再用join来实现,大表的数据读取出来一条就和广播出去的小表的记录做匹配
data2.mapPartitions(x=>{
val broadcastMap = data1Broadcast.value
for((key,value) <- x if (broadcastMap.contains(key)))
yield (key,broadcastMap.get(key).getOrElse(""),value._2)
}).foreach(println)
}
}
测试结果为:
1,A,C
使用广播变量Join查看DAG图形:
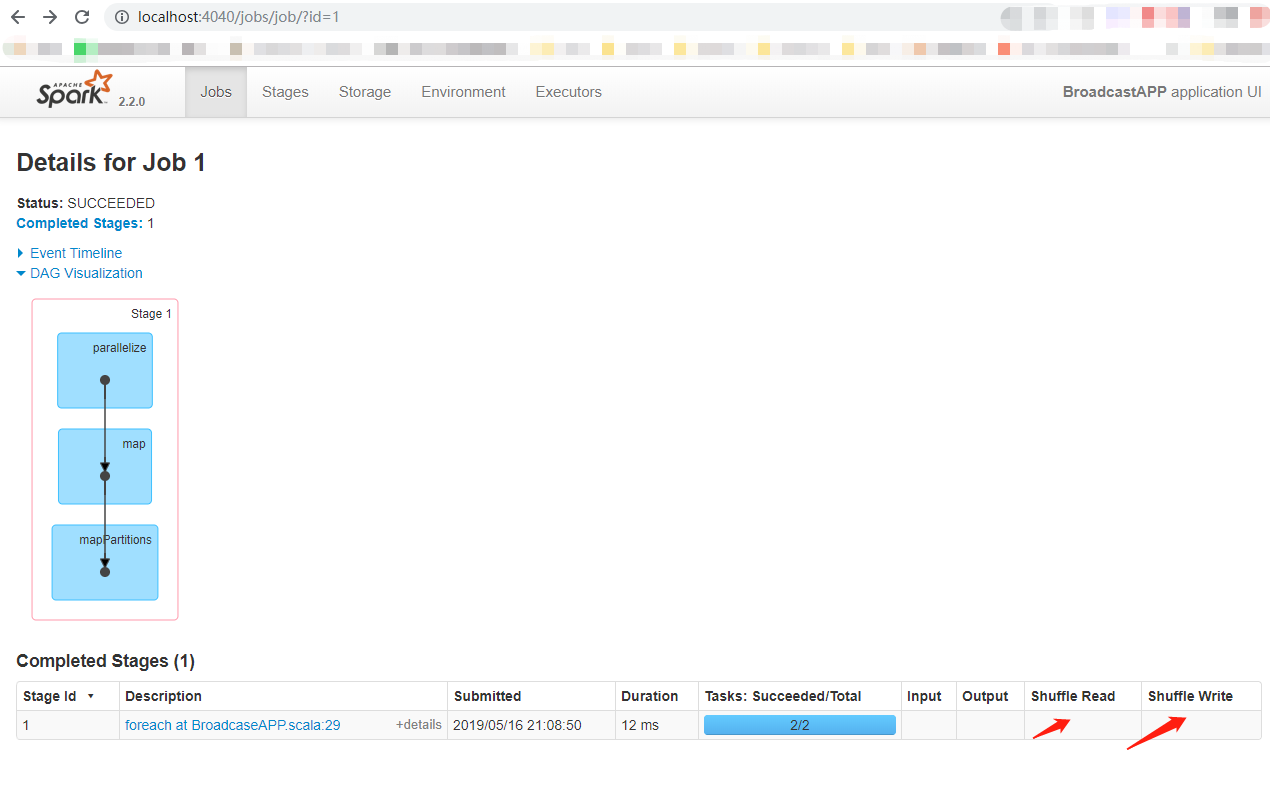
注意:通过上面的例子,可以发现,运用广播变量来处理Join操作,不会产生Shuffle。使用方法为Broadcast出去以后就不会再用join来实现,大表的数据读取出来一条就和广播出去的小表的记录做匹配
广播变量的具体实现原理
通过上述的代码来分析,假如在执行map操作时,在某个Worker的一个Executor上有分配5个task来进行计算,在不使用广播变量的情况下,因为Driver会将我们的代码通过DAGScheduler划分会不同stage,交由taskScheduler,taskScheduler再将封装好的一个个task分发到Worker的Excutor中,也就是说,这个过程当中,我们的genderMap也会被封装到这个task中,显然这个过程的粒度是task级别的,每个task都会封装一个genderMap,在该变量数据量不大的情况下,是没有问题的,然后,当数据量很大时,同时向一个Excutor上传递5份这样相同的数据,这是很浪费网络中的带宽资源的;广播变量的使用可以避免这一问题的发生,将genderMap广播出去之后,其只需要发送给Excutor即可,它会保存在Excutor的BlockManager中,此时,Excutor下面的task就可以共享这个变量了,这显然可以带来一定性能的提升。
图解广播变量
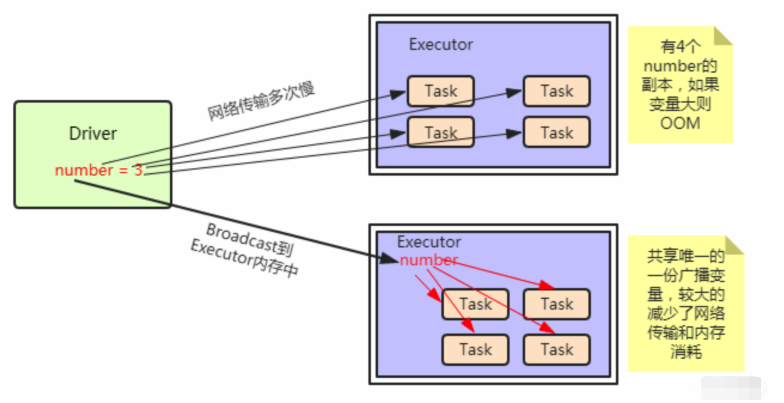
不使用广播变量的时候
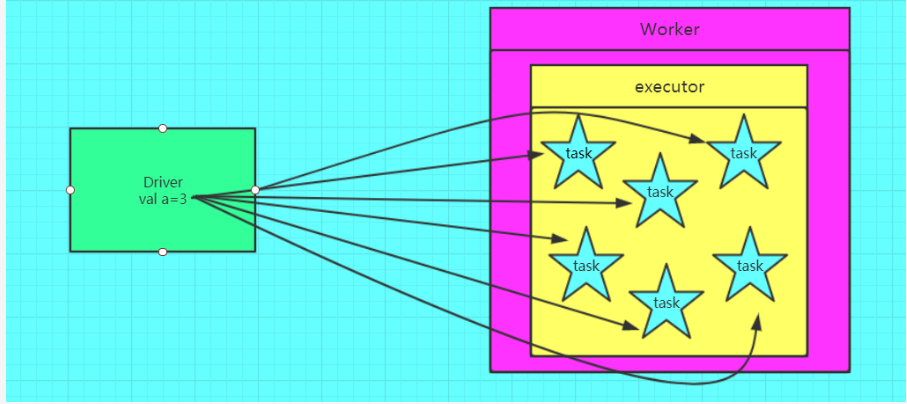
使用广播变量的时候
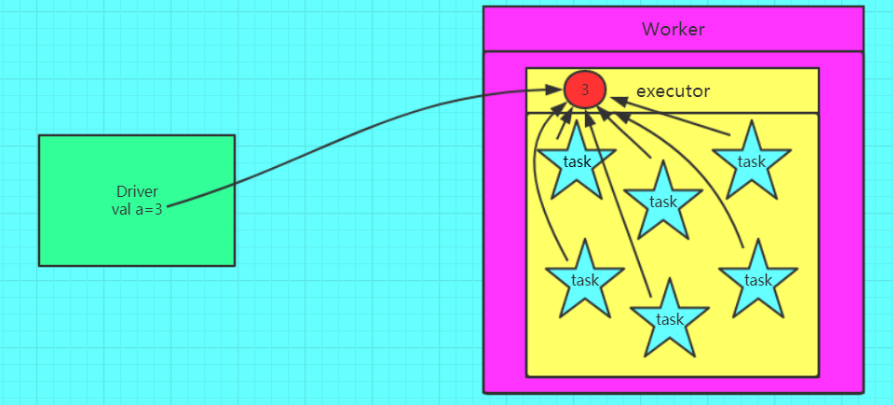
关于广播变量的问题思考
-
问题:为什么只能 broadcast 只读的变量?
这就涉及一致性的问题,如果变量可以被更新,那么一旦变量被某个节点更新,其他节点要不要一块更新?如果多个节点同时在更新,更新顺序是什么?怎么做同步?还会涉及 fault-tolerance 的问题。为了避免维护数据一致性问题,Spark 目前只支持 broadcast 只读变量。
-
问题:broadcast 到节点而不是 broadcast 到每个 task?
因为每个 task 是一个线程,而且同在一个进程运行 tasks 都属于同一个 application。因此每个节点(executor)上放一份就可以被所有 task 共享。
-
问题: 具体怎么用 broadcast?
driver program 例子:
val data = List(1, 2, 3, 4, 5, 6) val bdata = sc.broadcast(data) val rdd = sc.parallelize(1 to 6, 2) val observedSizes = rdd.map(_ => bdata.value.size)driver 使用
sc.broadcast()声明要 broadcast 的 data,bdata 的类型是 Broadcast。当
rdd.transformation(func)需要用 bdata 时,直接在 func 中调用,比如上面的例子中的 map() 就使用了 bdata.value.size。
Spark闭包
什么叫闭包?
闭包:跨作用域访问函数变量。又指的一个拥有许多变量和绑定了这些变量的环境的表达式(通常是一个函数),因而这些变量也是该表达式的一部分。
Spark闭包的问题引出
问题1:在spark中实现统计List(1,2,3)的和。如果使用下面的代码,程序打印的结果不是6,而是0。这个和我们编写单机程序的认识有很大不同。为什么呢?
object Test {
def main(args:Array[String]):Unit = {
val conf = new SparkConf().setAppName("test");
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List(1,2,3))
var counter = 0
//warn: don't do this
rdd.foreach(x => counter += x)
println("Counter value: "+counter)
sc.stop()
}
}
问题分析:
counter是在foreach函数外部定义的,也就是说是在driver程序中定义的,而foreach函数是属于rdd对象的,rdd函数的执行位置是各个worker节点(或者说是worker进程),main函数是在driver节点上(或者说driver进程上)执行的,所以当counter变量在driver中定义,被在rdd中使用的时候,出现了变量的“跨越”问题,也就是闭包问题。
问题解释:
对于上面程序中的counter变量,由于在main函数和在rdd对象的foreach函数是属于不同的(闭包),所以,传进foreach中的counter是一个副本,初始值都为0。foreach中叠加的是counter的副本,不管副本如何变化,都不会影响到main函数中的counter,所以最终打印出来的connter是0。
Spark程序执行的顺序
当用户提交一个用Scala语言开发的Spark应用程序,Spark框架会调用哪些组件呢?首先,这个Spark程序就是一个”Application”,程序里面的main函数就是“Dirver Program”,前面已经讲到它的作用,只是,dirver程序的可能运行在客户端,也有可有可能运行在spark集群中,这取决于spark作业提交时参数的选定,比如,yarn-client和yarn-cluster就是分别运行在客户端和spark集群中。在driver程序中会有RDD对象的相关代码操作,比如下面代码的newRDD.map()。
newRDD.map()
class Test{
def main(args: Array[String]) {
val sc = new SparkContext(new SparkConf())
val newRDD = sc.textFile("")
newRDD.map(data => {
//do something
println(data.toString)
})
}
}
-
涉及到RDD的代码,比如上面RDD的map操作,它们是在Worker节点上面运行的,所以spark会透明地帮用户把这些涉及到RDD操作的代码传给相应的worker节点。如果在RDD map函数中调用了在函数外部定义的对象,
因为这些对象需要通过网络从driver所在节点传给其他的worker节点,所以要求这些类是可序列化的,比如在Java或者scala中实现Serializable类,除了java这种序列化机制,还可以选择其他方式,使得序列化工作更加高效。worker节点接收到程序之后,在spark资源管理器的指挥下运行RDD程序。不同worker节点之间的运行操作是并行的。 -
在worker节点上所运行的RDD中代码的变量是保存在worker节点上面的,在spark编程中,很多时候用户需要在driver程序中进行相关数据操作之后把该数据传给RDD对象的方法以做进一步处理,这时候,spark框架会自动帮用户把这些数据通过网络传给相应的worker节点。
除了这种以变量的形式定义传输数据到worker节点之外,spark还另外提供了两种机制,分别是broadcast和accumulator。相比于变量的方式,在一定场景下使用broadcast比较有优势,因为所广播的数据在每一个worker节点上面只存一个副本,而在spark算子中使用到的外部变量会在每一个用到它的task中保存一个副本,即使这些task在同一个节点上面。所以当数据量比较大的时候,建议使用广播而不是外部变量。