问题描述
Spark作业跑在yarn上的时候出现作业一直提交不上

查看Yarn的日志
[hadoop@hadoop001 logs]$ tail -200f yarn-hadoop-resourcemanager-hadoop001.log
2019-05-21 07:30:40,484 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl: container_1558394931560_0001_01_000002 Container Transitioned from ACQUIRED to RUNNING
2019-05-21 07:30:40,485 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl: container_1558394931560_0001_01_000003 Container Transitioned from NEW to ALLOCATED
2019-05-21 07:30:40,485 INFO org.apache.hadoop.yarn.server.resourcemanager.RMAuditLogger: USER=hadoop OPERATION=AM Allocated Container TARGET=SchedulerApp RESULT=SUCCESS APPID=application_1558394931560_0001 CONTAINERID=container_1558394931560_0001_01_000003
2019-05-21 07:30:40,485 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.SchedulerNode: Assigned container container_1558394931560_0001_01_000003 of capacity <memory:2048, vCores:1> on host hadoop001:43989, which has 3 containers, <memory:5120, vCores:3> used and <memory:3072, vCores:5> available after allocation
2019-05-21 07:30:42,084 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl: container_1558394931560_0001_01_000003 Container Transitioned from ALLOCATED to ACQUIRED
2019-05-21 07:30:42,489 INFO org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl: container_1558394931560_0001_01_000003 Container Transitioned from ACQUIRED to RUNNING
2019-05-21 07:30:45,104 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.AppSchedulingInfo: checking for deactivate...
2019-05-21 07:38:51,551 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.AbstractYarnScheduler: Release request cache is cleaned up
查看hdfs的块报告
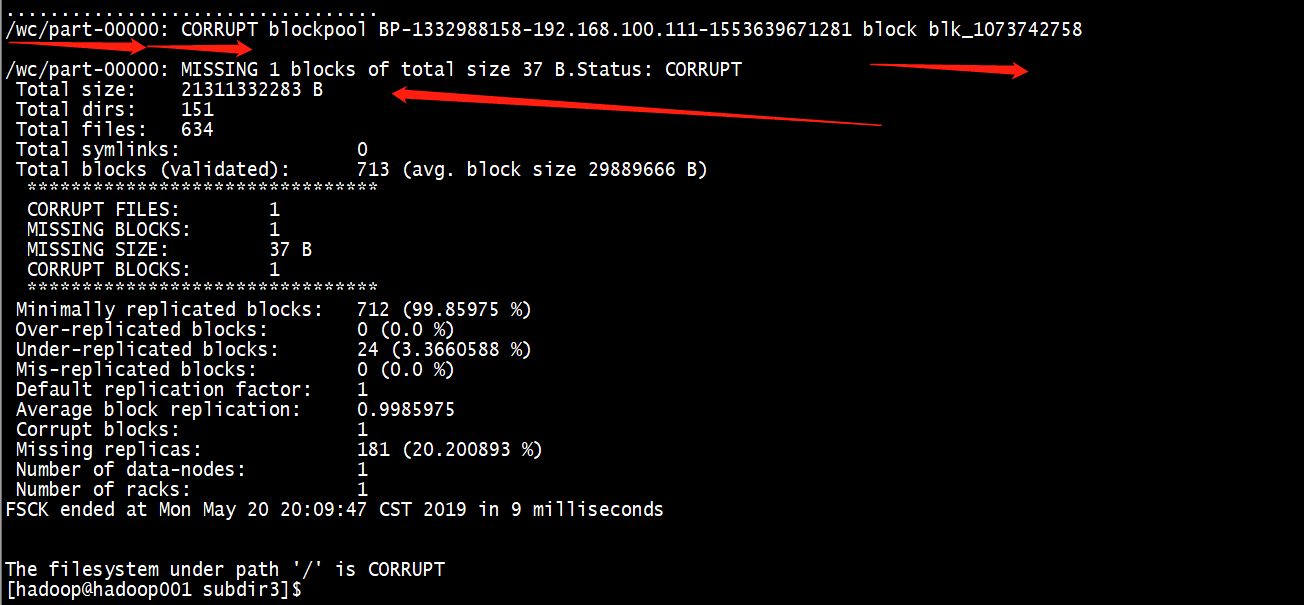
查看HDFS Web
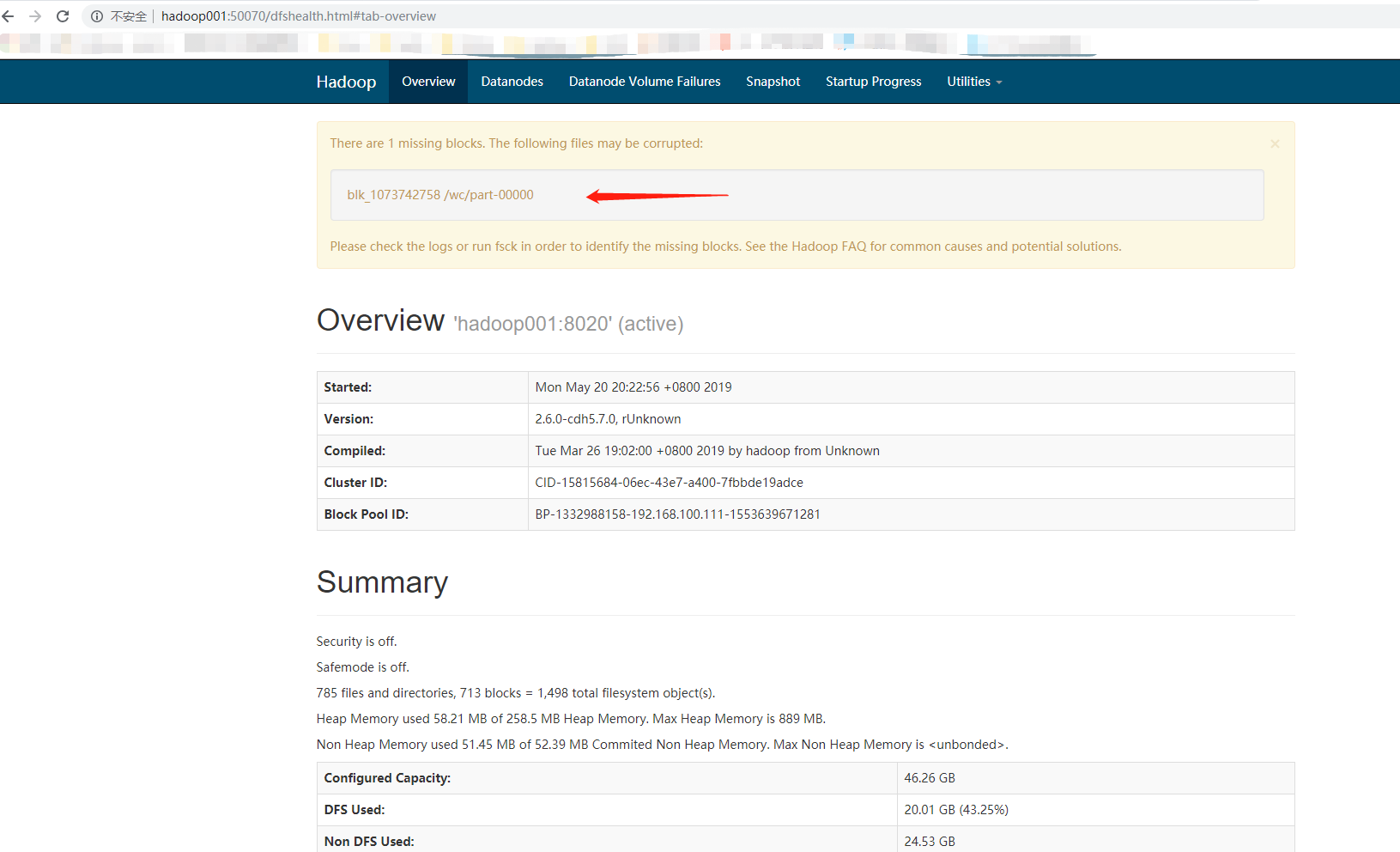
从上面的2张图片明确的说明了,块出现了问题
处理块丢失问题
处理块丢失问题,有2种方法;方法一是自动修复;方法二是手动修复
自动修复,在hdfs-site.xml文件添加如下内容
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>60</value>
</property>
<property>
<name>dfs.datanode.directoryscan.interval</name>
<value>1</value>
</property>
dfs.datanode.directoryscan.interval;当数据块损坏后,DataNode节点执行directoryscan操作之前,都不会发现损坏;也就是directoryscan操作的时间间隔默认是6小时;此参数的单位为分钟。
dfs.blockreport.intervalMsec;DN像NameNode进行blockreport前,都不会恢复数据块;也就是块报告操作间隔默认也是6小时,此参数的单位是秒。
把上面的参数修改为1分钟,然后重启HDFS,等一分钟后就会发现块修复了。
官方对两个参数的介绍 http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
方法二:手动修复
[hadoop@hadoop001 hadoop]$ hdfs debug recoverLease -path /wc/part-00000 -retries 10
然后查看HDFS的块情况
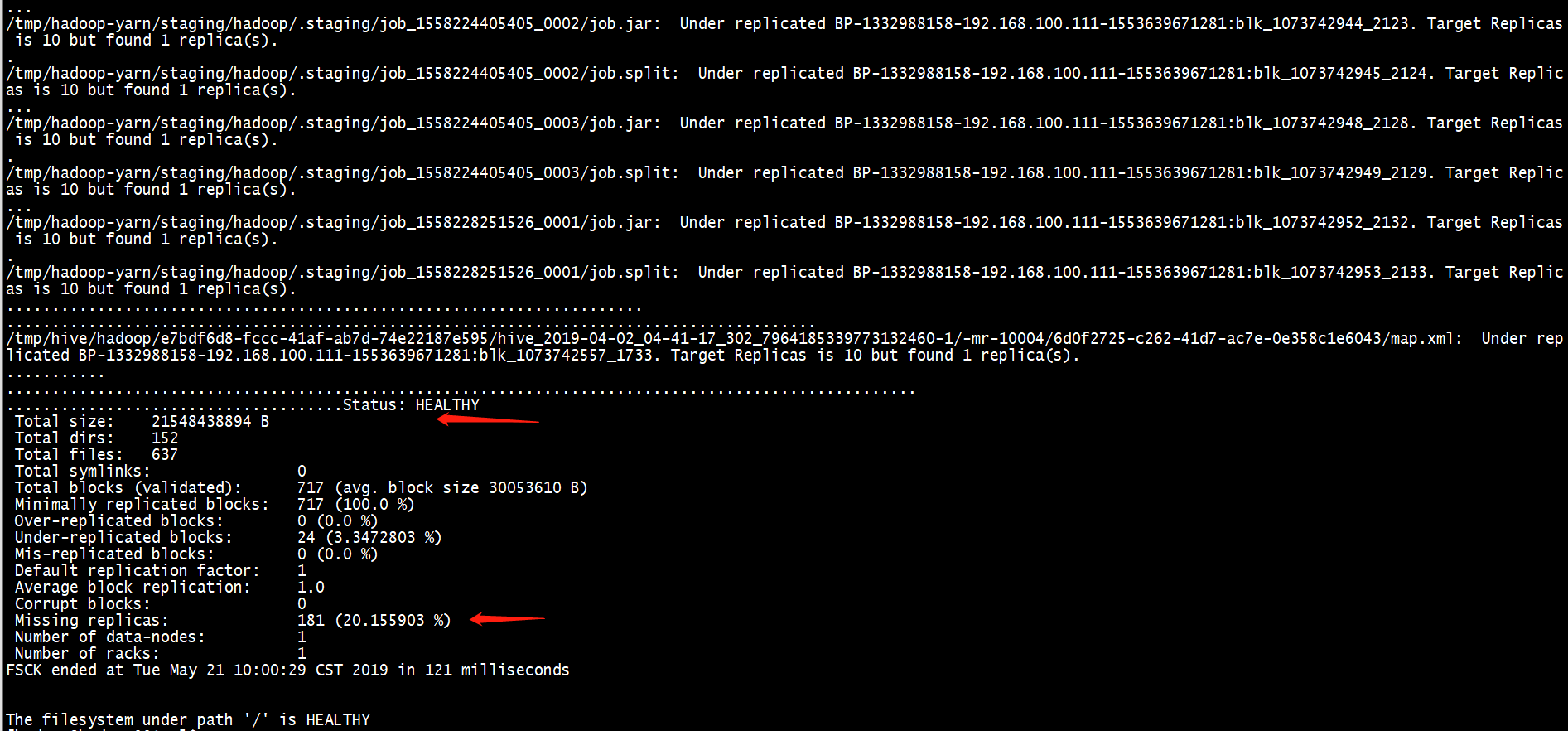
注意:我这个是伪分布式的测试环境,会显示出现Missing replicas的情况;但是Status为HEALTHY
Yarn节点出现了问题
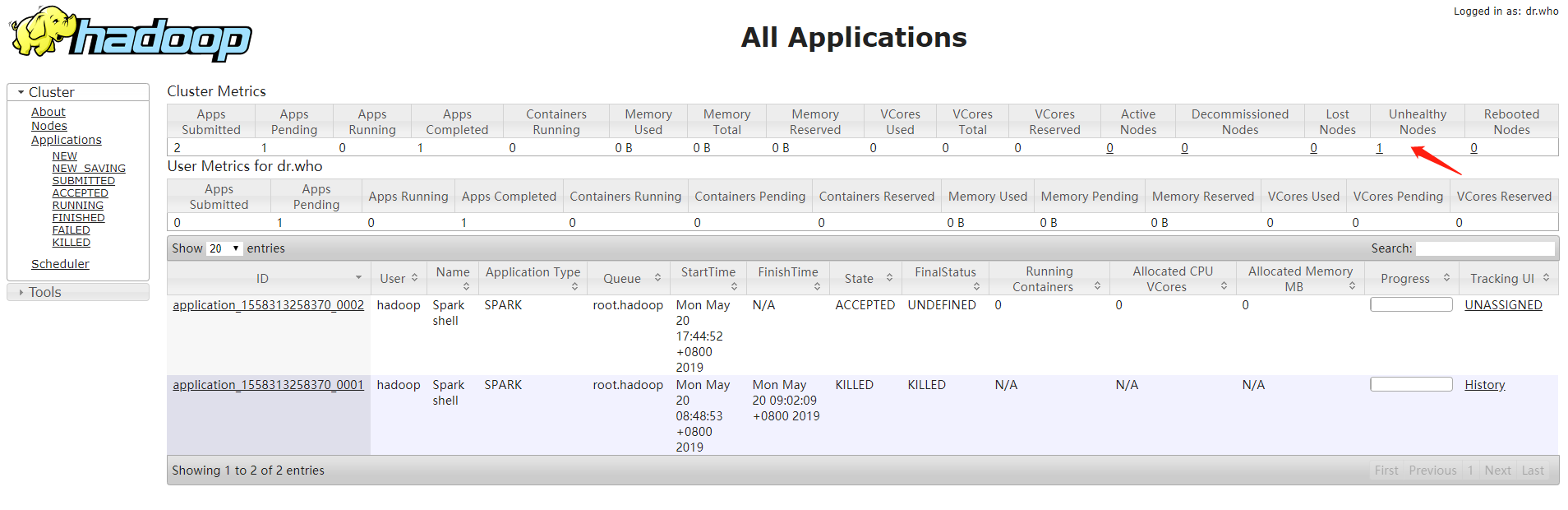
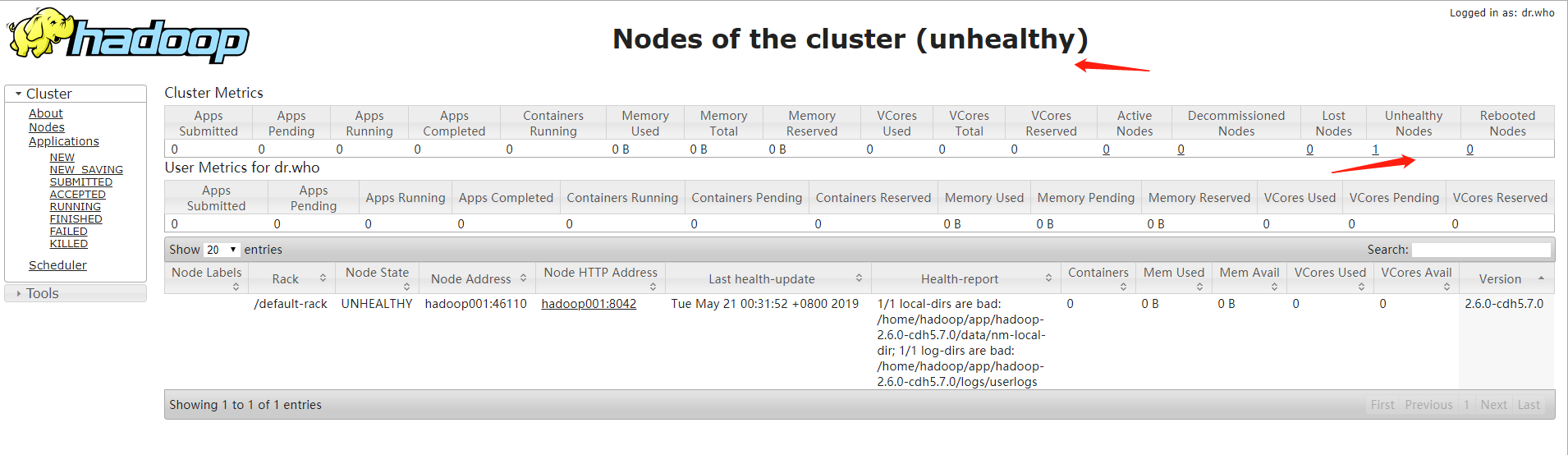
查看内存和磁盘情况
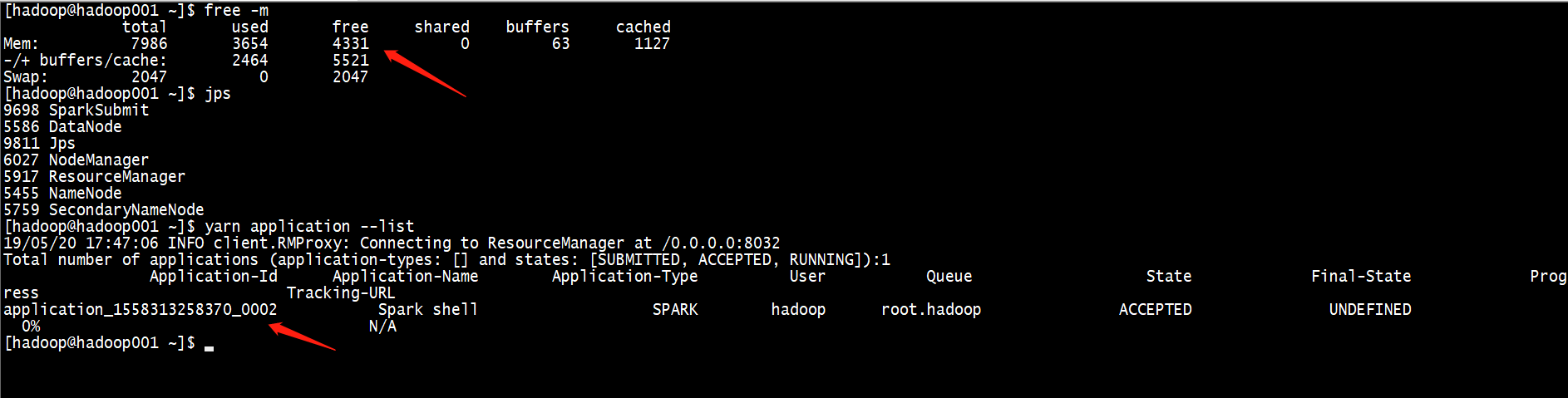
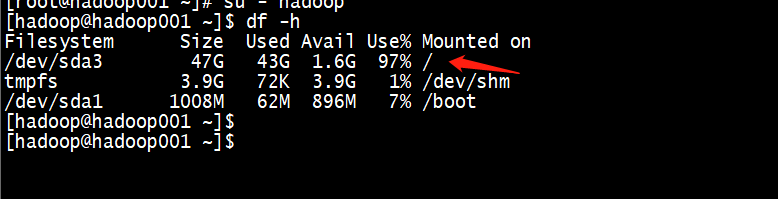
发现磁盘占用过高,超过了百分之九十,删掉一些磁盘文件,重启yarn
[hadoop@hadoop001 ~]$ stop-yarn.sh
[hadoop@hadoop001 ~]$ start-yarn.sh
再次查看yarn web,发现节点都健康运行
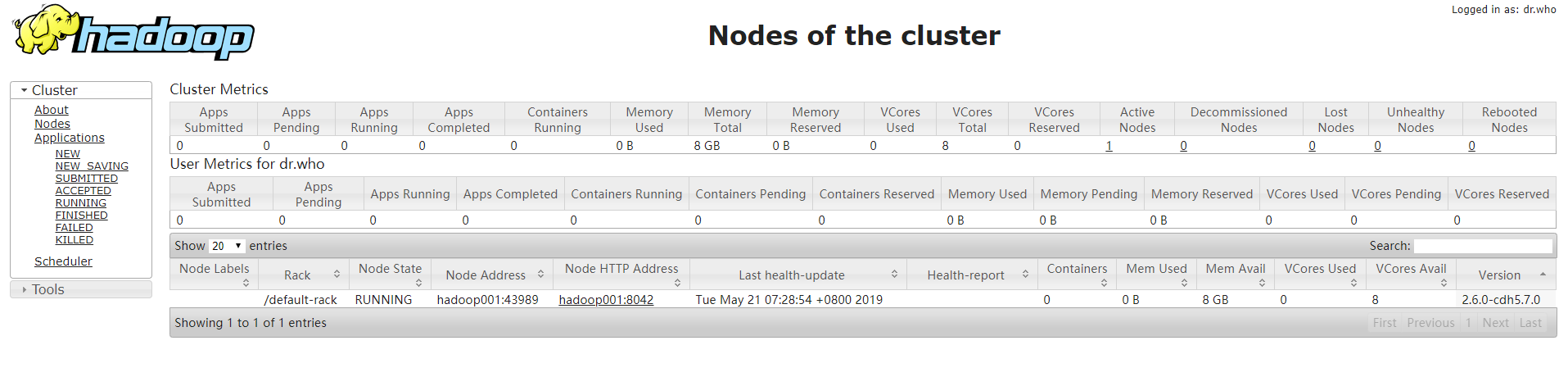
块扫描:https://blog.cloudera.com/blog/2016/12/hdfs-datanode-scanners-and-disk-checker-explained/
提交Spark作业到yarn上
[hadoop@hadoop001 ~]$ spark-shell --master yarn
总结
-
HDFS 出现块的损坏的情况,个人推荐使用手动修复,但是前提是要手动删除损坏的块文件和meta文件,这个是在Linux系统里面的对应的
注意:一定不要使用hdfs fsck / -delete,这是删除损坏额度文件,这样会直接导致数据丢失的,除非丢数据无所谓。 -
yarn出现不健康的节点,一般来说都是磁盘原因导致的,磁盘使用率超过百分之九十就会出现这种问题。