概述
Spark SQL 不仅仅是SQL,她还可以处理其他的结构化数据,如Orc/Parquet/JSON;她诞生于Spark 1.0,毕业于Spark 1.3;现在为Spark SQL, DataFrames and Datasets;以前就叫Spark SQL。
Hive On Spark 只需要设置为set hive.execution.engine=spark; 生产上慎用。

DataFrame是Spark1.3出来的;以前叫做SchemaRDD
DataFrame 和Pandas类似,但是Pandas是单机的,DataFrame是分布式的。DF可以等价为一张表,她是带有列名的。她提供了更多的关于数据结构和数据计算(列式存储,列式更快)的信息。
Dataset是Spark1.6出现的;她支持Scala和Java,但是不支持Python
在Scala API中,DataFrame = Dataset[Row]
Spark SQL操作Hive
[hadoop@hadoop001 conf]$ cp /home/hadoop/app/hive-1.1.0-cdh5.7.0/conf/hive-site.xml /home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/conf/
然后再启动Spark-shell;但是会发现报错,报错信息如下
Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BONECP" plugin to create a ConnectionPool gave an error : The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:259)
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.initialiseDataSources(ConnectionFactoryImpl.java:131)
at org.datanucleus.store.rdbms.ConnectionFactoryImpl.<init>(ConnectionFactoryImpl.java:85)
... 150 more
Caused by: org.datanucleus.store.rdbms.connectionpool.DatastoreDriverNotFoundException: The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASSPATH specification, and the name of the driver.
根据上面的错误信息可以发现是没有mysql驱动jar包
[hadoop@hadoop001 ~]$ spark-shell --jars ~/software/mysql-connector-java-5.1.43-bin.jar
.
.
scala> spark.sql("show tables").show
19/05/21 18:05:44 ERROR metastore.ObjectStore: Version information found in metastore differs 1.1.0 from expected schema version 1.2.0. Schema verififcation is disabled hive.metastore.schema.verification so setting version.
19/05/21 18:05:44 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
+--------+--------------------+-----------+
|database| tableName|isTemporary|
+--------+--------------------+-----------+
| default|page_views_rcfile...| false|
+--------+--------------------+-----------+
# 在show后面加上false参数
scala> spark.sql("show tables").show(false)
+--------+----------------------+-----------+
|database|tableName |isTemporary|
+--------+----------------------+-----------+
|default |page_views_rcfile_test|false |
+--------+----------------------+-----------+
scala> spark.sql("select * from page_views_rcfile_test limit 10").show(false)
+----------+---+----------+-------+---+-----------+-------+
|track_time|url|session_id|referer|ip |end_user_id|city_id|
+----------+---+----------+-------+---+-----------+-------+
+----------+---+----------+-------+---+-----------+-------+
scala> spark.sql("use hive")
res33: org.apache.spark.sql.DataFrame = []
scala> spark.sql("show tables").show
+--------+--------------------+-----------+
|database| tableName|isTemporary|
+--------+--------------------+-----------+
| hive| emp| false|
| hive| emp_external| false|
| hive| flow_info| false|
| hive| managed_emp| false|
| hive| order_partition| false|
| hive| page_views| false|
| hive| page_views_orc| false|
| hive| page_views_orc_none| false|
| hive| page_views_parquet| false|
| hive|page_views_parque...| false|
| hive| page_views_rc| false|
| hive|page_views_rcfile...| false|
| hive| page_views_seq| false|
| hive| t| false|
| hive| t1| false|
| hive| test| false|
| hive| version_test| false|
| | people| true|
+--------+--------------------+-----------+
注意:用--jars把mysql的驱动传递进去,不要用拷贝,因为这样的话可能会影响其他的作业运行。
还可以用$SPARK_HOME/bin/spark-sql操作
[hadoop@hadoop001 bin]$ ./spark-sql --jars ~/software/mysql-connector-java-5.1.43-bin.jar
按照上面的执行命令会报错,报错信息如下
Caused by: java.sql.SQLException: No suitable driver found for jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=false&characterEncoding=UTF-8
说是driver上连接不上jdbc;但是在spark-shell –help中说明了–jars可以传递到executor和driver的
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--driver-class-path Extra class path entries to pass to the driver. Note that jars added with --jars are automatically included in the classpath.
[hadoop@hadoop001 bin]$ ./spark-sql --jars ~/software/mysql-connector-java-5.1.43-bin.jar --driver-class-path ~/software/mysql-connector-java-5.1.43-bin.jar
.
.
spark-sql (default)> show tables;
19/05/21 18:25:08 INFO metastore.HiveMetaStore: 0: get_database: global_temp
19/05/21 18:25:08 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_database: global_temp
19/05/21 18:25:08 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
19/05/21 18:25:08 INFO metastore.HiveMetaStore: 0: get_database: default
19/05/21 18:25:08 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_database: default
19/05/21 18:25:08 INFO metastore.HiveMetaStore: 0: get_database: default
19/05/21 18:25:08 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_database: default
19/05/21 18:25:08 INFO metastore.HiveMetaStore: 0: get_tables: db=default pat=*
19/05/21 18:25:08 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_tables: db=default pat=*
19/05/21 18:25:08 INFO codegen.CodeGenerator: Code generated in 223.866114 ms
default page_views_rcfile_test false
Time taken: 2.13 seconds, Fetched 1 row(s)
19/05/21 18:25:08 INFO thriftserver.SparkSQLCLIDriver: Time taken: 2.13 seconds, Fetched 1 row(s)
spark-sql (default)>
spark-sql (default)> use hive;
19/05/22 07:37:30 INFO metastore.HiveMetaStore: 0: get_database: global_temp
19/05/22 07:37:30 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_database: global_temp
19/05/22 07:37:30 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
19/05/22 07:37:30 INFO metastore.HiveMetaStore: 0: get_database: hive
19/05/22 07:37:30 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_database: hive
Time taken: 3.488 seconds
19/05/22 07:37:30 INFO thriftserver.SparkSQLCLIDriver: Time taken: 3.488 seconds
spark-sql (default)> show tables;
19/05/22 07:37:43 INFO metastore.HiveMetaStore: 0: get_database: hive
19/05/22 07:37:43 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_database: hive
19/05/22 07:37:43 INFO metastore.HiveMetaStore: 0: get_database: hive
19/05/22 07:37:43 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_database: hive
19/05/22 07:37:43 INFO metastore.HiveMetaStore: 0: get_tables: db=hive pat=*
19/05/22 07:37:43 INFO HiveMetaStore.audit: ugi=hadoop ip=unknown-ip-addr cmd=get_tables: db=hive pat=*
19/05/22 07:37:44 INFO codegen.CodeGenerator: Code generated in 373.175585 ms
hive emp false
hive emp_external false
hive flow_info false
hive managed_emp false
hive order_partition false
hive page_views false
hive page_views_orc false
hive page_views_orc_none false
hive page_views_parquet false
hive page_views_parquet_gzip false
hive page_views_rc false
hive page_views_rcfile_test false
hive page_views_seq false
hive t false
hive t1 false
hive test false
hive version_test false
Time taken: 0.88 seconds, Fetched 17 row(s)
在Spark UI上可以看到是通过用户添加进去的mysql驱动jar包
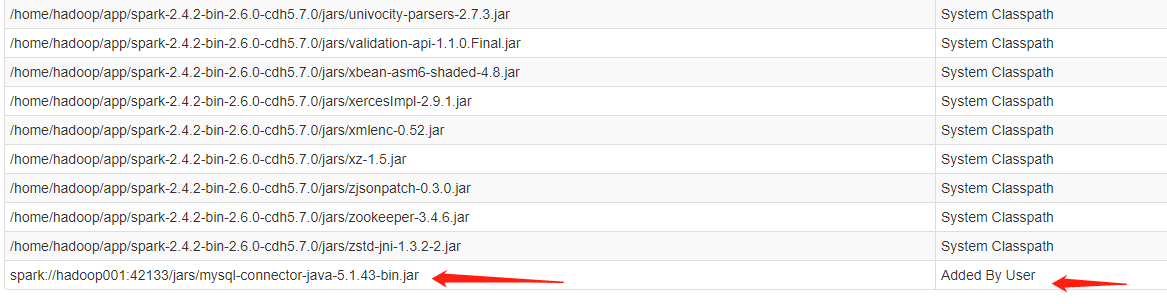
还可以用beline的方式
[[hadoop@hadoop001 sbin]$ ./start-thriftserver.sh --jars ~/software/mysql-connector-java-5.1.43-bin.jar
starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/logs/spark-hadoop-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-hadoop001.out
# 查看日志
[hadoop@hadoop001 conf]$ tail -200f /home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/logs/spark-hadoop-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-hadoop001.out
19/05/21 18:29:43 INFO service.AbstractService: Service:HiveServer2 is started.
19/05/21 18:29:43 INFO thriftserver.HiveThriftServer2: HiveThriftServer2 started
19/05/21 18:29:43 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6e22d6bf{/sqlserver,null,AVAILABLE,@Spark}
19/05/21 18:29:43 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@32121140{/sqlserver/json,null,AVAILABLE,@Spark}
19/05/21 18:29:43 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6d4f266{/sqlserver/session,null,AVAILABLE,@Spark}
19/05/21 18:29:43 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6b756a62{/sqlserver/session/json,null,AVAILABLE,@Spark}
19/05/21 18:29:43 INFO thrift.ThriftCLIService: Starting ThriftBinaryCLIService on port 10000 with 5...500 worker threads
通过查看日志,发现服务端已经启动了;启动客户端beline
[hadoop@hadoop001 bin]$ ./beeline -u jdbc:hive2://localhost:10000 -n hadoop
Connecting to jdbc:hive2://localhost:10000
19/05/21 18:36:58 INFO jdbc.Utils: Supplied authorities: localhost:10000
19/05/21 18:36:58 INFO jdbc.Utils: Resolved authority: localhost:10000
19/05/21 18:36:58 INFO jdbc.HiveConnection: Will try to open client transport with JDBC Uri: jdbc:hive2://localhost:10000
Connected to: Spark SQL (version 2.4.2)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1.spark2 by Apache Hive
0: jdbc:hive2://localhost:10000>
0: jdbc:hive2://localhost:10000> show databases;
+---------------+--+
| databaseName |
+---------------+--+
| default |
| hive |
+---------------+--+
2 rows selected (0.988 seconds)
注意:可以把启动的命名加在spark-defaults.conf里面,然后用spark-shell启动
通过UI界面查看
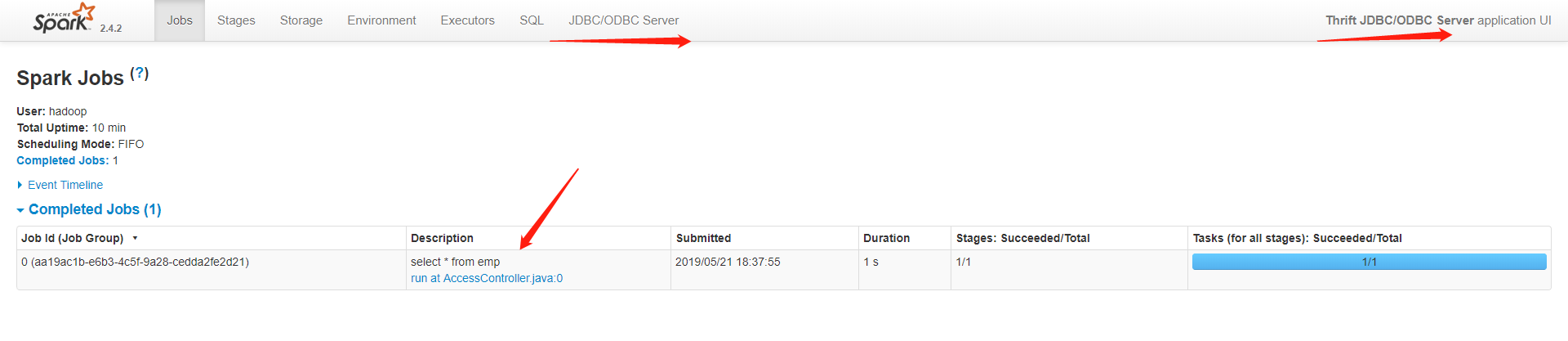
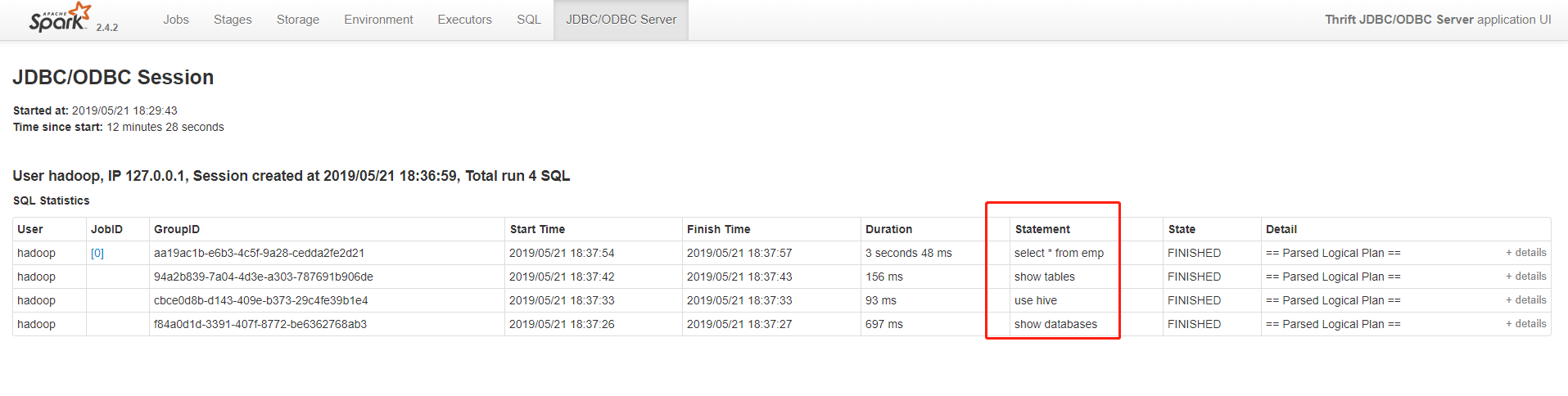
hive2和beeline官网描述 http://spark.apache.org/docs/latest/sql-distributed-sql-engine.html
show方法,默认只打印前20条记录,默认后面字段超过20个字符会被截断
def show(numRows: Int): Unit = show(numRows, truncate = true)
/**
* Displays the top 20 rows of Dataset in a tabular form. Strings more than 20 characters
* will be truncated, and all cells will be aligned right.
*
* @group action
* @since 1.6.0
*/
def show(): Unit = show(20)
/**
* Displays the top 20 rows of Dataset in a tabular form.
*
* @param truncate Whether truncate long strings. If true, strings more than 20 characters will
* be truncated and all cells will be aligned right
*
* @group action
* @since 1.6.0
*/
RDD VS DF VS DS
spark 1.6又引入了dateset的概念,这三者的特点如下:
rdd的优点: 1.强大,内置很多函数操作,group,map,filter等,方便处理结构化或非结构化数据 2.面向对象编程,直接存储的java对象,类型转化也安全 rdd的缺点: 1.由于它基本和hadoop一样万能的,因此没有针对特殊场景的优化,比如对于结构化数据处理相对于sql来比非常麻烦 2.默认采用的是java序列化方式,序列化结果比较大,而且数据存储在java堆内存中,导致gc比较频繁
dataframe的优点: 1.结构化数据处理非常方便,支持Avro, CSV, Elasticsearch, and Cassandra等kv数据,也支持Hive tables, MySQL等传统数据表 2.有针对性的优化,由于数据结构元信息spark已经保存,序列化时不需要带上元信息,大大的减少了序列化大小,而且数据保存在堆外内存中,减少了gc次数。 3.hive兼容,支持hql,udf等 dataframe的缺点: 1.编译时不能类型转化安全检查,运行时才能确定是否有问题 2.对于对象支持不友好,rdd内部数据直接以java对象存储,dataframe内存存储的是row对象而不能是自定义对象
dataset的优点:
1.dataset整合了rdd和dataframe的优点,支持结构化和非结构化数据
2.和rdd一样,支持自定义对象存储
3.和dataframe一样,支持结构化数据的sql查询
4.采用堆外内存存储,gc友好
5.类型转化安全,代码友好
6.官方建议使用dataset
参考博客 https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
操作DF
读json
scala> spark.read.json("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json").show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
# 打印Schema
scala> val peopleDF = spark.read.json("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.printSchema
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
# 统计某一列
scala> peopleDF.select($"name").show
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
scala> peopleDF.select("name","age").show
+-------+----+
| name| age|
+-------+----+
|Michael|null|
| Andy| 30|
| Justin| 19|
+-------+----+
scala> peopleDF.select(peopleDF("name"),$"age",$"age"+10).show
+-------+----+----------+
| name| age|(age + 10)|
+-------+----+----------+
|Michael|null| null|
| Andy| 30| 40|
| Justin| 19| 29|
+-------+----+----------+
scala> peopleDF.select($"name",$"age">20).show
+-------+----------+
| name|(age > 20)|
+-------+----------+
|Michael| null|
| Andy| true|
| Justin| false|
+-------+----------+
scala> peopleDF.filter($"age">20).show
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
scala> peopleDF.groupBy("age").count().show
+----+-----+
| age|count|
+----+-----+
| 19| 1|
|null| 1|
| 30| 1|
+----+-----+
用Spark SQL 注册为试图处理
scala> val peopleDF = spark.read.format("json").load("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.createOrReplaceTempView("people")
scala> spark.sql("select * from people")
res4: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> spark.sql("select * from people").show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
读 Parquet
scala> spark.read.parquet("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet").show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
# 打印Schema
scala> val usersDF = spark.read.parquet("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet")
usersDF: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
scala> usersDF.printSchema
root
|-- name: string (nullable = true)
|-- favorite_color: string (nullable = true)
|-- favorite_numbers: array (nullable = true)
| |-- element: integer (containsNull = true)
读orc
scala> spark.read.orc("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.orc").show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
# 打印Schema
scala> val usersDF = spark.read.orc("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.orc")
usersDF: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
scala> usersDF.printSchema
root
|-- name: string (nullable = true)
|-- favorite_color: string (nullable = true)
|-- favorite_numbers: array (nullable = true)
| |-- element: integer (containsNull = true)
读avro
https://github.com/gengliangwang/spark-avro
https://spark.apache.org/docs/latest/sql-data-sources-avro.html
[hadoop@hadoop001 software]$ spark-shell --jars spark-avro_2.11-2.4.2.jar
scala> spark.read.format("avro").load("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.avro").show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
读csv
scala> spark.read.csv("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.csv").show
+------------------+
| _c0|
+------------------+
| name;age;job|
|Jorge;30;Developer|
| Bob;32;Developer|
+------------------+
# 打印Schema
scala> val peopleDF = spark.read.csv("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.csv")
peopleDF: org.apache.spark.sql.DataFrame = [_c0: string]
scala> peopleDF.printSchema
root
|-- _c0: string (nullable = true)
读文本txt
scala> val peopleDF = spark.read.text("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.txt").show
+-----------+
| value|
+-----------+
|Michael, 29|
| Andy, 30|
| Justin, 19|
+-----------+
peopleDF: Unit = ()
# 打印Schema信息
scala> val peopleDF = spark.read.text("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.txt")
peopleDF: org.apache.spark.sql.DataFrame = [value: string]
scala> peopleDF.printSchema
root
|-- value: string (nullable = true)
注意:读取普通文本需要加上text
注意:标准写法,用format(“”).load(“”)
scala> val peopleDF = spark.read.format("json").load("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.show(false)
+----+-------+
|age |name |
+----+-------+
|null|Michael|
|30 |Andy |
|19 |Justin |
+----+-------+
把读入的orc文件写成parquet格式的
scala> val orcDF = spark.read.orc("file:///home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.orc")
orcDF: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
scala> orcDF.write.parquet("file:///home/hadoop/app/data/spark/")
# 查看parquet格式文件
[hadoop@hadoop001 ~]$ cd /home/hadoop/app/data/spark
[hadoop@hadoop001 spark]$ ll
total 4
-rw-r--r--. 1 hadoop hadoop 966 May 22 05:41 part-00000-41a6a3bd-c6b8-4c8e-bbe3-62d789dd942d-c000.snappy.parquet
-rw-r--r--. 1 hadoop hadoop 0 May 22 05:41 _SUCCESS
[hadoop@hadoop001 spark]$
# 读出来刚才写的parquet文件
scala> val parDF = spark.read.format("parquet").load("file:///home/hadoop/app/data/spark").show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
parDF: Unit = ()
RDD.map是RDD类型,DF.map后是DS类型
分区探测
[hadoop@hadoop001 spark]$ hdfs dfs -mkdir -p /sparksql/table/gender=male/country=US
[hadoop@hadoop001 spark]$ hdfs dfs -mkdir -p /sparksql/table/gender=male/country=CN
[hadoop@hadoop001 spark]$ hdfs dfs -mkdir -p /sparksql/table/gender=female/country=CN
[hadoop@hadoop001 spark]$ hdfs dfs -mkdir -p /sparksql/table/gender=female/country=US
[hadoop@hadoop001 resources]$ hdfs dfs -put users.parquet /sparksql/table/gender=male/country=US
scala> val parquetpartitionDF = spark.read.format("parquet").load("hdfs://hadoop001:8020/sparksql/table/")
parquetpartitionDF: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 3 more fields]
scala> parquetpartitionDF.printSchema
root
|-- name: string (nullable = true) //内置的
|-- favorite_color: string (nullable = true) //内置的
|-- favorite_numbers: array (nullable = true) //内置的
| |-- element: integer (containsNull = true) //内置的
|-- gender: string (nullable = true) // 分区1
|-- country: string (nullable = true) //分区2
# 如果传入的是下一层路径,只能探测传入的路径下一层的分区
scala> val parquetpartitionDF = spark.read.format("parquet").load("hdfs://hadoop001:8020/sparksql/table/gender=male").printSchema
root
|-- name: string (nullable = true)
|-- favorite_color: string (nullable = true)
|-- favorite_numbers: array (nullable = true)
| |-- element: integer (containsNull = true)
|-- country: string (nullable = true)
parquetpartitionDF: Unit = ()
scala> val parquetpartitionDF = spark.read.format("parquet").load("hdfs://hadoop001:8020/sparksql/table/gender=male/country=US").printSchema
root
|-- name: string (nullable = true)
|-- favorite_color: string (nullable = true)
|-- favorite_numbers: array (nullable = true)
| |-- element: integer (containsNull = true)
parquetpartitionDF: Unit = ()
Schema 合并
scala> val squaresDF = spark.sparkContext.makeRDD(1 to 5).map(i => (i, i * i)).toDF("value", "square")
squaresDF: org.apache.spark.sql.DataFrame = [value: int, square: int]
scala> squaresDF.show
+-----+------+
|value|square|
+-----+------+
| 1| 1|
| 2| 4|
| 3| 9|
| 4| 16|
| 5| 25|
+-----+------+
scala> val cubesDF = spark.sparkContext.makeRDD(6 to 10).map(i => (i, i * i * i)).toDF("value", "cube")
cubesDF: org.apache.spark.sql.DataFrame = [value: int, cube: int]
scala> cubesDF.show
+-----+----+
|value|cube|
+-----+----+
| 6| 216|
| 7| 343|
| 8| 512|
| 9| 729|
| 10|1000|
+-----+----+
scala> squaresDF.write.parquet("data/test_table/key=1")
scala> cubesDF.write.parquet("data/test_table/key=2")
# 合并Schema
scala> val mergedDF = spark.read.option("mergeSchema", "true").parquet("data/test_table")
mergedDF: org.apache.spark.sql.DataFrame = [value: int, square: int ... 2 more fields]
scala> mergedDF.printSchema()
root
|-- value: integer (nullable = true)
|-- square: integer (nullable = true)
|-- cube: integer (nullable = true)
|-- key: integer (nullable = true)
scala> mergedDF.show
+-----+------+----+---+
|value|square|cube|key|
+-----+------+----+---+
| 4| 16|null| 1|
| 5| 25|null| 1|
| 9| null| 729| 2|
| 10| null|1000| 2|
| 1| 1|null| 1|
| 2| 4|null| 1|
| 3| 9|null| 1|
| 6| null| 216| 2|
| 7| null| 343| 2|
| 8| null| 512| 2|
+-----+------+----+---+
注意:Schema的合并开销很大,从Spark1.5.0就默认关闭了此参数,在SQLConf.scala中也有此参数
scala> spark.sql("SET spark.sql.parquet.mergeSchema=true").show(false)
+-----------------------------+-----+
|key |value|
+-----------------------------+-----+
|spark.sql.parquet.mergeSchema|true |
+-----------------------------+-----+
spark-sql (default)> set spark.sql.parquet.mergeSchema=false;
spark-sql (default)> set spark.sql.parquet.mergeSchema;
spark.sql.parquet.mergeSchema false
Hive Table
scala> import spark.implicits._
import spark.implicits._
scala> import spark.sql
import spark.sql
scala> sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
scala> sql("LOAD DATA LOCAL INPATH '/home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/examples/src/main/resources/kv1.txt' INTO TABLE src")
scala> sql("SELECT * FROM src").show()
scala> sql("SELECT COUNT(*) FROM src").show()
+--------+
|count(1)|
+--------+
| 500|
+--------+
scala> val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key")
sqlDF: org.apache.spark.sql.DataFrame = [key: int, value: string]
scala> sqlDF.show
+---+-----+
|key|value|
+---+-----+
| 0|val_0|
| 0|val_0|
| 0|val_0|
| 2|val_2|
| 4|val_4|
| 5|val_5|
| 5|val_5|
| 5|val_5|
| 8|val_8|
| 9|val_9|
+---+-----+
其他的代码测试详见官网 [park SQL操作Hive]http://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html)
操作JDBC
scala> val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://192.168.100.111:3306/hive").option("dbtable", "TBLS").option("user", "root").option("password", "123456").load()
jdbcDF: org.apache.spark.sql.DataFrame = [TBL_ID: bigint, CREATE_TIME: int ... 9 more fields]
scala> jdbcDF.show(false)
Hive中的元数据join操作
scala> val tbls = spark.read.format("jdbc").option("url","jdbc:mysql://192.168.100.111:3306/hive").option("dbtable", "TBLS").option("user", "root").option("password", "123456").load()
tbls: org.apache.spark.sql.DataFrame = [TBL_ID: bigint, CREATE_TIME: int ... 9 more fields]
scala> val dbs = spark.read.format("jdbc").option("url","jdbc:mysql://192.168.100.111:3306/hive").option("dbtable", "DBS").option("user", "root").option("password", "123456").load()
dbs: org.apache.spark.sql.DataFrame = [DB_ID: bigint, DESC: string ... 4 more fields]
scala> dbs.join(tbls,dbs("DB_ID")===tbls("DB_ID")).select("DB_LOCATION_URI" ,"NAME", "TBL_TYPE").show(false)
注意:一定要注意join里面的select("")的格式,不要出现空格;我由于书写的时候出现了"TBL_TYPE " 这样的空格,导致一直报错,说是分析的时候语法有问题。
从上面的代码可以看出,多个不同数据源来的DF就可以做相应的关联操作
在生产中,JDBC写的话,不用jdbcDF.wirte;用foreachePartition算子写
Spark SQL 调优
Spark SQL shuffle
spark-sql (default)> select deptno,count(1) from emp group by deptno;
Spark SQL中的Shuffle的Task数量默认为200
spark-sql (default)> create table dept(deptno int,dname string,loc string) row format delimited fields terminated by '\t';
# 导入数据
spark-sql (default)> load data local inpath '/home/hadoop/data/dept.txt' into table dept;
# join emp和dept
spark-sql (default)> select e.empno,e.ename,e.deptno,d.dname from emp e join dept d on e.deptno=d.deptno;
查看Web UI,发现做了一个Broadcast
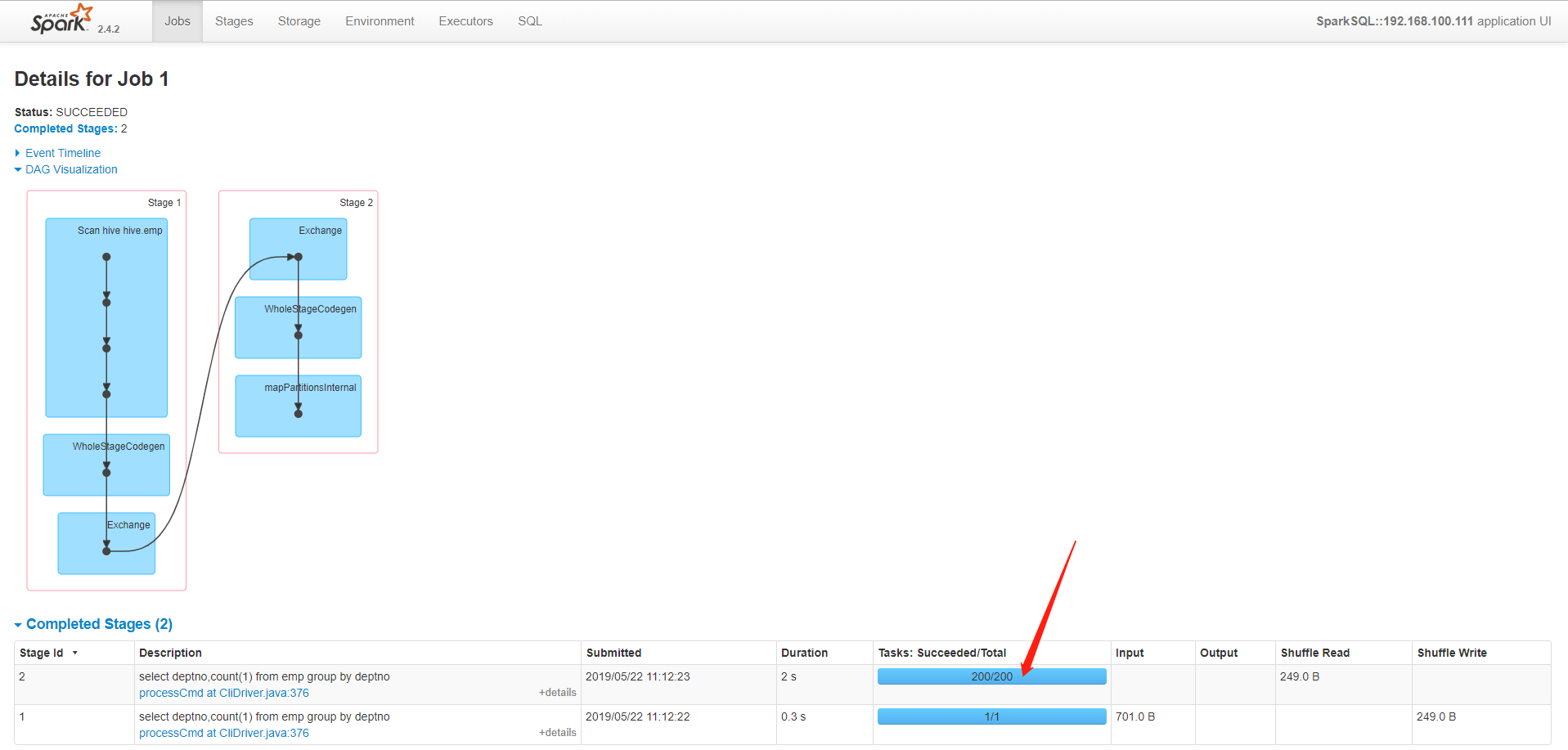
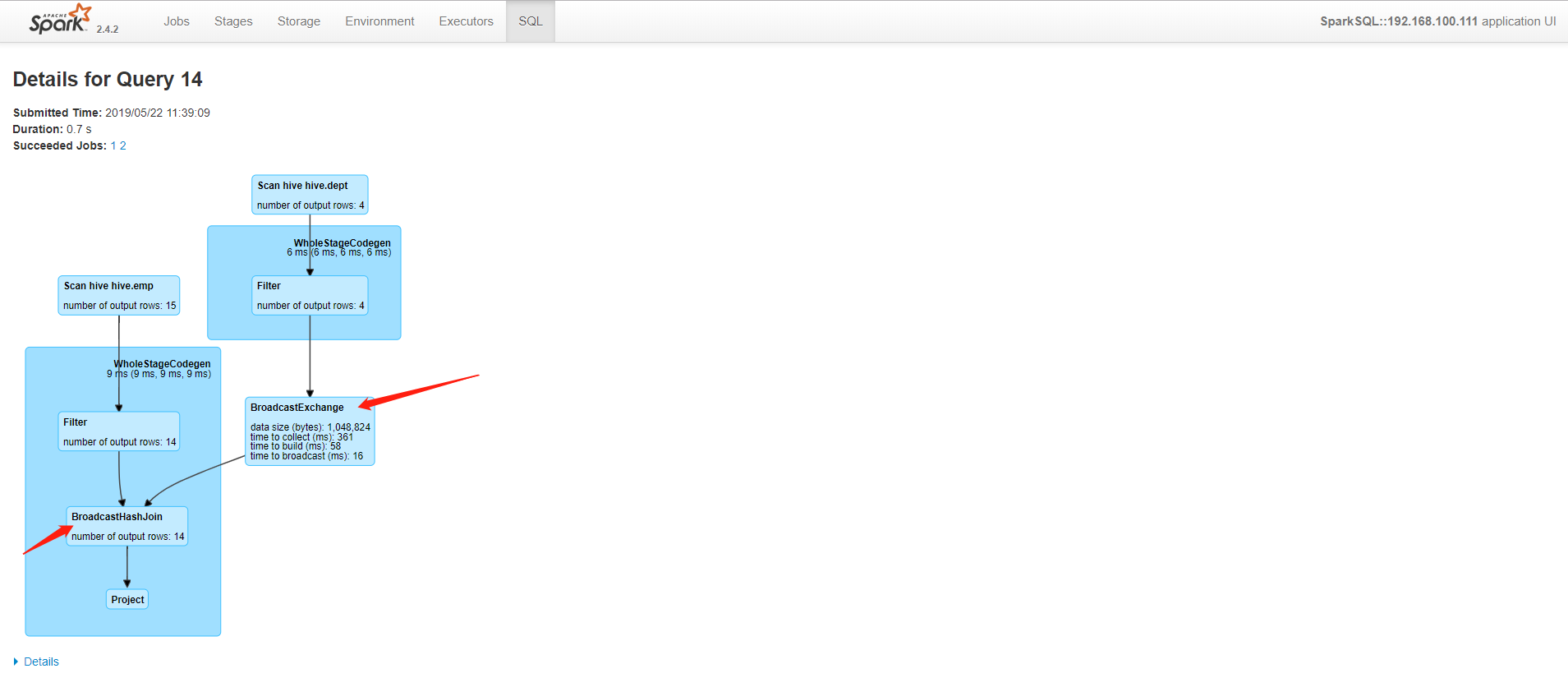
修改参数spark.sql.autoBroadcastJoinThreshold=-1,即不让他广播
spark-sql (default)> set spark.sql.autoBroadcastJoinThreshold=-1;
spark-sql (default)> set spark.sql.autoBroadcastJoinThreshold;
spark.sql.autoBroadcastJoinThreshold -1
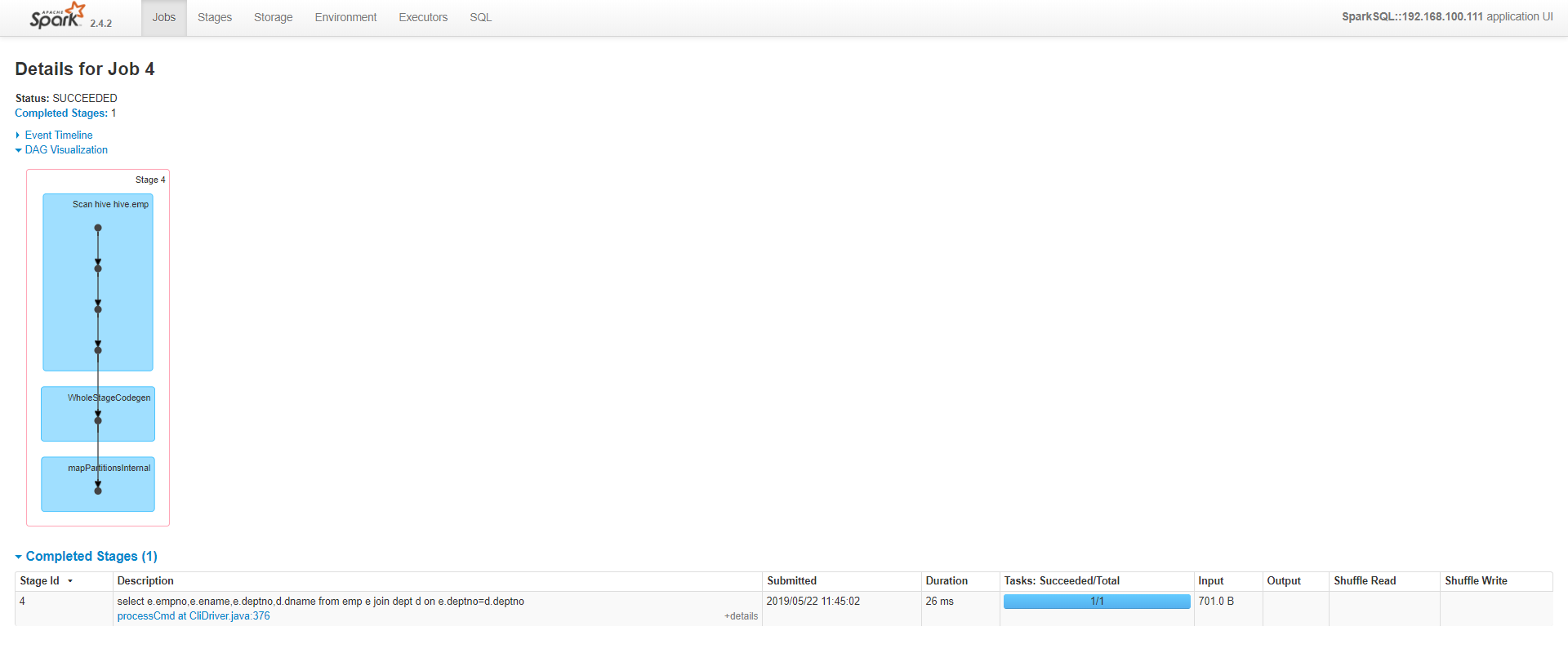
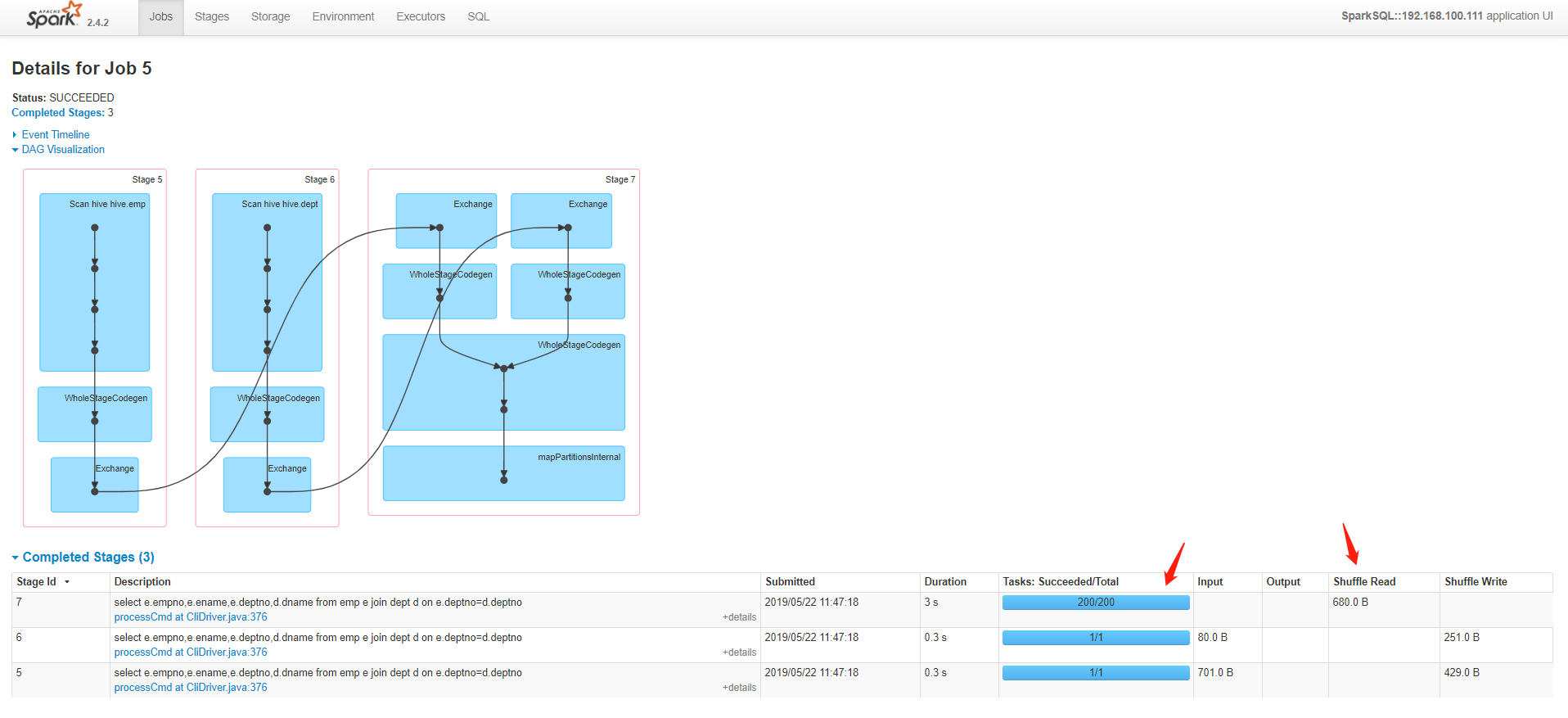
Web UI查看情况,发现时间由前面的0.7s变成了4s;最后才做join操作的,出现了shuffle
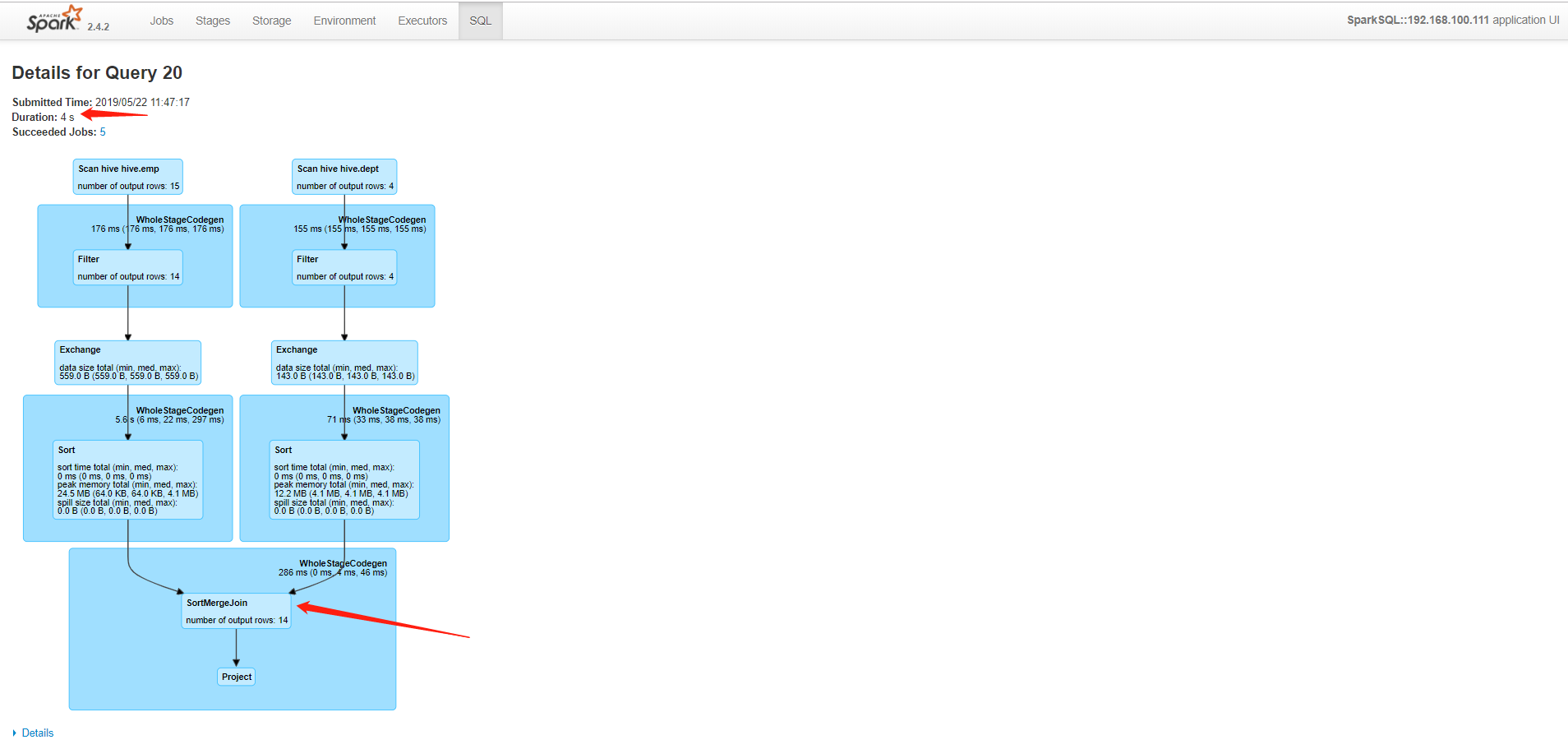
参数spark.sql.autoBroadcastJoinThreshold默认为10MB,如果不想让他广播出去设置为-1;但是在生产上是肯定要广播的,设置的大小根据自己的业务需求。
Broadcast Hint for SQL Queries
import org.apache.spark.sql.functions.broadcast
broadcast(spark.table("src")).join(spark.table("records"), "key").show()
这种操作有可能把大表广播出去了,所以尽量选择上面的那种调优方式。
第三方的Spark-packages
https://spark-packages.org/
外部数据源
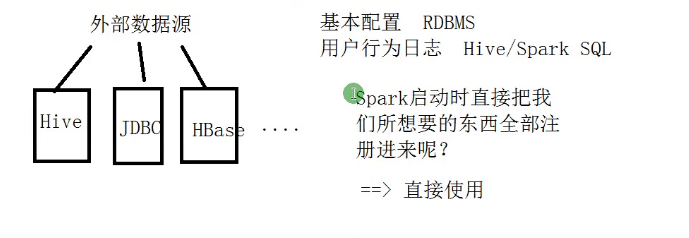
catalog
她是Spark2.0推出的新特性,她把元数据信息集成到了Spark里面,这样便于统一的管理,比如Hive的元数据信息是存放在MySQL里面的。
scala> spark.catalog.listDatabases().show(false)
+-------+---------------------+-------------------------------------------------+
|name |description |locationUri |
+-------+---------------------+-------------------------------------------------+
|default|Default Hive database|hdfs://hadoop001:8020/user/hive/warehouse |
|hive | |hdfs://hadoop001:8020/user/hive/warehouse/hive.db|
+-------+---------------------+-------------------------------------------------+
scala> spark.catalog.listTables.show(false)
19/05/23 04:32:12 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
+----------------------+--------+-----------+---------+-----------+
|name |database|description|tableType|isTemporary|
+----------------------+--------+-----------+---------+-----------+
|hive_ints |default |null |EXTERNAL |false |
|hive_records |default |null |MANAGED |false |
|page_views_rcfile_test|default |null |MANAGED |false |
|src |default |null |MANAGED |false |
+----------------------+--------+-----------+---------+-----------+
scala> spark.catalog.listTables("hive").show(false)
+-----------------------+--------+-----------+---------+-----------+
|name |database|description|tableType|isTemporary|
+-----------------------+--------+-----------+---------+-----------+
|dept |hive |null |MANAGED |false |
|emp |hive |null |MANAGED |false |
|emp_external |hive |null |EXTERNAL |false |
|flow_info |hive |null |MANAGED |false |
|managed_emp |hive |null |MANAGED |false |
|order_partition |hive |null |MANAGED |false |
|page_views |hive |null |MANAGED |false |
|page_views_orc |hive |null |MANAGED |false |
|page_views_orc_none |hive |null |MANAGED |false |
|page_views_parquet |hive |null |MANAGED |false |
|page_views_parquet_gzip|hive |null |MANAGED |false |
|page_views_rc |hive |null |MANAGED |false |
|page_views_rcfile_test |hive |null |MANAGED |false |
|page_views_seq |hive |null |MANAGED |false |
|t |hive |null |MANAGED |false |
|t1 |hive |null |MANAGED |false |
|test |hive |null |MANAGED |false |
|version_test |hive |null |MANAGED |false |
+-----------------------+--------+-----------+---------+-----------+
scala> spark.catalog.listTables("default").show(false)
+----------------------+--------+-----------+---------+-----------+
|name |database|description|tableType|isTemporary|
+----------------------+--------+-----------+---------+-----------+
|hive_ints |default |null |EXTERNAL |false |
|hive_records |default |null |MANAGED |false |
|page_views_rcfile_test|default |null |MANAGED |false |
|src |default |null |MANAGED |false |
+----------------------+--------+-----------+---------+-----------+
HDFS中的put的文件格式是啥?

函数赋值给变量
scala> def sayHello(name:String):Unit={
| println("Hello " + name)
| }
sayHello: (name: String)Unit
scala> // 函数赋值给变量
scala> val sayHelloFunc = sayHello _
sayHelloFunc: String => Unit = $$Lambda$1163/1868931587@1d0b447b
scala> sayHelloFunc("JustDoDT")
Hello JustDoDT
匿名函数
(参数名:参数类型)=> 函数体
匿名函数赋值给变量
scala> (x:Int) => x+1
res2: Int => Int = $$Lambda$1168/1672524765@397dfbe8
scala> x:Int => x+1
<console>:1: error: ';' expected but '=>' found.
x:Int => x+1
^
scala> {x:Int => x+1}
res3: Int => Int = $$Lambda$1171/959378687@6ed7c178
scala> val a = (x:Int) => x+1
a: Int => Int = $$Lambda$1172/1018394275@7022fb5c
scala> a(2)
res4: Int = 3
scala> val b = {x:Int => x+1}
b: Int => Int = $$Lambda$1181/1454795974@6f076c53
scala> b(5)
res5: Int = 6
匿名函数赋值给函数
scala> def sum = (x:Int,y:Int)=>x+y
sum: (Int, Int) => Int
scala> sum(2,3)
res6: Int = 5
隐式转换
隐士: 偷偷摸摸的
目的:悄悄的为一个类的方法进行增强
Man ===> Superman
在Java中可以用Proxy来实现
object ImplicitApp {
def main(args: Array[String]): Unit = {
//定义隐士转换
implicit def man2superman(man:Man):Superman = new Superman(man.name)
val man = new Man("JustDoDT")
man.fly()
}
}
class Man(val name:String){
def eat():Unit={
println("Man eat")
}
}
class Superman(val name:String){
def fly():Unit ={
println(s"$name fly")
}
}
运行结果为:
JustDoDT fly
例子2:
import java.io.File
import scala.io.Source
object ImplicitApp {
def main(args: Array[String]): Unit = {
implicit def file2RichFile(file:File):RichFile = new RichFile(file)
val file = new File("E:/temp/students.txt")
val context = file.read()
println(context)
}
}
class RichFile(val file:File){
def read() = Source.fromFile(file.getPath).mkString
}
运行结果
1 Tom 23
2 Mary 26
3 Mike 24
4 Jone 21
在工作中可以把封装一下所有经常要用到的隐士转换
import java.io.File
object ImplicitAspect {
implicit def man2superman(a:Man):Superman = new Superman(a.name)
implicit def file2RichFile(haha:File):RichFile = new RichFile(haha)
}
直接调用
import java.io.File
import scala.io.Source
import ImplicitAspect._
object ImplicitApp {
def main(args: Array[String]): Unit = {
val man = new Man("JustDoDT")
man.fly()
val file = new File("E:/temp/students.txt")
val context = file.read()
println(context)
}
}
class RichFile(val file:File){
def read() = Source.fromFile(file.getPath).mkString
}
class Man(val name:String){
def eat():Unit={
println("Man eat")
}
}
class Superman(val name:String){
def fly():Unit ={
println(s"$name fly")
}
}