RowKey是什么
- 可以理解为关系型数据库(MySQL,Oracle)的主键,用于标识唯一的行。
- 完全是由用户指定的一串不重复的字符串。
- HBase中的数据永远是根据RowKey的字典排序来排序的。
RowKey的作用
- 读写数据时,通过RowKey找到对应的Region,例如需要查找一条数据肯定需要知道他的RowKey,写数据的时候也要根据RowKey来写。
- MemStore中的数据按照RowKey字典顺序排序,写数据的时候会先将数据放到MemStore也就是内存,内存中的数据是按照RowKey字典顺序排序的。
- HFile中的数据按照RowKey字典顺序排序,内存中的数据最后也会持久化到磁盘中,磁盘的数据HFile也是按照RowKey字典顺序排序的。
RowKey对查询的影响
例如:RowKey由uid+phone+name组成
1.可以很好的支持场景
- uid = 111 and phone = 123 and name = abc
- uid = 111 and phone = 123
- uid = 111 and phone = 12?
- uid = 111
这种场景下我们都指定了uid部分,也就是RowKey的第一部分,第一种查询的RowKey是完整的格式,所以查询效率最好的,后边的三个虽然没有指定完整RowKey,但是查询的支持度也还不错。
2.难支持的场景
- phone = 123 and name = abc
- phone = 123
- phone = abc
这种场景下并没有指定RowKey的第一部分uid,只通过了phone跟name去做查询,也就是不指定先导部分,那么这种场景会导致HBase的查询的时候去进行全表扫描,降低了查询的效率。
RowKey对Region划分影响
HBase表的数据是按照RowKey来分散到不同的Region,不合理的RowKey设计会导致热点问题,热点问题是大量的客户端直接访问集群中的一个或极少数的节点,而集群中的其他节点却处于相对空闲的状态,从而影响对HBase的读写性能。
RowKey的设计技巧
Salting(加盐)
Salting的原理是将固定长度的随机数放在行键的起始位置,具体就是给rowkey分配一个随机前缀,以使得它和之前排序不同。分配的前缀种类数量应该和你想使数据分散到不同的region的数量一致。如果你有一些热点rowkey反复出现在其他分布均匀的rowkey中,加盐是很有用的。
例如:假如你有如下的rowkey,你表中每一个 region 对应字母表中每一个字母。 以 ‘a’ 开头是同一个region, ‘b’开头的是同一个region。在表中,所有以 ‘f’开头的都在同一个 region, 它们的 rowkey 像下面这样:
foo0001
foo0002
foo0003
foo0004
=========>>
foo0001 =====> a-foo0001
foo0002 =====> b-foo0002
foo0003 =====> c-foo0003
foo0004 =====> d-foo0004
假如你需要将上面这个 region 分散到 4个 region。你可以用4个不同的盐:‘a’, ‘b’, ‘c’, ‘d’.在这个方案下,每一个字母前缀都会在不同的 region 中。加盐之后,就像上边的例子.
所以,你可以向4个不同的 region 写,理论上说,如果所有人都向同一个region 写的话,你将拥有之前4倍的吞吐量。
优缺点:
由于前缀是随机生成的,因此想要按照字典顺序找到这些行,则需要做更多的工作,从这个角度上看,salting增加了写操作的吞吐量,却也增加了读操作的开销。
Hashing
Hashing的原理是计算RowKey的hash值,然后取hash的部分字符串和原来的RowKey进行拼接。这里说的hash包含MD5,sha1,sha256,sha512等算法,并不是仅限于Java的Hash值计算。
例如:我们有如下的RowKey:
foo0001 95f18cfoo0001
foo0002 ===> 6ccc20foo0002
foo0003 b61d00foo0003
foo0004 1a7475foo0004
我们使用md5计算这些RowKey的hash值,然后取前6位和原来的RowKey拼接得到最新的RowKey,如上的操作。
优缺点:
可以一定程度打散整个数据集,但是不利于Scan;比如我们使用md5算法,来计算RowKey的md5值,然后截取前几位的字符串。常用的方法:subString(MD5(设备ID),0,x) + 设备ID,其中x 一般取5或者6。
Reversing(反转)
反转的原理是反转一段固定长度或者全部的键。
例如:比如我们有如下的URL,并作为RowKey:
flink.iteblog.com moc.golbeti.knilf
www.iteblog.com ===> moc.golbeti.www
carbondata.iteblog.com moc.golbeti.atadnobrac
def.iteblog.com moc.golbeti.fed
优缺点:
有效的打乱了行键,但是却牺牲了行排序的属性.
RowKey的长度
RowKey可以是任意的字符串,最大长度64KB(因为Rowlength占用2个字节)。建议越短越好,原因如下:
- 数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000W行数据,光RowKey就要占用100*1000W=10亿个字节,将近1GB数据,这样会极大的影响HFile的存储效率。
- MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率会降低,系统不能缓存更多的数据,这样会降低检索的效率。
- 目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
设计案例剖析
交易类表RowKey设计
-
查询某个卖家某段时间内的交易记录
sellerld + timestamp + orderld
-
查询某个卖家某段时间的交易记录
buyerId + timestamp + orderId
-
根据订单号查询
orderNo
如果某个商家卖了很多商品,按第一种方式就有可能会有大量RowKey前缀相同的数据在相同的Region上,造成热点问题,可以做如下的设计RowKey实现快速的搜索salt + sellerId + timestamp ,其中,salt是随机数。
我们在原来的结构之前进行了一步加盐(salt)操作,例如加上一个随机数,这样就可以把这些数据分散到不同的Region上去了。
可以支持的场景:
1.全表Scan,因为进行了加盐操作,数据分散到了不同的Region上,Scan的时候就会去不同的的Region上去Scan,这样就提升了高并发,也就是提升检索效率。
2.按照sellerId查询。
3.按照 sellerId + timestamp 查询
金融风控RowKey设计
查询某个用户的用户画像数据
prefix + uid
prefix + idcard
prefix + tele
其中前缀的生产prefix = substr(md5(uid),0,x),x 取5 — 6。uid、idcard以及tele分别表示用户唯一标识符、身份证、手机号码。
车联网RowKey设计
-
查询某辆车在某个时间范围的数据,例如发动机数据。
carId + timestamp
-
某批次的车太多,造成热点。
prefix + carId + timestamp
其中 prefix = substr(md5(uid),0,x)
倒序时间戳(时间倒排)
查询用户最新的操作记录或者查询用户某段时间的操作记录,RowKey设计如下:
uid + Long.Max_Value - timestamp
支持的场景
-
查询用户最新的操作记录
Scan[uid] startRow [uid] [00000000000] stopRow [uid] [uid] [Long.Max_Value - timestamp]
这样就能查询出比如说最近100条数据
-
查询用户某段时间的操作记录
Scan [uid] startRow [uid] [Long.Max_Value - startTime] stopRow uid [uid] [Long.Max_Value - endTime]
二级索引
例如:有一张HBase表结构及数据如下
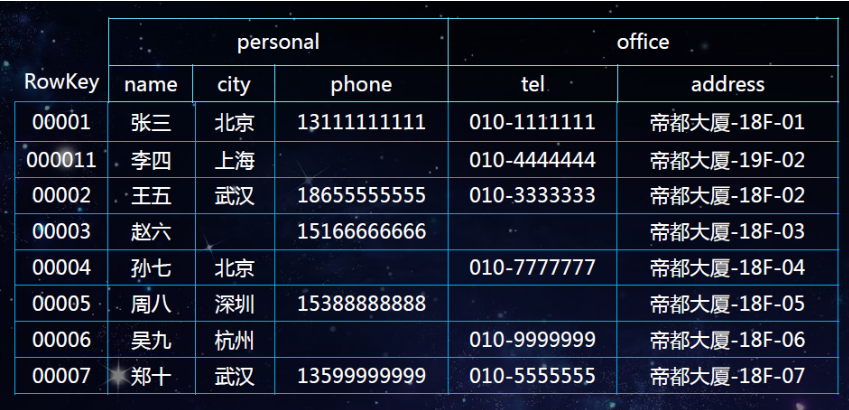
问:如何查找phone=13111111111的用户?
遇到这种需求的时候,HBase的设计肯定是满足不了的,这时候就要引入二级索引,将phone当做RowKey,uid/name当做列名构建二级索引。
如果不依赖第三方组件的话,可以自己编码实现二级索引,同时也可以通过Phoenix或者Solr创建二级索引。
SQL+OLTP ========> Phoenix
全文索引+二级索引 ==============> Solr/ES