概述
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下的特点:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持流式处理。
复制提供了高可用,即使有些节点出现了失败:
- Producer可以继续发布消息
- Consumer可以继续接收消息
复制的方案介绍
有两种方案可以保证强一致的数据复制: primary-backup replication 和 quorum-based replication。两种方案都要求选举出一个leader,其它的副本作为follower。所有的写都发给leader, 然后leader将消息发给follower。
基于quorum的复制可以采用raft、paxos等算法, 比如Zookeeper、 Google Spanner、etcd等。在有 2n + 1个节点的情况下,最多可以容忍n个节点失败。
基于primary-backup的复制等primary和backup都写入成功才算消息接收成功, 在有n个节点的情况下,最多可以容忍n-1节点失败,比如微软的PacifiaA。
两种方案的优缺点
1、基于quorum的方式延迟(latency)可能会好于primary-backup,因为基于quorum的方式只需要部分节点写入成功就可以返回。 2、在同样多的节点下基于primary-backup的复制可以容忍更多的节点失败,只要有一个节点活着就可以工作。 3、primary-backup在两个节点的情况下就可以提供容错,而基于quorum的方式至少需要三个节点。
Kafka采用了第二种方式,也就是主从模式, 主要是基于容错的考虑,并且在两个节点的情况下也可以提供高可用。
万一一个节点慢了怎么办?首先这种情况是很少发生的,万一发生了可以设置timeout参数处理这种情况。
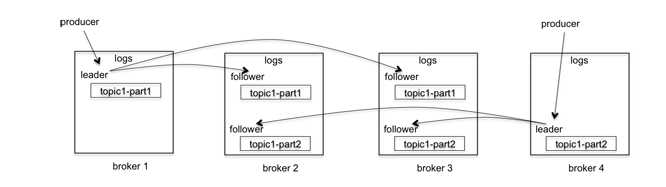
Kafka的复制是针对分区的。比如上图中有4个broker,一个topic,2个分区,复制因子是3.当producer发送一个消息的时候,它会选择一个分区,比如topic-part1分区,将消息发送给这个分区的leader,broker2,broker3会拉取这个消息,一旦消息被拉取过来,follower会发送ack给master,这时候master才commit这个log。
这个过程中的producer有两个选择:一是等所有的副本拉取成功producer才收到写入成功的response,二是等leader写入成功就得到成功的response。第一个中可以保证在异常情况下不丢消息,但是latency就下来了。后一种latency提高很多,但是一旦有异常情况,follower还没有来得及拉取最新的消息leader就挂了,这种情况下就有可能丢消息了。
一个Broker既可能是一个分区的leader,也可能是另一个分区的follower,如图所示。
Kafka实际是保证在足够多的follower写入成功的情况下就认为消息写入成功,而不是全部写入成功。这是因为有可能一些节点网络不好,或者机器有问题hang住了,如果leader一直等着,那么所有后续的消息都堆积起来了,所以Kafka认为只要足够多的副本写入就可以了。那么,怎么才认为是足够多呢?
Kafka引入了ISR的概念。ISR是in-sync replicas(同步副本)的简写。ISR的副本保持和leader的同步,当然leader本身也在ISR中。初始状态所有的副本都处于ISR中,当一个消息发送给leader的时候,leader会等待ISR中所有的副本告诉它已经接收到了这个消息,如果一个副本失败了,那么它会被移除ISR。下一条消息来的时候,leader就会将消息发送给当前的ISR中的节点。
同时,leader还维护这HW(high watermark),这是一个分区的最后一条消息的offset。HW会持续的将HW发送给follower,broker可以将它写入到磁盘中以便将来恢复。
当一个失败的副本重启的时候,它首先恢复磁盘中记录的HW,然后将它的消息truncate到HW这个offset。这是因为HW之后的消息不保证已经commit。这时它变成了一个follower, 从HW开始从Leader中同步数据,一旦追上leader,它就可以再加入到ISR中。
kafka使用Zookeeper实现leader选举。如果leader失败,controller会从ISR选出一个新的leader。leader 选举的时候可能会有数据丢失,但是committed的消息保证不会丢失。
总结
我们可以用 bin/kafka-topics.sh –describe –zookeeper localhost:2181 –topic test
这样会打印出 topic test 的 detail 信息,如图,
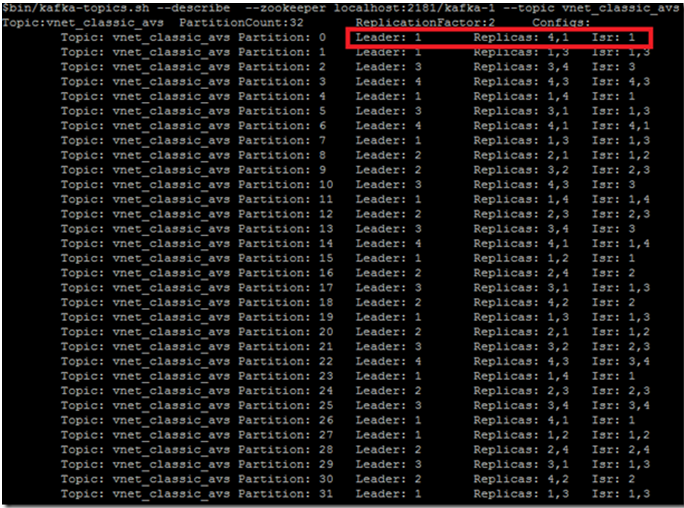
从这个图可以说明几个问题:
首先,topic 有几个 partitions,并且 replicas factor 是多少,即有几个 replica?
图中分别有32个 partitions,并且每个 partition 有两个 replica。
再者,每个 partition 的 replicas 都被分配到哪些 brokers 上,并且该 partition 的 leader 是谁?
比如,图中的 partition0,replicas 被分配到 brokers 4和1上面,其中 leader replica 在 broker 1 上。
最后,是否健康?
从以下几个方面依次表明健康程度
- ISR为空,说明这个partition已经offline无法提供服务了,这中情况在上面的图中未出现
- ISR有数据,但是ISR < Replicas,这种情况下对于用户是没有感知的,但是说明有部分replicas已经出问题了,至少是暂时无法和leader同步;比如,图中的partition0,ISR只有1,说明replica 4已经offline
- ISR = Replicas,但是leader不是Replicas中的第一个replica,这个说明leader是发生过重新选取的,这样可能会导致brokers 负载不均衡;比如,图中的partition9,leader是2,而不是3,说明虽然当前它的所有 replica 都是正常的,但之前发生过重新选举。