Streming 程序已经失败,进程不退出
用户提交到 Yarn 上的 Spark Streaming 程序容易受到别的因素影响而导致程序失败,有时候程序失败之后 driver 进程不退出,这样无法通过监控 driver 的进程来重启 Streaming 程序。推荐将 Streaming 程序运行在 Standalone 模式的集群之上,使用 cluster 部署模式,并启用 supervise 功能。使用这种方式的好处是 Streaming程序非正常退出之后,Spark 集群会自动重启 Streaming 的程序,无须人为干预。
Executor 只有少数几个运行
经常会碰到这样一种现象:只有少数 Executor 在运行,别的 Executor 长时间空闲。这种现象比较常见的原因是数据的分区比较少,可以使用 repartition 来提高并行度。
另外一种原因和数据本地性有关,请看下面的例子:
用户申请了100个 executor ,每个 executor 的 cores 为 6,那么最多会有 600 个任务同时在运行,刚开始是 600 个任务在运行,接着正在运行的任务越来越少,只剩下 78 个任务在运行,像下图所示:
(2057 + 78)/ 6057
这个问题会导致 Spark 基于 yarn 的动态分配功能也无法使用了,Executor 长时间空闲之后会被杀死,然后报一大堆Error信息。
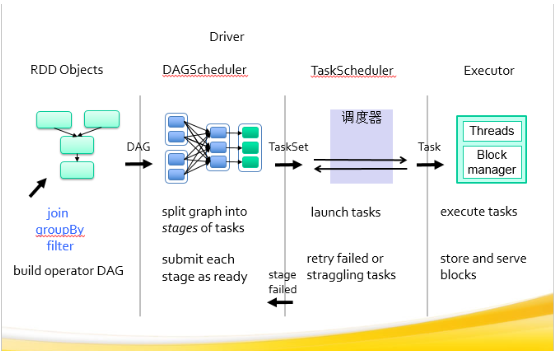
首先回顾一下 Spark作业的提交流程,如下图所示:
-
1.首先 DAGSchedular 会把作业分成多个 Stage,划分的依据:是否需要进行 shuffle操作。
-
2.每个 Stage 由很多的 Tasks 组成,Tasks 的数量由这个 Stage 的 partition 数决定。Stage 之间可能有依赖关系,先提交没有前置依赖的 Stage。把 Stage 里的任务包装成一个 TaskSet,交给 TaskScheduler提交。
-
3.把Task 发送给 Executor,让 Executor 执行 Task。
这个问题是出在第2步,TaskScheduler 是怎么提交任务的。这块的逻辑主要是在CoarseGrainedSchedulerBackend 和 TaskSchedulerImpl。下面是 CoarseGrainedSchedulerBackend 里面的 makeOffer 方法的主要逻辑:
-
- CoarseGrainedSchedulerBackend 筛选出来活跃的 Executors,交给 TaskSchedulerImpl。
- TaskSchedulerImpl 返回一批 Task 描述给 CoarseGrainedSchedulerBackend。
- 序列化之后的任务的大小没有超过 spark.akka.frameSize 就向 Executor 发送该任务。
问题是出在第二步,根据活跃的 Executors,返回可以执行的 Tasks。具体查看 TaskSchedulerImpl的 resourceOffers方法。
-
1.在内存当中记录传入的 Executor 的映射关系,记录是否有薪的机器加入。
-
2.如果有新的机器加入,要对所有的 TaskSetManager 重新计算本地性。
-
3.遍历所有的 TaskSetManager,根据 TaskSetManager 计算得出的任务的本地性来分配任务。
分配任务的优先级:
- 同一个 Executor
- 同一个节点
- 没有优先级节点
- 同一个机架
- 任务节点
如果上一个优先级的任务的最后发布时间不满足下面这个条件,任务将不会被分布出去,导致出现上面的现象。
判断条件是:curTime -> lastLaunchTime --> localityWaits(currentLocalityIndex)这样设计的初衷是好的,希望先让本地性更好的执行任务,但是这里没有考虑到 Executor 的空闲时间以及每个 Task 的空闲时间。跳过了这个限制之后,它还是会按照优先级来分配任务的,所以不用担心本地性的问题。
下面这几个参数在官方的配置介绍当中有,但是没有介绍清楚,默认都是 3 秒,减小这几个参数就可以绕过限制了。
-
spark.locality.wait.process 1ms #超过这个时间,可以执行 NODE_LOCAL 的任务
-
spark.locality.wait.node 3ms # 超过这个时间,可以执行 RACK_LOCAL的任务
-
spark.locality.wait.rack 1s # 超过这个时间,可以执行 ANY 的任务
实践测试,以上问题解决了,并且速度也快了20%以上。
Task 在同一棵树上连续吊死
Spark 的任务在失败之后还在同一台机器上不断的重试,直至超过了设置的重试次数之后。在生产环境当中,因为各种各样的原因,比如网络原因,磁盘满了的等原因会使任务挂掉,在这个时候,在同一台机器上重试几乎没有成功的机会,把任务发到别的机器上运行是最明智的选择。
Spark 是有任务的黑名单机制的,但是这个配置在官方文档里面并没有写,可以设置下面的参数,比如设置成一分钟之内不要把任务发到这个 Executor 上了,单位是毫秒。
spark.scheduler.executorTaskBlacklistTime 60000 ms