概述
在Spark 或者 Hadoop MaReduce 的分布式计算框架中,数据被按照 key 分成一块一块的分区,打散分布在集群中的各个节点的物理存储或内存空间中,每个计算任务一次处理一个分区,但 map 端和 reduce 端的计算任务并非按照一种方式对相同的分区进行计算,例如,当需要对数据进行排序时,就需要将 key 相同的数据分布到同一个分区中,原分区的数据需要被打散重组,这个按照一定的规则对数据重新分区的过程就是 Shuffle(洗牌)。
Spark Shuffle 的两个阶段
对于Spark 来讲,一些 Transformation 或者 action 算子会让 RDD 产生宽依赖,即parent RDD中的每个Partition被child RDD中的多个Partition使用,这时便需要进行Shuffle,根据Record的key对parent RDD进行重新分区。
以Shuffle为边界,Spark将一个Job划分为不同的Stage,这些Stage构成了一个大粒度的DAG。Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是Child Stage的第一步。如下图所示:
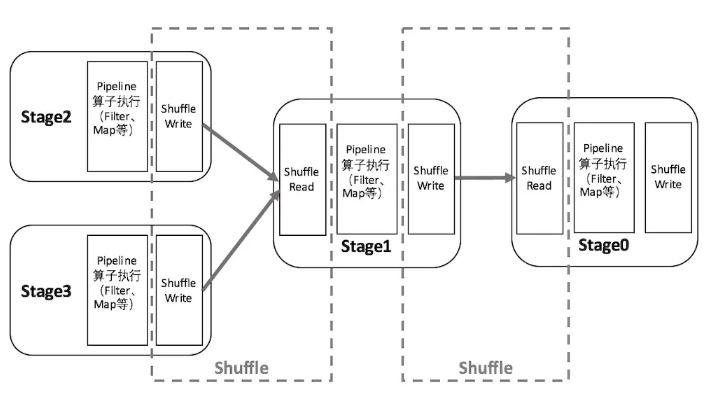
执行Shuffle 的主体是 Stage 中并发任务,这些任务分 ShuffleMap Task 和 ResultTask 两种,ShuffleMap Task要进行 Shuffle,ResultTask 负责返回计算结果,一个 Job 中只有最后的 Stage 采用ResultTask,其他均为 ShuffleMap Task。如果按照 map 端和 reduce 端来分析的话,ShuffleMap Task可以即是map 端任务,又是 reduce端任务,因为 Spark 中的Shuffle 是可以串行的,ResultTask则只能充当 reduce 端任务的角色。
Spark Shuffle 的流程简单抽象为以下几个步骤:
- Shuffle Write
- Map side combine (if need)
- Write to local output file
- Shuffle Read
- Block fetch
- Reduce side combine
- Sort (if need)
Write 阶段发生于 ShuffleMap Task 对该 Stage 的最后一个 RDD 完成了 map 端计算之后,首先会判断是否需要对计算结果进行聚合,然后将最终结果按照不同的 reduce 端进行区分,写入当前节点的本地磁盘。
Reduce阶段开始于 reduce 端的任务读取 ShuffledRDD 之时,首先通过远程或本地数据拉取获得 Write 阶段各个节点中属于当前任务的数据,根据数据的 Key 进行聚合,然后判断是否需要排序,最后生成新的 RDD。
Spark Shuffle 具体实现的演进
在具体的实现上,Shuffle 经历了 Hash 、Sort、Tungsten-Sort三阶段:
-
Spark 0.8及以前Hash Based Shuffle-
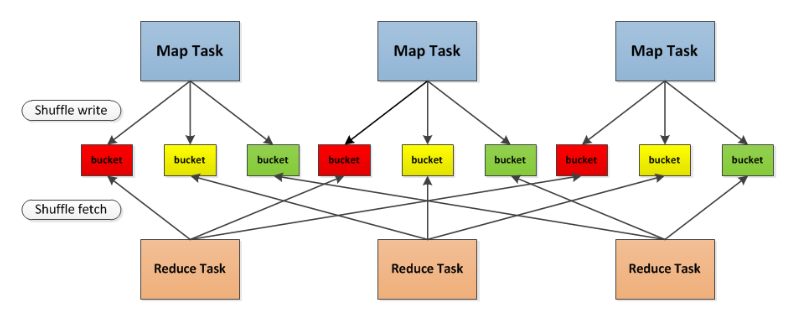
在Shuffle Write 过程按照 Hash 的方式重组 Partition 的数据,不进行排序。每个 map 端的任务为每个 reduce 端的 Task 生成一个文件,通常会产生大量的小文件(即对应的
M * R 个中间文件,其中 M 表示map 端的 Task 数量,R 表示 reduce 端的 Task 个数),伴随大量的随机磁盘 IO 操作与大量的内存开销。 -
在Shuffle Read 过程如果有 combiner 操作,那么它会把拉到的数据保存在一个 Spark 封装的哈希表(AppendOnlyMap)中进行合并。
-
在代码结构上:
-
org.apache.spark.storage.ShuffleBlockManager
负责 Shuffle Write -
org.apache.spark.BlockStoreShuffleFetcher
负责 Shuffle Read -
org.apche.spark.Aggregator
负责 combine,依赖于 AppendOnlyMap
-
-
举例说明:
假如3个 map task , 3个 reduce ,则会产生9个小文件。
-
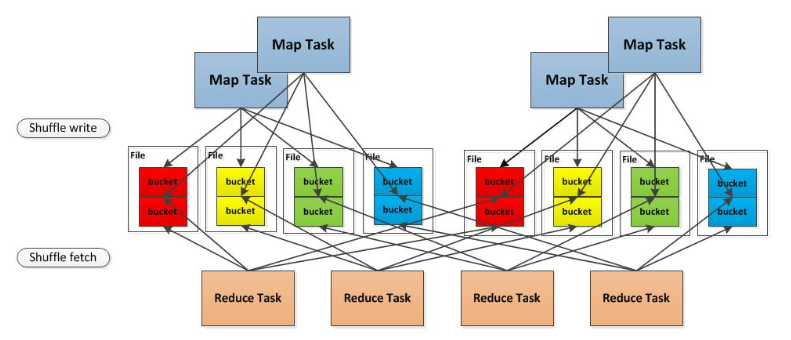
Spark 0.8.1为Hash Based Shuffle引入File Consolidation机制- 通过文件合并,中间文件的生成方式修改为每个执行单位(一个Executor中的执行单位等于 Core 的个数除以每个 Task 所需的 Core数目)为每个 reduce 端的任务生成一个文件。最终可以将文件个数从
M * R修改为E * C / (T * R),其中,E 表示Executor 的个数,C表示每个 Executor 中可用 Core 的个数,T 表示 Task 所分配的 Core 的个数。是否采用 Consolidate 机制,需要配置spark.shuffle.consolidateFiles参数
- 通过文件合并,中间文件的生成方式修改为每个执行单位(一个Executor中的执行单位等于 Core 的个数除以每个 Task 所需的 Core数目)为每个 reduce 端的任务生成一个文件。最终可以将文件个数从
举例说明:
4个map task, 4个reducer, 如果不使用 Consolidation机制, 会产生 16个小文件。
在File Consolidation机制下,现在这 4个 map task 分两批运行在 2个core上, 这样只会产生 8个小文件
-
Spark 0.9引入 ExternalAppendOnlyMap- 在 combine 的时候,可以将数据 spill 到磁盘,然后通过堆排序 merge
- 具体参考这篇大神的文章Shuffle 过程
-
Spark 1.1引入Sort Based Shuffle,但默认仍为Hash Based Shuffle-
在 Sort Based Shuffle 的 Shuffle Write 阶段,map 端的任务会按照 Partition id 以及 key 对记录进行排序。同时将全部结果写到一个数据文件中,同时生成一个索引文件,reduce 端的 Task可以通过该索引文件获取相关的数据。
-
在代码结构上:-
从以前的 ShuffleBlockManager 中分离出 ShuffleManager 来专门管理 Shuffle Write 和 Shuffle Reader。
两种 Shuffle 方式分别对应-
org.apache.spark.shuffle.hash.HashShuffleManager 和 org.apache.spark.shuffle.sort.SortShuffleManager ,可以通过
spark.shuffle.manager参数设置。两种 Shuffle 方式有各自的 ShuffleWriter:-
org.apache.spark.shuffle.hash.HashShuffle
-
org.apache.spark.shuffle.sort.SortShuffleWriter
但是共用了一个 ShuffleReader,即org.apache.spark.util.collection.ExternalSort
-
-
-
-
-
Spark 1.2默认的Shuffle方式改为Sort Based Shuffle -
Spark 1.4引入Tungsten-Sort Based Shuffle- 将数据记录用序列化的二进制方式存储,把排序转化成指针数组的排序,引入堆外内存空间和新的内存管理模型,这些技术决定了使用 Tungsten-Sort 要符合一些严格的限制,比如 Shuffle dependency 不能带有aggregation、输出不能排序等。由于堆外内存的管理基于 JDK Sun Unsafe API ,故 Tungsten-Sort Based Shuffle 也被称为 Unsafe Shuffle。
在代码层面:- 新增 org.apache.spark.shuffle.unsafe.UnsafeShuffleManager
- 新增 org.apache.spark.shuffle.unsafe.UnsafeShuffleWriter (用 java 实现)
- 新增 org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter (用 java 实现)
- ShuffleReader 复用 HashShuffleReader
-
Spark 1.6Tungsten-sort 并入 Sort Based Shuffle- 由 SortShuffleManager 自动判断选择最佳 Shuffle 方式,如果检测到满足 Tungsten-sort 条件会自动采用 Tungsten-sort Based Shuffle,否则采用 Sort Based Shuffle。
在代码方面:- UnsafeShuffleManager 合并到 SortShuffleManager
- HashShuffleReader 重命名为 BlockStoreShuffleReader
- Sort Based Shuffle 和 Hash Based Shuffle 仍共用 ShuffleReader
-
Spark 2.0Hash Based Shuffle 退出历史舞台- 从此 Spark 只有 Sort Based Shuffle。
Spark Shuffle 源码结构
这里以 Spark 2.1 为例简单介绍一下 Spark Shuffle 相关部分的代码结构
-
Shuffle Write
-
ShuffleWriter 的入口链路
org.apache.spark.scheduler.ShuffleMapTask #runTask ---> org.apache.spark.shuffle.sort.SortShuffleManager #getWriter ---> org.apache.spark.shuffle.sort.SortShuffleWriter #write(如果是普通sort) ---> org.apache.spark.shuffle.sort.UnsafeShuffleWriter #write (如果是Tungsten-sort) -
SortShuffleWriter 的主要依赖
org.apache.spark.util.collection.ExternalSorter 负责按照(partition id, key)排序,如果需要Map side combine,需要提供aggregator ---> org.apache.spark.util.collection.PartitionedAppendOnlyMap -
UnsafeShuffleWriter 的主要依赖
org.apache.spark.shuffle.sort.ShuffleExternalSorter (Java实现) -
BypassMergeSortShuffleWriter 的主要依赖
org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter (Java实现)
-
-
Shuffle Read
-
ShuffleReader 的入口链路
org.apache.spark.rdd.ShuffledRDD #compute ---> org.apache.spark.shuffle.sort.SortShuffleManager #getReader ---> org.apache.spark.shuffle.BlockStoreShuffleReader #read -
ShuffleReader 主要依赖
org.apache.spark.Aggregator 负责combine ---> org.apache.spark.util.collection.ExternalAppendOnlyMap org.apache.spark.util.collection.ExternalSorter 取决于是否需要对最终结果进行排序
-