概述
Spark Shuffle 是 spark job 中某些算子触发的操作,更详细的说,当 RDD 依赖中出现宽依赖的时候,就会触发 shuffle 操作,shuffle 操作通常会伴随着不同的 executor / host 之间的数据复制,也正是如此,导致 shuffle 的代价高以及对应的复杂性。
举个简单的例子,spark 中算子 reduceByKey,该算子会生成一个新的 RDD ,这个心的 RDD 中会对父 RDD 中相同 key 的 value 按照指定的函数操作形成一个新的 value。复杂的地方在于,相同的 key 数据可能存在于父 rdd 的多个 partition 中,这就需要我们读取所有 partition 中相同 key 值的数据然后聚合再做计算,这就是一个典型的 shuffle 操作。
产生 shuffle 的算子大致有以下三类:
- repartion 操作:repartition , coalesce 等
- ByKey 操作:groupByKey , reduceByKey 等
- join 操作: cogroup join 等
shuffle 操作通常会伴随着磁盘 io , 数据的序列化/反序列化 ,网络 io ,这些操作相对比较耗时间,往往会成为一个分布式计算任务的瓶颈,spark 也为此做了很多工作对 spark shuffle 进行优化。从最早的 hash based shuffle 到 consolidateFiles 优化,再到 1.2 的默认 sort based shuffle ,以及最近的 Tungsten-sort Based Shuffle ,spark shuffle 一直在不断的演进。关于这部分演进的内容可以参考 Spark shuffle 版本迭代历程
整体来说,可以分为 hash based shuffle 和 sort based shuffle ,不过随着 spark shuffle 的演进,两者的界限越来越模糊,虽然 spark 2.0 版本中 hash base shuffle 退出了历史舞台,其实只是作为 Sort Based Shuffle 的一种 case 出现。
Spark Shuffle 过程
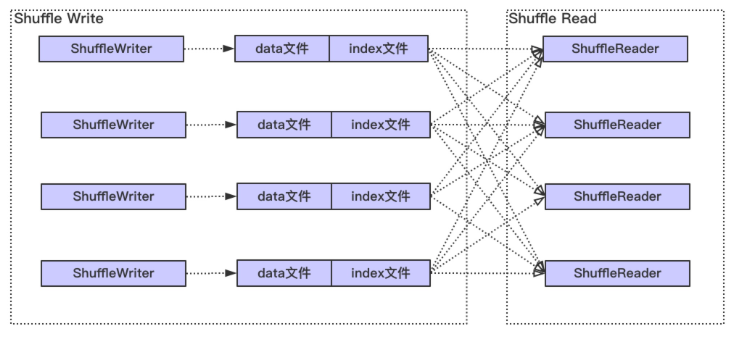
整体上 Spark Shuffle 具体过程如下图,主要分为两个阶段:Shuffle Write 和 Shuffle Read
Write 阶段大体经历排序(最低要求是需要按照分区进行排序),可能的聚合(combine) 和 归并(有多个文件spill 磁盘的情况),最终每个写 Task 会产生数据和索引两个文件。其中,数据文件会按照分区进行存储,即相同分区的数据在文件中是连续的,而索引文件记录了每个分区在文件中的起始位置和结束位置。
而对于 Shuffle Read,首先可能需要通过网络从各个 Write 任务节点获取给定分区的数据,即数据文件中某一段连续的区域,然后经过排序,归并等过程,最终形成计算结果。
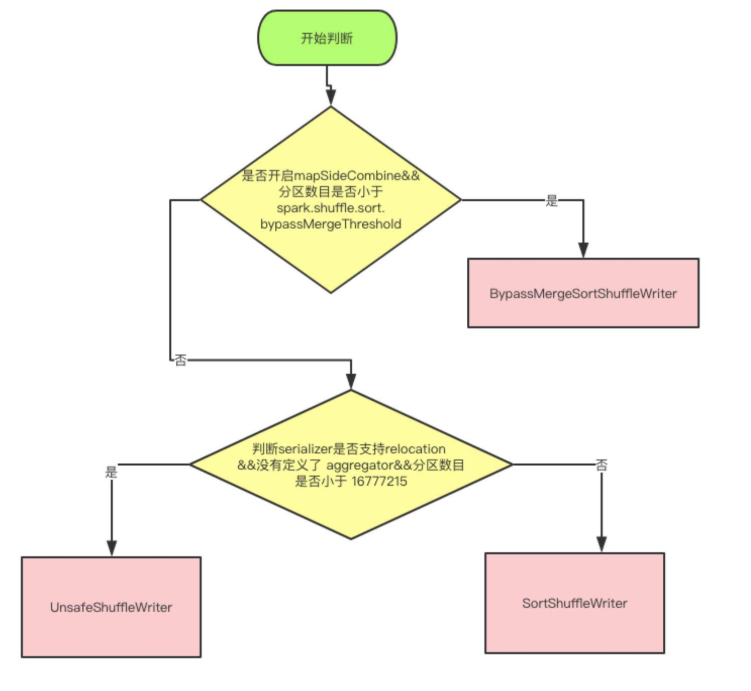
因为从 spark 2.0 开始 spark shuffle 都是基于 sort based shuffle。shuffle 的整个生命周期都是由 shuffleManager 来管理,spark 2.x 唯一的支持方式是 SortShuffleManager , SortShuffleManager 中定义了 writer 和 reader 。reader 只有一种运行模式,而 writer 有三种运行模式:
- BypassMergeSortShuffleWriter
- SortShuffleWriter
- UnsafeShuffleWriter
三种 writer 分类
-
上面是使用哪种 writer 的判断依据,是否开启 mapSideCombine 这个判断,是因为有些算子会在 map 端先进行一次 combine ,减少数据传输。因为 BypassMergeSortShuffleWriter 会临时输出 Reducer 个 (分区数目)小文件,所以分区数必须要小于一个阈值,默认是小于 200。
-
UnsafeShuffleWriter 需要 Serializer 支持 relocation ,Serializer 支持 relocation:原始数据首先被序列化处理,并且再也不需要反序列化,在其对应的元数据被排序后,需要 Serialize 支持 relocation,在指定位置读取对应数据。
Shuffle Writer 阶段分析
BypassMergeSortShuffleWriter 分析
对于 BypassMergeSortShuffleWriter 的实现,大体实现过程是首先为每个分区创建一个临时分区文件,数据写入对应的分区文件,最终所有的分区文件合并成一个数据文件,并且产生一个索引文件,是为了索引到每个分区的起始地址,可以随机 access 某个partition的所有数据 。由于这个过程不做排序,combine(如果需要 combine 不会使用这个实现)等操作,因此对于 BypassMergeSortShuffleWriter,总体来说是不怎么耗费内存的。
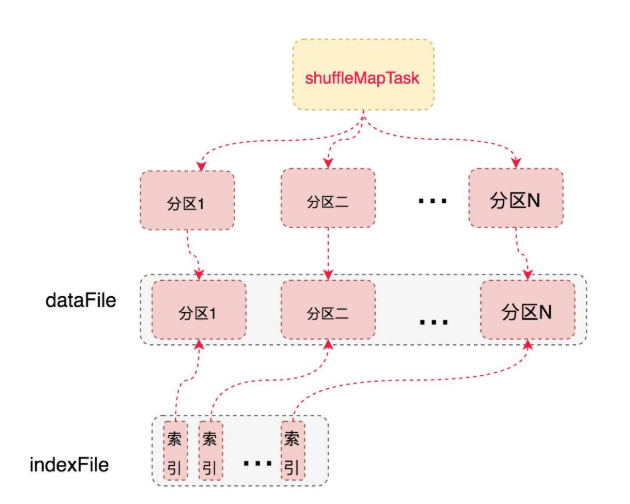
但是需要注意的是,这种方式不宜有太多分区,因为过程中会并发打开所有分区对应的临时文件,会对文件系统造成很大的压力。
具体实现就是给每个分区分配一个临时文件,对每个 record 的 key 使用分区器(模式是 hash,如果用户自定义就使用自定义的分区器)找到对应分区的输出文件句柄,直接写入文件,没有在内存中使用 buffer。最后 copyStream 方法把所有的临时分区文件拷贝到最终的输出文件,并且记录每个分区的文件起始写入位置,把这些位置数据写入索引文件中。
SortShuffleWriter 分析
首先我们可以先看一个问题,假如我有 100 亿条数据,但是我们的内存只有 1MB,但是我们磁盘很大,我们现在要对这 100 亿条数据进行排序,是没法把所有的数据一次性的 load 进内存进行排序的,这就涉及到一个外部排序的问题,假如我们的 1MB 内存只能装进 1亿条数据,每次都只能对这 1 亿条数据进行排序,排好序后输出到磁盘,总共输出 100 个文件,最后怎么把 100 个文件进行 merge 成一个全局有序的大文件?我们可以对每个文件(有序的)都取一部分头部数据作为一个 buffer,并且把这 100 个buffer 放在一个堆里面,进行堆排序,比较方式就是对所有堆元素(buffer)的 head 元素进行比较大小,然后不断的把每个堆顶的 buffer 的 head 元素 pop 出来输出到最终文件中,然后继续堆排序,继续输出。如果哪个 buffer 空了,就去对应的文件中继续补充一部分数据。最终就得到一个全局有序的大文件。
如果你能够明白上面这个例子,就差不多搞清楚了 sortshufflewirter 的实现原理,因为解决的是同一个问题。
SortShuffleWriter 是最一般的实现,也是日常使用最频繁的。SortShuffleWriter 主要委托 ExternalSorter 做数据插入,排序,归并(Merge),聚合(Combine)以及最终写数据和索引文件的工作。ExternalSorter 实现了 MemoryConsumer 接口。
-
SortShuffleWriter 中处理步骤就是
- 使用 PartitionedAppendOnlyMap 或者 PartitionedPairBuffer 在内存中进行排序,排序的 K 是 (partitionId,hash(key))这样的一个元组。
- 如果超过内存 limit , spill 到一个文件中,这个文件中元素也是有序的,首先是按照 partitionId 的排序,如果 partitionId 相同,再根据 hash(key) 进行比较排序
- 如果需要输出全局有序的文件的时候,就需要对之前所有的输出文件和当前内存中的数据结构中的数据进行 merge sort,进行全局排序
这个排序规则和上面的那个问题基本类似,不同的地方在于,需要对 key 相同的元素进行 aggregation,就是使用定义的 func 进行聚合,比如你的算子是 reduceByKey( + ),这个 func 就是加法运算,如果两个 key 相同,就会先找到所有相同的 key 进行 reduce( + ) 操作,算出一个总结果 Result ,然后输出数据 (K , Result)元素。
SortShuffleWriter 中使用 ExternalSorter 来对内存中的数据进行排序,ExternalSorter内部维护了两个集合PartitionedAppendOnlyMap、PartitionedPairBuffer, 两者都是使用了 hash table 数据结构, 如果需要进行 aggregation, 就使用 PartitionedAppendOnlyMap(支持 lookup 某个Key,如果之前存储过相同key的K-V 元素,就需要进行 aggregation,然后再存入aggregation后的 K-V), 否则使用 PartitionedPairBuffer(只进行添K-V 元素)
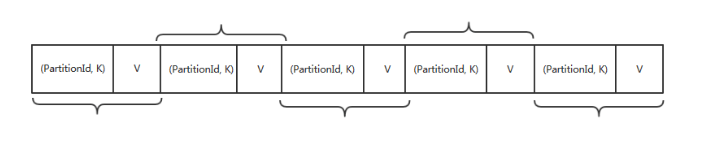
我们可以看上图, PartitionedAppendOnlyMap 中的 K 是(PatitionId, K)的元组, 这样就是先按照partitionId进行排序,如果 partitionId 相同,再按照 hash(key)再进行排序。
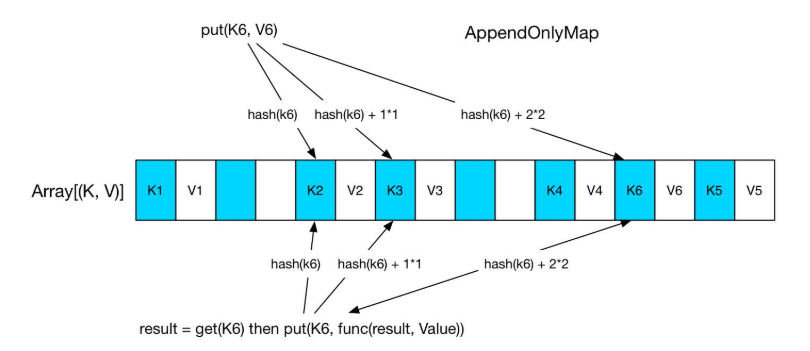
首先看下 AppendOnlyMap, 这个很简单就是个 hash table,其中的 K 是(PatitionId, hash(Key))的元组, 当要 put(K, V) 时,先 hash(K) 找存放位置,如果存放位置已经被占用,就使用 Quadratic probing 探测方法来找下一个空闲位置。对于图中的 K6 来说,第三次查找找到 K4 后面的空闲位置,放进去即可。get(K6) 的时候类似,找三次找到 K6,取出紧挨着的 V6,与先来的 value 做 func,结果重新放到 V6 的位置。
下面看下 ExternalAppendOnlyMap 结构, 这个就是内存中装不下所有元素,就涉及到外部排序,
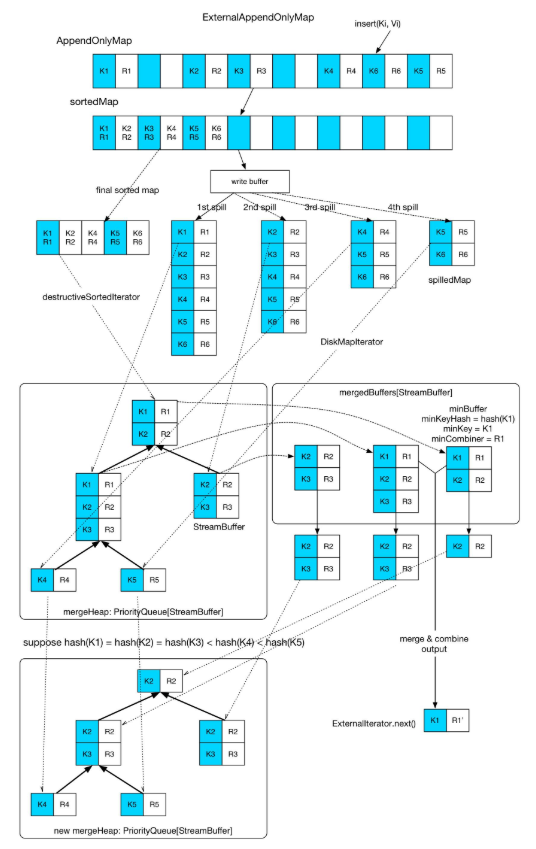
上图中可以看到整个原理图,逻辑也很简单, 内存不够的时候,先spill了四次,输出到文件中的元素都是有序的,读取的时候都是按序读取,最后跟内存剩余的数据进行 全局merge。
merge 过程就是 每个文件读取部分数据(StreamBuffer)放到 mergeHeap 里面, 当前内存中的 PartitionedAppendOnlyMap 也进行 sort,形成一个 sortedMap 放在 mergeHeap 里面, 这个 heap 是一个 优先队列 PriorityQueue, 并且自定义了排序方式,就是取出堆元素StreamBuffer的head元素进行比较大小,
val heap = new mutable.PriorityQueue[Iter]()(new Ordering[Iter] {
// Use the reverse of comparator.compare because PriorityQueue dequeues the max
override def compare(x: Iter, y: Iter): Int = -comparator.compare(x.head._1, y.head._1)
})
这样的话,每次从堆顶的 StreamBuffer 中 pop 出的 head 元素就是全局最小的元素(记住是按照(partitionId,hash(Key))排序的), 如果需要 aggregation, 就把这些key 相同的元素放在一个一个 mergeBuffers 中, 第一个被放入 mergeBuffers 的 StreamBuffer 被称为 minBuffer,那么 minKey 就是 minBuffer 中第一个 record 的 key。当 merge-combine 的时候,与 minKey 有相同的Key的records 被 aggregate 一起,然后输出。
如果不需要 aggregation, 那就简单了, 直接把 堆顶的 StreamBuffer 中 pop 出的 head 元素 返回就好了。
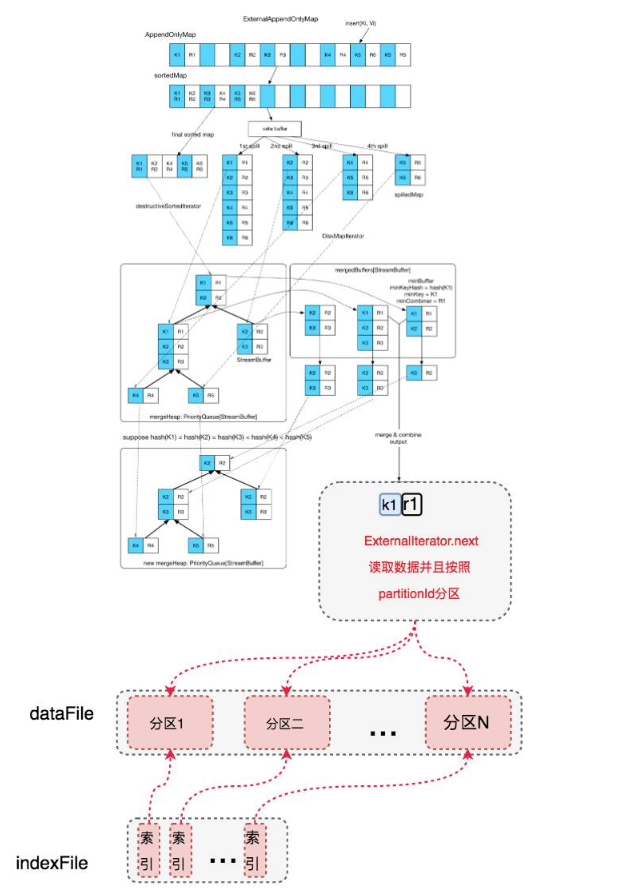
最终读取的时候,从整个 全局 merge 后的读取迭代器中读取的数据,就是按照 partitionId 从小到大排序的数据, 读取过程中使用再按照 分区分段, 并且记录每个分区的文件起始写入位置,把这些位置数据写入索引文件中。
UnsafeShuffleWriter 分析
UnsafeShuffleWriter 是对 SortShuffleWriter 的优化,大体上也和 SortShuffleWriter 差不多,在此不再赘述。从内存使用角度看,主要差异在以下两点:
一方面,在 SortShuffleWriter 的 PartitionedAppendOnlyMap 或者 PartitionedPairBuffer 中,存储的是键值或者值的具体类型,也就是 Java 对象,是反序列化过后的数据。而在 UnsafeShuffleWriter 的 ShuffleExternalSorter 中数据是序列化以后存储到实际的 Page 中,而且在写入数据过程中会额外写入长度信息。总体而言,序列化以后数据大小是远远小于序列化之前的数据。
另一方面,UnsafeShuffleWriter 中需要额外的存储记录(LongArray),它保存着分区信息和实际指向序列化后数据的指针(经过编码的Page num 以及 Offset)。相对于 SortShuffleWriter, UnsafeShuffleWriter 中这部分存储的开销是额外的。
Shuffle Read 阶段分析
Spark Shuffle Read 主要经历从获取数据,序列化流,添加指标统计,可能的聚合 (Aggregation) 计算以及排序等过程。大体流程如下图。
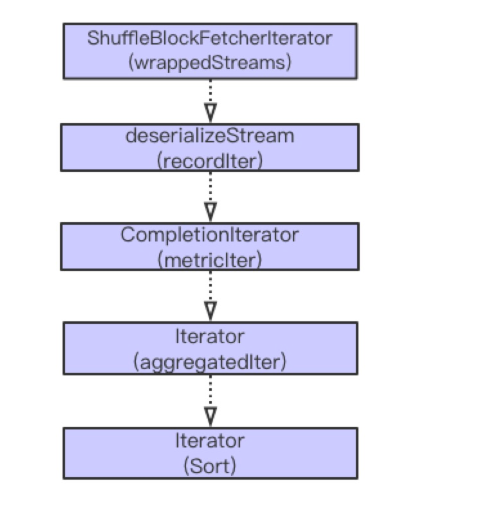
以上计算主要都是迭代进行。在以上步骤中,比较复杂的操作是从远程获取数据,聚合和排序操作。接下来,依次分析这三个步骤内存的使用情况。
1,数据获取分为远程获取和本地获取。本地获取将直接从本地的 BlockManager 取数据, 而对于远程数据,需要走网络。在远程获取过程中,有相关参数可以控制从远程并发获取数据的大小,正在获取数据的请求数,以及单次数据块请求是否放到内存等参数。具体参数包括 spark.reducer.maxSizeInFlight (默认 48M),spark.reducer.maxReqsInFlight, spark.reducer.maxBlocksInFlightPerAddress 和 spark.maxRemoteBlockSizeFetchToMem。考虑到数据倾斜的场景,如果 Map 阶段有一个 Block 数据特别的大,默认情况由于 spark.maxRemoteBlockSizeFetchToMem 没有做限制,所以在这个阶段需要将需要获取的整个 Block 数据放到 Reduce 端的内存中,这个时候是非常的耗内存的。可以设置 spark.maxRemoteBlockSizeFetchToMem 值,如果超过该阈值,可以落盘,避免这种情况的 OOM。 另外,在获取到数据以后,默认情况下会对获取的数据进行校验(参数 spark.shuffle.detectCorrupt 控制),这个过程也增加了一定的内存消耗。
2,对于需要聚合和排序的情况,这个过程是借助 ExternalAppendOnlyMap 来实现的。整个插入,Spill 以及 Merge 的过程和 Write 阶段差不多。总体上,这块也是比较消耗内存的,但是因为有 Spill 操作,当内存不足时,可以将内存数据刷到磁盘,从而释放内存空间。
Shuffle 相关参数调优
以下是Shffule过程中的一些主要参数,这里详细讲解了各个参数的功能、默认值以及基于实践经验给出的调优建议。
spark.shuffle.file.buffer
- 默认值:32k
- 参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
- 调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight
- 默认值:48m
- 参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
- 调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetries
- 默认值:3
- 参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
- 调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
spark.shuffle.io.retryWait
- 默认值:5s
- 参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
- 调优建议:建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
spark.shuffle.memoryFraction
- 默认值:0.2
- 参数说明:该参数代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例,默认是20%。
- 调优建议:在资源参数调优中讲解过这个参数。如果内存充足,而且很少使用持久化操作,建议调高这个比例,给shuffle read的聚合操作更多内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。在实践中发现,合理调节该参数可以将性能提升10%左右。
spark.shuffle.manager
- 默认值:sort
- 参数说明:该参数用于设置ShuffleManager的类型。Spark 1.5以后,有三个可选项:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的默认选项,但是Spark 1.2以及之后的版本默认都是SortShuffleManager了。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。
- 调优建议:由于SortShuffleManager默认会对数据进行排序,因此如果你的业务逻辑中需要该排序机制的话,则使用默认的SortShuffleManager就可以;而如果你的业务逻辑不需要对数据进行排序,那么建议参考后面的几个参数调优,通过bypass机制或优化的HashShuffleManager来避免排序操作,同时提供较好的磁盘读写性能。这里要注意的是,tungsten-sort要慎用,因为之前发现了一些相应的bug。
spark.shuffle.sort.bypassMergeThreshold
- 默认值:200
- 参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
- 调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
spark.shuffle.consolidateFiles
- 默认值:false
- 参数说明:如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,会大幅度合并shuffle write的输出文件,对于shuffle read task数量特别多的情况下,这种方法可以极大地减少磁盘IO开销,提升性能。
- 调优建议:如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shffle.manager参数手动指定为hash,使用HashShuffleManager,同时开启consolidate机制。在实践中尝试过,发现其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。