概述
HBase 和 Hive在大数据架构中处于不同位置,HBase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是相互配合使用。
两者的区别
整体区别
HBase: Hadoop database 的简称,也就是基于 Hadoop 数据库,是一种NoSQL数据库,主要适用于海量的明细数据(十亿,百亿)的随机实时查询,如日志明细,交易清单,轨迹行为等。
Hive : Hive 是 Hadoop 数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理 HDFS上的结构化数据,适用于离线的批量数据计算。
- 通过元数据来描述 HDFS 上的结构化文本数据,通俗点来说,就是定义一张表来描述 HDFS 上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多 SQL on Hadoop 的计算引擎均用的是 Hive 的元数据,如 Spark SQL 、Impala等。
- 基于第一点,通过 SQL 处理和计算 HDFS 的数据,Hive 会将 SQL 翻译为 MapReduce 来处理数据
细致区别
- Hive 中的表是纯逻辑表,就只是表的定义等,即表的元数据。Hive 本身不存储数据,它完全依赖于 HDFS 和 MapReduce。这样就可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,并将 SQL 语句最终转换为 MapReduce 任务进行运行。而 HBase 表是物理表,适合存放非结构化的数据。
- Hive 是基于 MapReduce 来处理数据,而 MapReduce 处理数据是基于行的模式;HBase 处理数据是基于列的,适合海量数据的随机访问。
- HBase 表是疏松存储的,因此用户可以给行定义各种不同的列;而 Hive 表是稠密型的,即定义多少列,每一行有存储固定列数的数据。
- Hive 使用 Hadoop 来分析处理数据,而 Hadoop 系统是批处理系统,因此不能保证处理的低延迟问题;而HBase 是近实时系统,支持实时查询。
- Hive 不提供 row-level 更新,它适合于大量 append-only 数据集(如日志)的批任务处理。而基于 HBase 的查询,支持 row-level 更新。
- Hive 提供完整的SQL实现,通常被用来做一些历史数据的挖掘,分析。而 HBase 不适用与有 join ,多级索引,表关系复杂的应用场景。
两者之间的关系
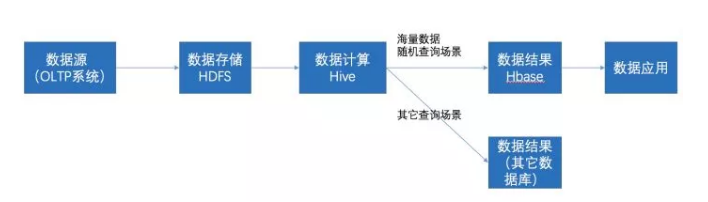
在大数据架构中,Hive 和 HBase 是协作关系,数据流一般如下图:
- 通过 ETL 工具数据源抽取到 HDFS 存储
- 通过 Hive 清洗、处理和计算原始数据
- Hive 清洗处理后的结果,如果是面向海量数据随机查询场景的可存入HBase
- 数据应用从 HBase 查询数据