概述
Apache Flink作为流处理的新贵,近年来可谓是相当火,今年阿里巴巴收购了德国的Flink,几年前阿里巴巴在Flink的基础上二次开发了Blink。阿里巴巴在实时计算这一块对社区的贡献还是很大的,从几年前的Apache Strom 到Apache JStorm再到现在的Apache Flink。
构建一个流的WC
注意:pom.xml文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>flink_study</groupId>
<artifactId>com.justdodt.flink</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<hadoop.version>2.7.6</hadoop.version>
<flink.version>1.7.2</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.22</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.8</arg>
</args>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
Java代码
package com.justdodt.flinkstudy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* @Author:JustDoDT
* @Description:
* @Date:Create in 2:13 2019/8/13
* @Modified By:
*/
public class SocketWindowWordCount {
public static void main(String[] args) throws Exception {
// 创建 execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 通过连接 socket 获取输入数据,这里连接到本地9000端口,如果9000端口已被占用,请换一个端口
DataStream<String> text = env.socketTextStream("192.168.100.111", 9000, "\n");
// 解析数据,按 word 分组,开窗,聚合
DataStream<Tuple2<String, Integer>> windowCounts = text
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
for (String word : value.split("\\s")) {
out.collect(Tuple2.of(word, 1));
}
}
})
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
// 将结果打印到控制台,注意这里使用的是单线程打印,而非多线程
windowCounts.print().setParallelism(1);
env.execute("Socket Window WordCount");
}
}
注意:在Java代码中,如果想在自己的IDE本地查看 Flink Web UI 的话,还需要在代码中添加如下的内容
Configuration config = new Configuration(); config.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER, true); StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(config); // 创建 execution environment // final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
然后用 http://localhost:8081 访问
Scala代码
package com.justdodt.flink
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @Author:JustDoDT
* @Description:
* @Date:Create in 17:27 2019/8/12
* @Modified By:
*/
object WordCount {
def main(args: Array[String]): Unit = {
//Set up the execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
//Get input data
val text = env.socketTextStream("192.168.100.111", 9000,'\n')
//Split
val counts = text
.flatMap(_.split("\t"))
.map((_,1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
//Results
counts.print().setParallelism(1)
// Execute program
env.execute("Streaming WordCount")
}
}
注意:在Java代码中,如果想在自己的IDE本地查看 Flink Web UI 的话,还需要在代码中添加如下的内容
val conf = new Configuration() conf.setBoolean(ConfigConstants.LOCAL_START_WEBSERVER,true) val env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf) //Set up the execution environment // val env = StreamExecutionEnvironment.getExecutionEnvironment
并且还需要在 pom.xml 文件添加如下内容
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-web_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency>
在Linux中启动nc命令
[hadoop@hadoop001 data]$ nc -l 9000
hello hi
world hi hello
hello
wolrd
执行结果

观察Flink UI
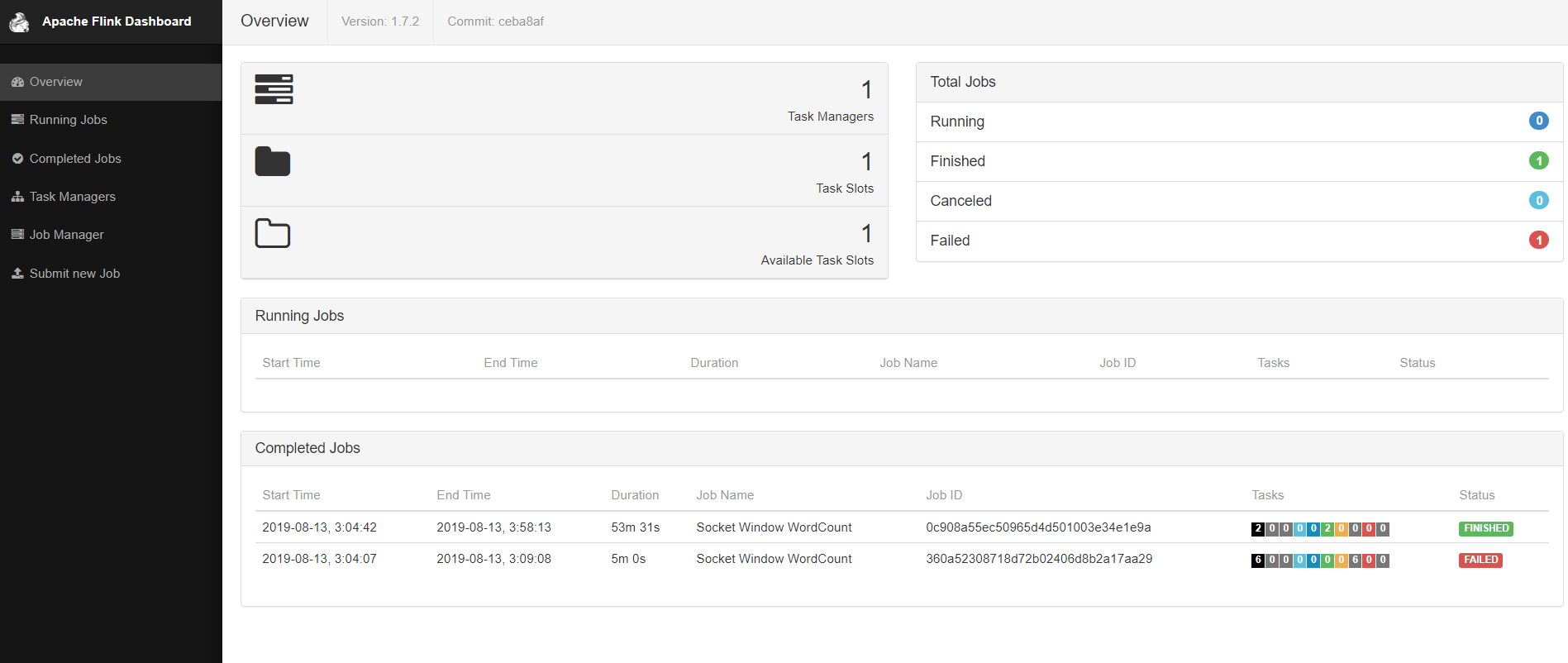
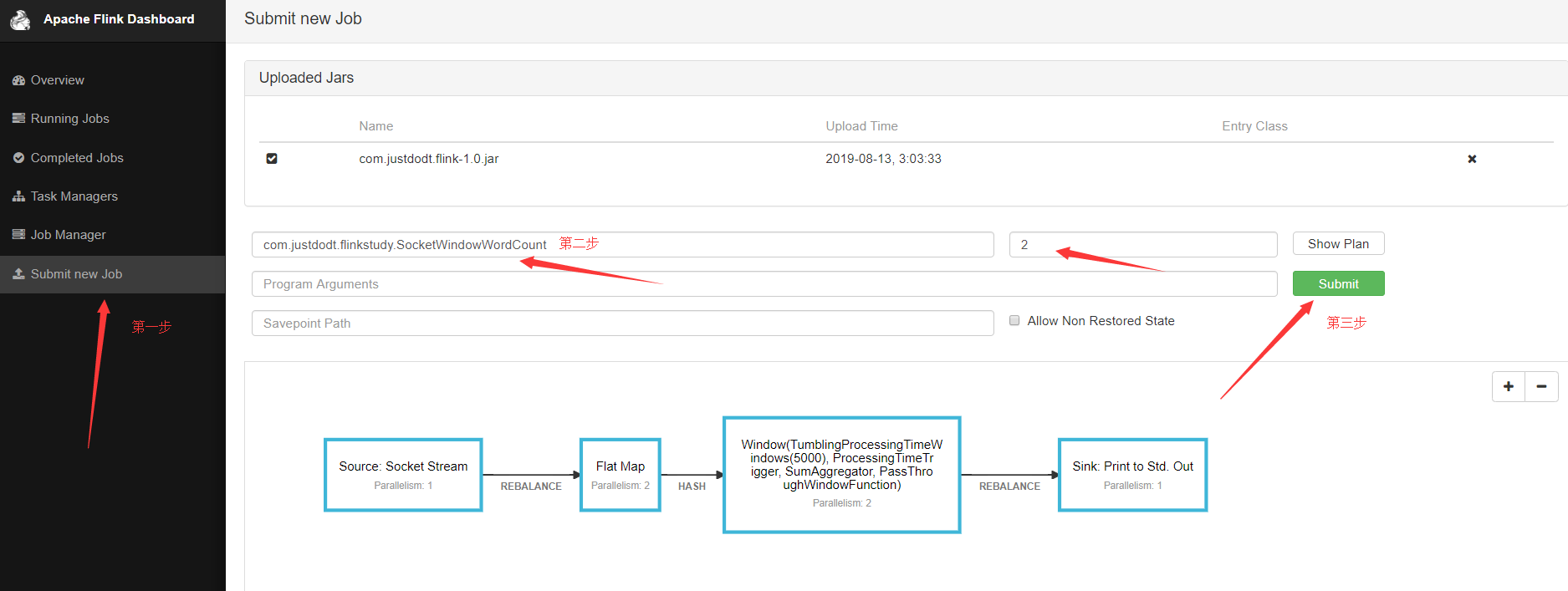
再上传一个Flink jar
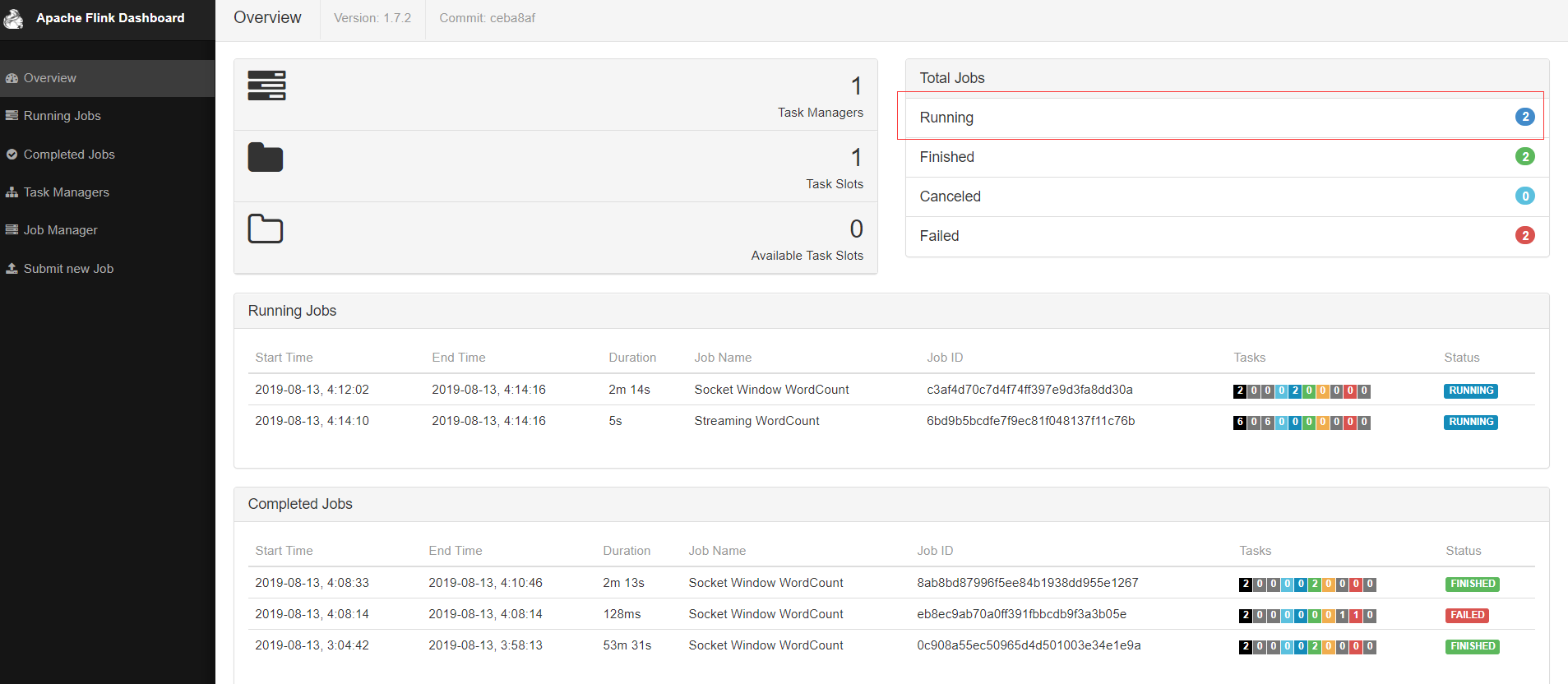
由下图可以看见有2个正在运行的程序
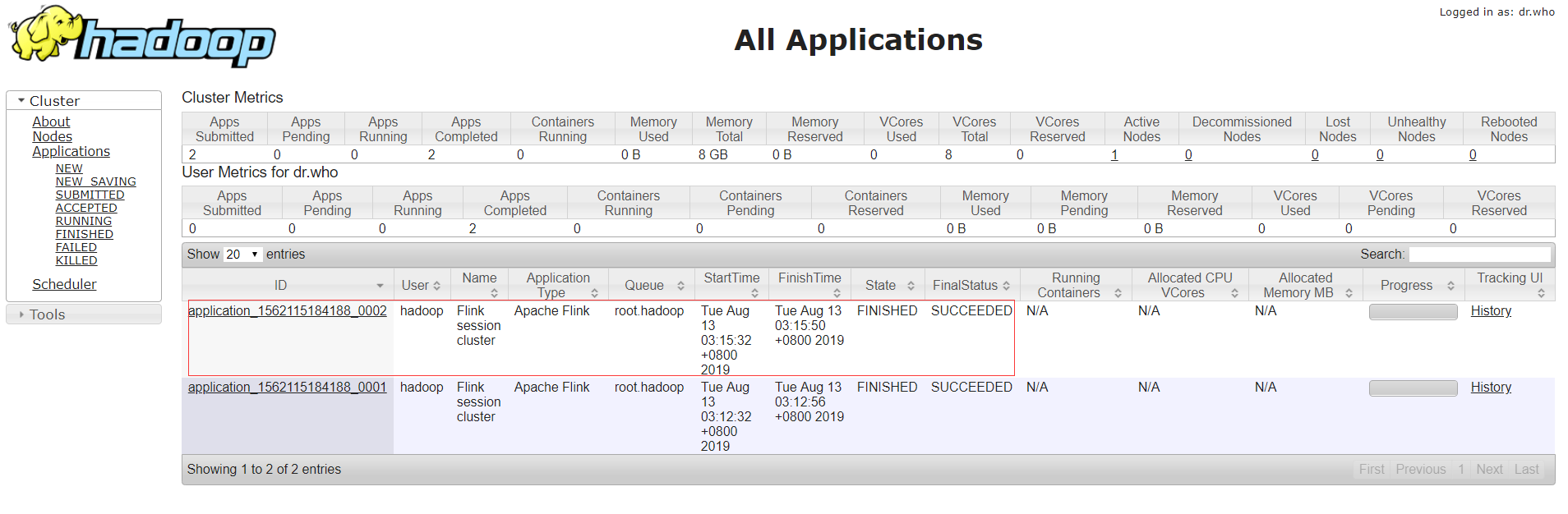
把作业提交到yarn上运行
[hadoop@hadoop001 flink-1.7.2]$ bin/flink run -m yarn-cluster -yn 2 examples/streaming/WordCount.jar --input hdfs://hadoop001/input/data.txt --output hdfs://hadoop001/output/flink
查看yarn运行情况
查看HDFS输出结果
[hadoop@hadoop001 data]$ hdfs dfs -text /output/flink
(hello,1)
(hi,1)
(hello,2)
(china,1)
(beijing,1)
(hello,3)
(world,1)
(hi,2)
总结
Flink和Spark类似,也可以跑在yarn上,跑在K8s上,flink是完全实时处理,Flink UI界面比Spark UI 做得好,她可以直接提交jar然后运行,这个和Azkaban类似。