概述
不管是工作中对于Kafka端消息的零丢失还是在面试中,这个问题都是很常见的问题。工作会用到,面试必问,所以此问题必须要掌握。那么 Kafka 到底在什么情况下才能保证消息不丢失呢?一句话概括,Kafka只对“已提交”的消息做有限度的持久化保证。
- 什么是已提交的消息
当Kafka的若干个 Broker 成功地接收到一条消息并写入到日志文件后,她们会告诉生产者程序这条消息已成功提交。此时,这条消息在 Kafka 看来就正式变为 “已提交” 消息了。那么为啥是若干个 Broker 呢?这取决于你对“已提交”的定义。你可以选择只要有一个 Broker成功保存该消息是已提交,也可以是令所有 Broker 都成功保存该消息才算是已提交。不论哪种情况下,Kafka 只对已提交的消息做持久化保证这件事情是不变的。
- 有限度的持久化保证
也就是说 Kafka 不可能保证在任何情况下都做到不丢失消息。“有限度“是指你的消息保存在 N 个 Kafka Broker 上,那么这个前提条件就是这 N 个 Broker 中至少有 1 个存活。只要这个条件成立,Kafka 就能保证你的这条消息永远不会丢失。
Kafka 是能做到不丢失消息的,但是这些消息必须是已提交的,而且还要满足一定的条件。
消息丢失的案例
案例1:生产者程序丢失数据
Producer 程序丢失消息,这应该算是被抱怨最多的数据丢失场景了。Producer 应用向 Kafka 发送消息,最后发现 Kafka 没有保存。为啥会出现这样呢?目前 Kafka Producer 是异步发送消息的,也就是说如果你调用的是 producer.send(msg) 这个 API ,那么她通常会立即返回,但此时你就不能认为消息发送已成功完成。如果用这个方式,可能会有哪些因素导致消息没有发送成功呢? 其实原因有很多,例如网络抖动,导致消息压根就没有发送到 Broker 端;或者消息本身不合格导致 Broker 拒绝接收(比如消息太大了,超过了 Broker 的承受能力)等。
- 解决此问题的方法
Producer 永远要使用带有回调通知的发送 API,也就是说不要使用 producer.send(msg),而要使用 producer.send(msg.callback)。这里的 callback(回调),她能准确的告诉你消息是否真的提交成功了。一旦出现消息失败的情况,你就可以有针对性的进行处理。
案例2:消费者程序丢失数据
Consumer 端丢失数据主要体现在 Consumer 端要消费的消息不见了。Consumer 程序有个 ”位移“ 的概念,表示的是这个 Consumer 当前消费到的 Topic 分区的位置。如下图官网的图所示。
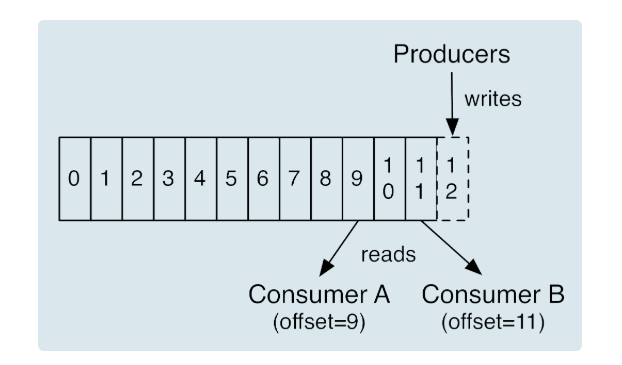
相比对于 Consumer A 而言,她当前的位移值就是9,Consumer B 的位移值是 11。这里的 offset 类似于我们看书时使用的书签,她会标记我们当前阅读到了多少页,下次翻书的时候我们能直接跳到书签页继续阅读。正确使用书签的两个步骤:第一步是读书,第二步是更新书签页。如果这两步的顺序颠倒了,就可能出现这样的场景:当前的书签页是第 90 页,我先将书签放到第 100 页上,之后开始读书。当阅读到第 95 页时,我临时有事中止了阅读。当我下次直接跳到书签页阅读,那么就丢失了第 96 ~ 99 页的内容,即这些消息就丢失了。
同理,Kafka 中的 Consumer 端消息就是这么一回事。
- 解决此问题的方法
维持先消费消息(阅读),再更新位移(书签)的顺序即可。这样就能最大限度地保证消息不丢失。
当然这种方式可能带来的问题是消息的重复消费,类似于同一页书被读了很多遍。
多线程异步消费消息
除了上面的2种情况,还有下面这种情况会丢失消息。对于 Kafka 而言,这就好比于 Consumer 程序从 Kafka 获取到消息后开启了多个线程异步处理消息,而 Consumer 程序自动地向前更新位移。假如其中某个线程运行失败了,她负责的消息没有被成功处理,但位移已经被更新了,因此这条消息对于 Consumer 而言实际上是丢失了。这里的关键在于 Consumer 自动提交位移,你没有真正地确认消息是否真的被消费就 ”盲目“ 地更新了位移。
- 解决此问题的方法
如果是多线程异步处理消费消息,Consumer 程序不要开启自动提交位移,而是要应用程序手动提交位移。
注意:单个 Consumer 程序使用多线程来消费消息代码异常困难,因为你很难正确处理位移的更新,也就是说避免无消费消息丢失很简单,但极易出现消息被消费了多次的情况。
Kafka 无消息丢失的参数配置
- 使用 producer.send(msg,callback) ,一定要使用带有回调通知的 send 方法
- 设置 acks = all(-1) 。
- 设置 retries 为一个较大的值。这里的 retries 同样是 Producer 的参数,对应前面提到的 Producer 自动重试。当出现网络的瞬时抖动时,消息发送可能会失败,此时配置 retries > 0 的 Producer 能够自动重试消息发送,避免消息丢失。
- 设置 unclean.leader.election.enable = false 。这是 Broker 端的参数,她控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么她一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将此参数设置为 false。
- 设置 replication.factor >= 3
- 设置 min.insync.replicas > 1。这也是 Broker 端的参数,控制的是消息至少要被写入到多少个副本才算是”已提交“。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
- 确保 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本宕机了,整个分区就无法工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置为 replication.factor = min.insync.replicas + 1
- 确保消息消费完成再提交。Consumer 端有个参数 enable.auto.commit,最好把她设置为 false,并采用手动提交位移的方式。就像前面说的,这对于单 Consumer 多线程处理的场景至关重要。