概述
2013年,ZEPL(以前称为NFLabs,是一家韩国的数据分析公司)启动了Zeppelin项目。
2014年12月23日,Zeppelin项目成为Apache Software Foundation中的孵化项目。
2016年6月18日,Zeppelin项目从Apache的孵化项目毕业,成为Apache Software Foundation的顶级项目。
2020年1月19日,Apache Zepplin已经到了0.8.2GA,0.9.0-SNAPSHOT。
什么是Apache Zeppelin
Apache Zeppelin是一个基于Web的交互式数据分析开源框架,提供了数据分析、数据可视化等功能,类似于Jupyter Notebook,不过功能比Jupyter Notebook强大很多,她是属于企业级产品,支持超过20种后端语言,比如Java/Scala/Python/SQL/MarkDown/Shell等。开发者可以自定义开发更多的解释器为Zeppelin添加执行引擎,官方现在支持的执行引擎有Spark/JDBC/Python/Alluxio/Beam/Cassandra/Elasticsearch/Flink/HBase/HDFS/Hive/Kylin
/Livy/MarkDown/Neo4j/Pig/PostgreSQL/R等。
Apache Zeppelin 架构简介
Apache Zeppelin的架构比较简单直观(如下图所示),总共分为3层
Zeppelin前端Zeppelin ServerZeppelin Interpreter
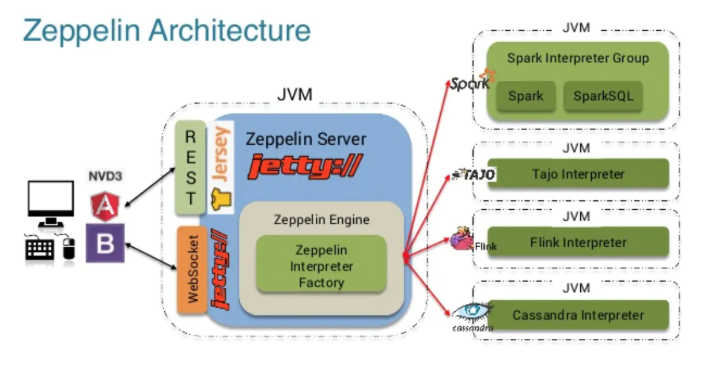
` Zeppelin前端是基于AngularJS。
Zeppelin Server是一个基于Jetty的轻量级Web Server`,主要负责以下一些功能:
- 登陆权限管理
Zeppelin配置信息管理Interpreter配置信息和生命周期管理Note存储管理- 插件机制管理
Zeppelin Interpreter组件是指各个计算引擎在Zeppelin这边的适配。比如Python,Spark,Flink等等。每个Interpreter都运行在一个JVM进程里,这个JVM进程可以是和Zeppelin Server在同一台机器上(默认方式),也可以运行在Zeppelin集群里的其他任何机器上或者K8s集群的一个Pod里,这个由Zeppelin的不同InterpreterLauncher插件来实现。InterpreterLauncher是Zeppelin的一种插件类型。
组件之间的通信机制
Zeppelin前端和Zeppelin Server之间的通信机制主要有Rest api和WebSocket两种。Zeppelin Server和Zeppelin Interpreter是通过Thrift RPC来通信,而且他们彼此之间是双向通信,Zeppelin Server可以向Zeppelin Interpreter发送请求,Zeppelin Interpreter也可以向Zeppelin Server发送请求。
源码编译安装Apache Zeppelin
Apache Zeppelin官方提供了源码包和二进制包,可以根据自己的需要下载相关的包,二进制包是包含所有的解释器,如果你只需要用到其中的几种可以通过源码编译来定制化安装。
mvn clean package -DskipTests -Phadoop-2.6 -Dhadoop.version=2.6.0 -P build-distr -Dhbase.hbase.version=1.2.0 -Dhbase.hadoop.version=2.6.0
二进制安装Apache Zeppelin
[hadoop@hadoop001 sourcecode]$ tar -zxvf zeppelin-0.8.2-bin-all.tgz -C ~/app/
#修改配置文件
[hadoop@hadoop001 conf]$ pwd
/home/hadoop/app/zeppelin-0.8.2-bin-all/conf
[hadoop@hadoop001 conf]$ cp zeppelin-env.sh.template zeppelin-env.sh
[hadoop@hadoop001 conf]$ vim zeppelin-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_144
export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
export MASTER=yarn
export SPARK_HOME=/home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0
export SPARK_SUBMIT_OPTIONS="--jars /home/hadoop/lib/mysql-connector-java-5.1.46-bin.jar"
export FLINK_HOME=/home/hadoop/app/flink-1.7.2
export HBASE_HOME=/home/hadoop/app/hbase-1.2.0-cdh5.7.0
# 修改端口,主机名
[hadoop@hadoop001 conf]$ cp zeppelin-site.xml.template zeppelin-site.xml
[hadoop@hadoop001 conf]$vim zeppelin-site.xml
<property>
<name>zeppelin.server.addr</name>
<value>192.168.100.111</value>
<description>Server binding address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>9090</value>
<description>Server port.</description>
</property>
启动Zeppelin的用户认证
Apache Zeppelin默认是以匿名用户访问的,即没有用户权限要求,如要实现用户权限限制,则需要修改zeppelin-site.xml和shiro配置文件。
# 修改zeppelin-site.xml配置文件,将以下配置项中的true改成false
<property>
<name>zeppelin.anonymous.allowed</name>
<value>false</value>
<description>Anonymous user allowed by default</description>
</property>
# 复制conf目录下的shiro.ini.template 为 shiro.ini , 将shiro.ini 的[user]块中的内容修改为以下内容:
[hadoop@hadoop001 conf]$ cp shiro.ini.template shiro.ini
[hadoop@hadoop001 conf]$ vim shiro.ini
[users]
admin = admin
user1 = password2, role1, role2
user2 = password3, role3
user3 = password4, role2
.
.
.
[urls]
/api/version = anon
#/api/interpreter/setting/restart/** = authc, roles[admin,hive]
#/api/interpreter/** = authc, roles[admin,hive]
#/api/configurations/** = authc, roles[admin,hive]
#/api/credential/** = authc, roles[admin,hive]
#/** = anon
/** = authc
启动Apache Zeppelin
[hadoop@hadoop001 ~]$ cd app/zeppelin-0.8.2-bin-all/
[hadoop@hadoop001 zeppelin-0.8.2-bin-all]$ bin/zeppelin-daemon.sh start
Log dir doesn't exist, create /home/hadoop/app/zeppelin-0.8.2-bin-all/logs
Pid dir doesn't exist, create /home/hadoop/app/zeppelin-0.8.2-bin-all/run
Zeppelin start [ OK ]
[hadoop@hadoop001 zeppelin-0.8.2-bin-all]$
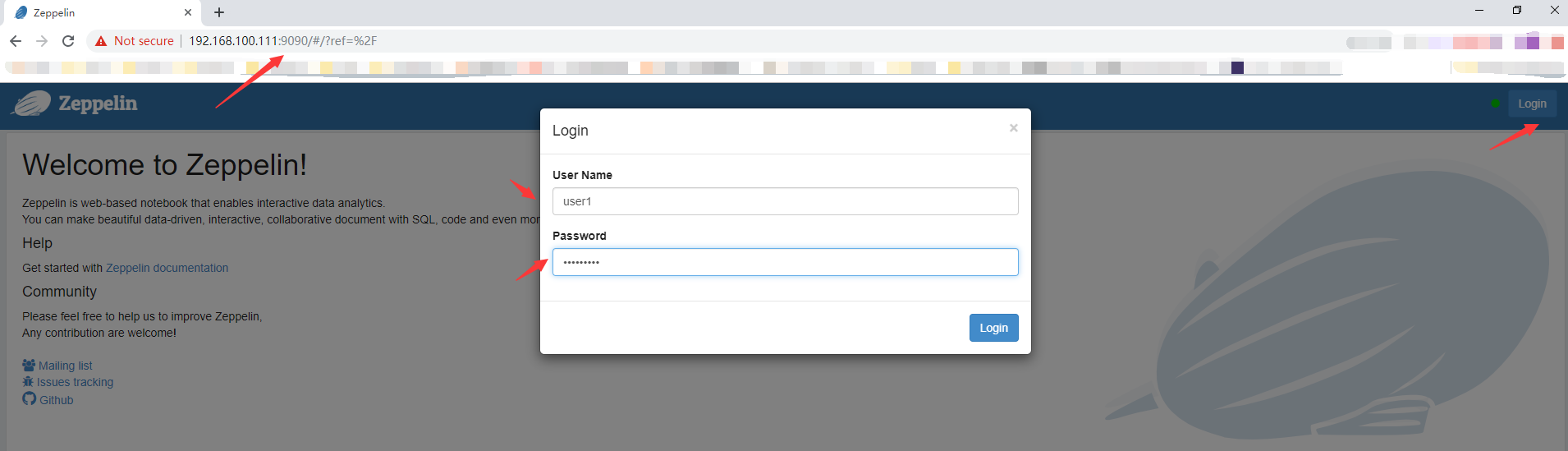
创建 mysql notebook
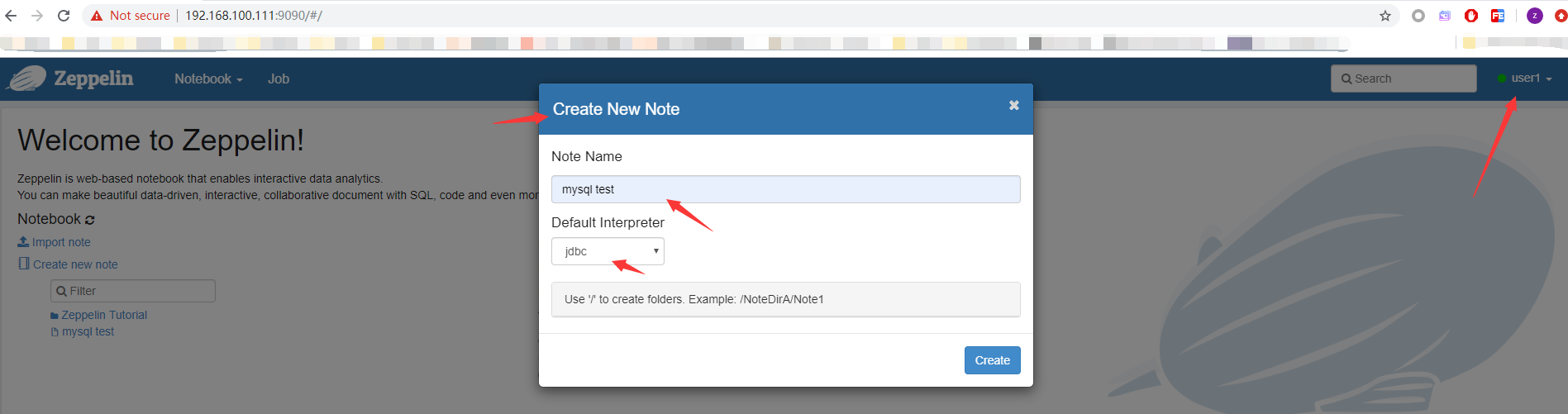

- 往下拉,选择
jdbc
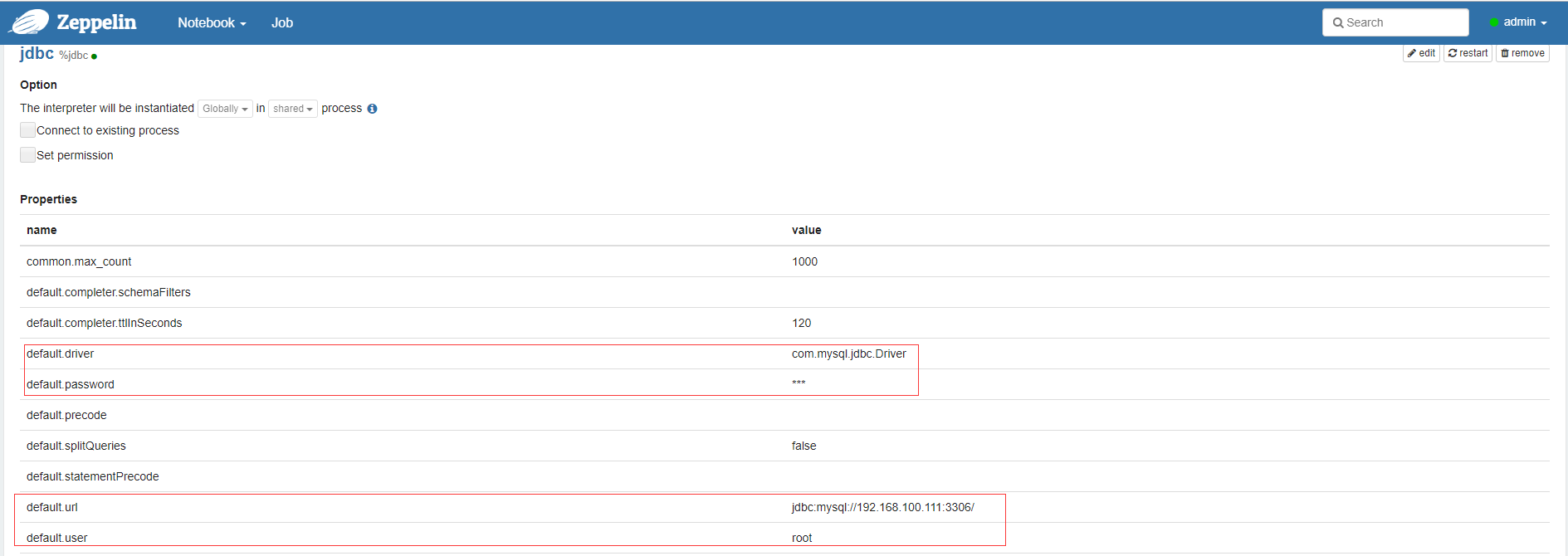

需要填写的有5个地方
default.driver
default.password
default.url
default.user
artifact
查询mysql里面的数据
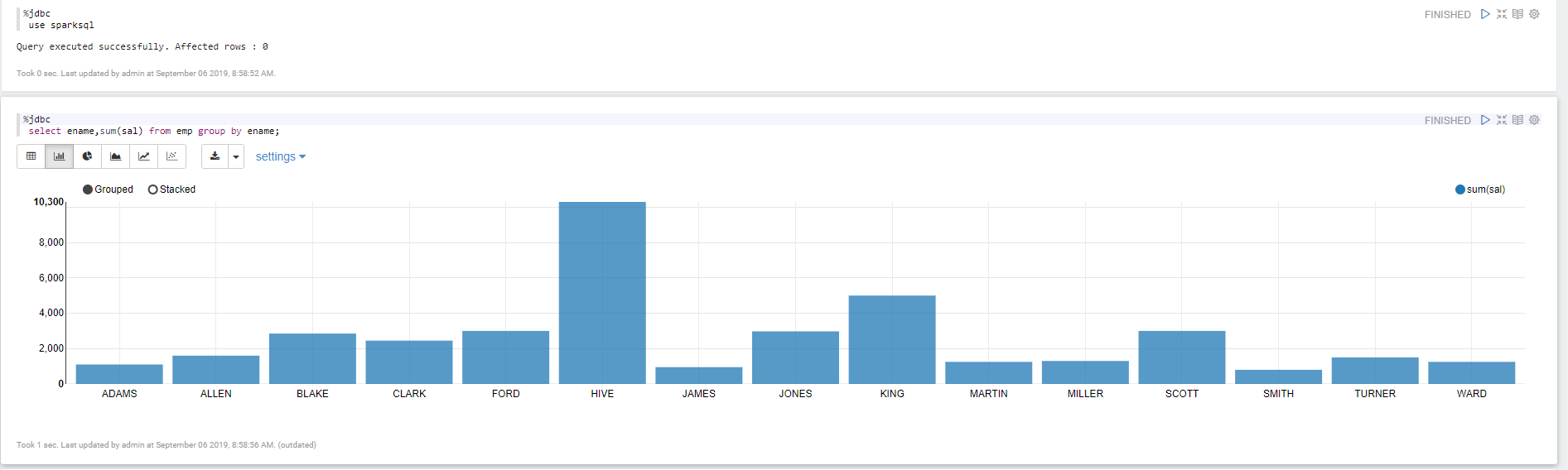
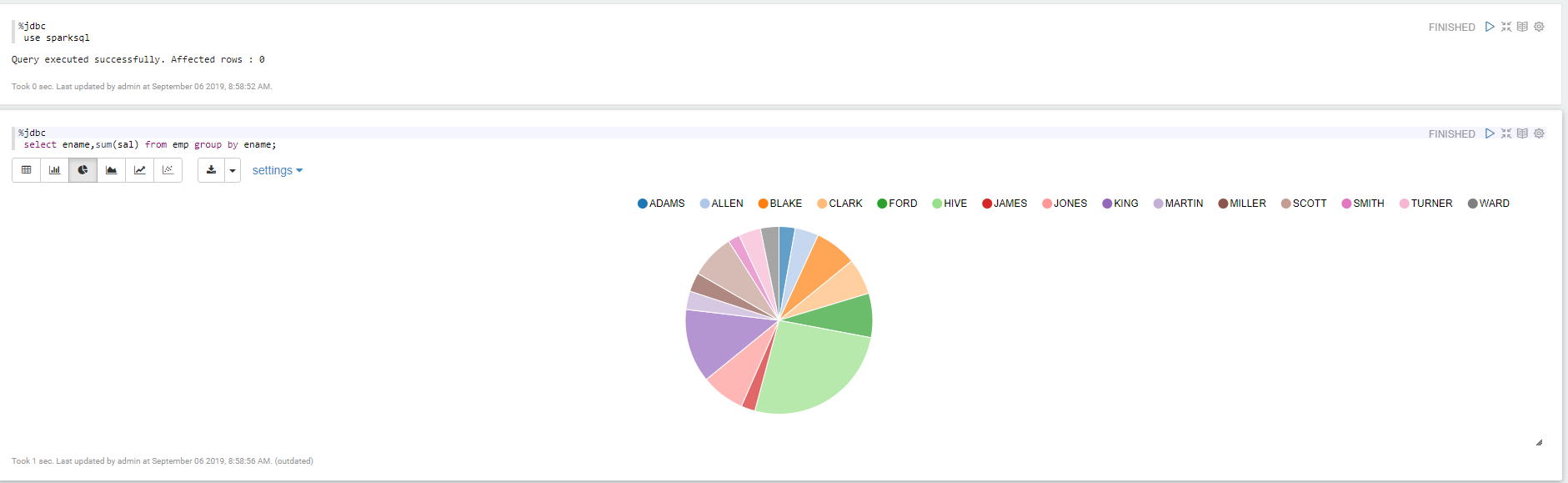
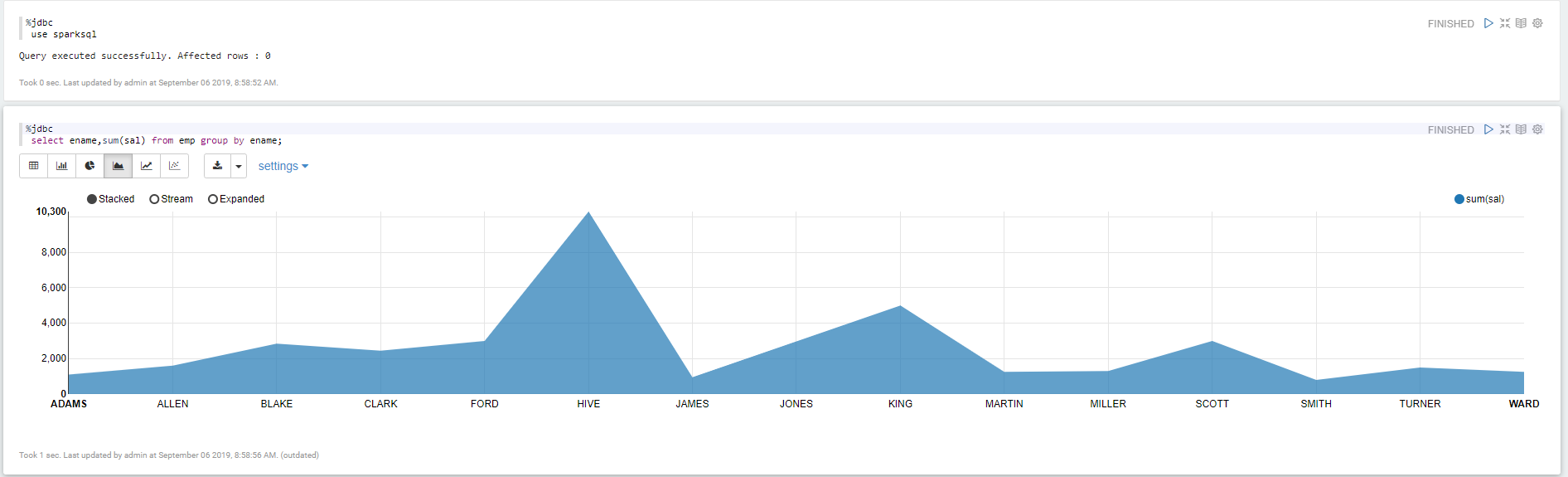
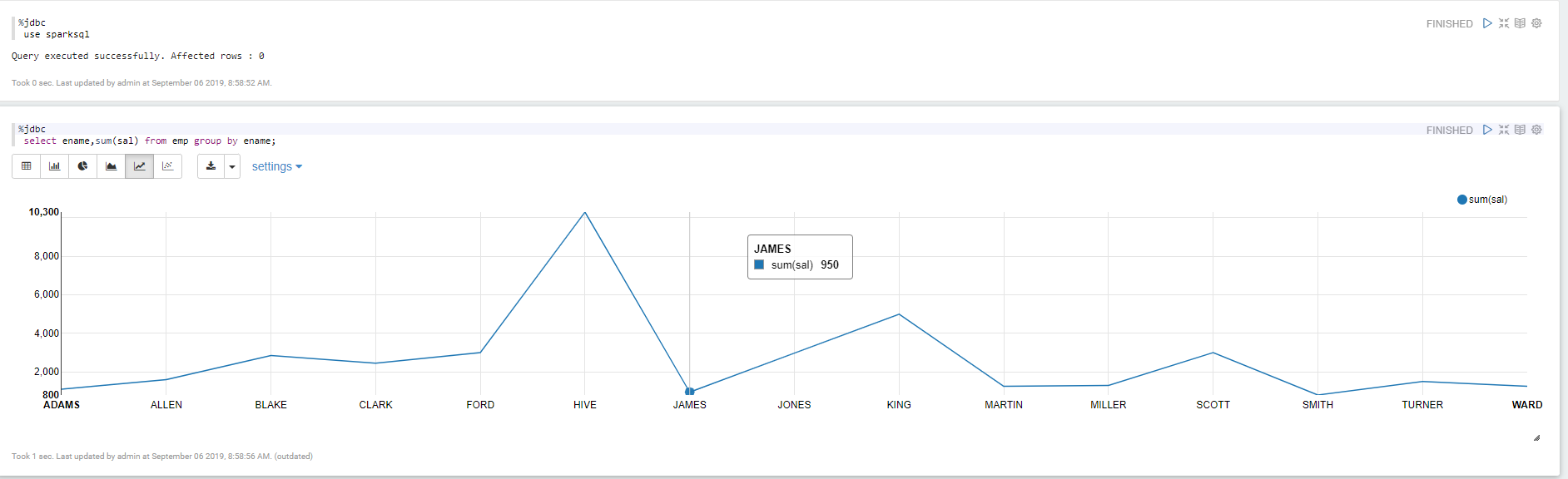
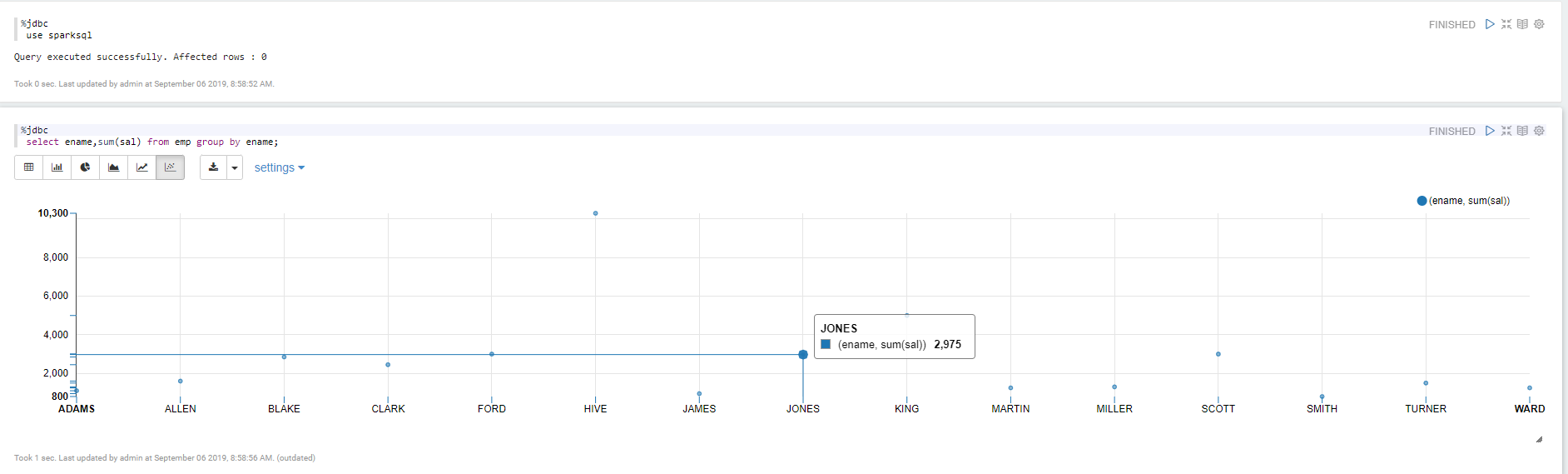
Apache Zepplin 对接Apache Spark
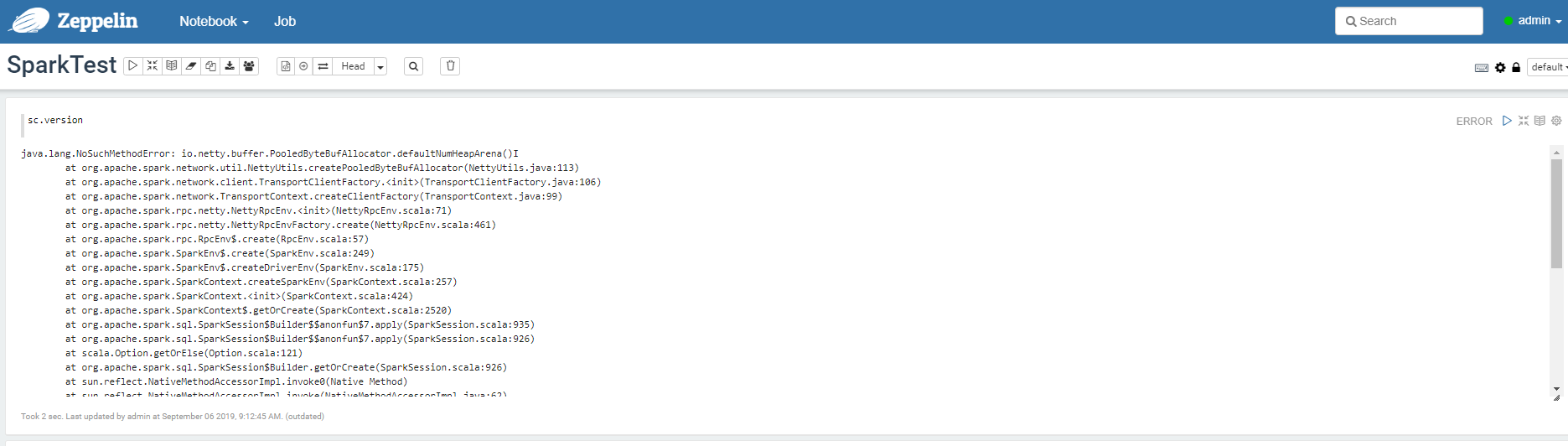
当出现 java.lang.NoSuchMethodError: io.netty.buffer.PooledByteBufAllocator.defaultNumHeapArena()I
解决办法:
# cd $ZEPPELIN_HOME/lib
# mv netty-all-4.0.23.Final.jar netty-all-4.0.23.Final.jar_bak
# cp $SPARK_HOME/jars/netty-all-4.1.17.Final.jar $ZEPPELIN_HOME/lib
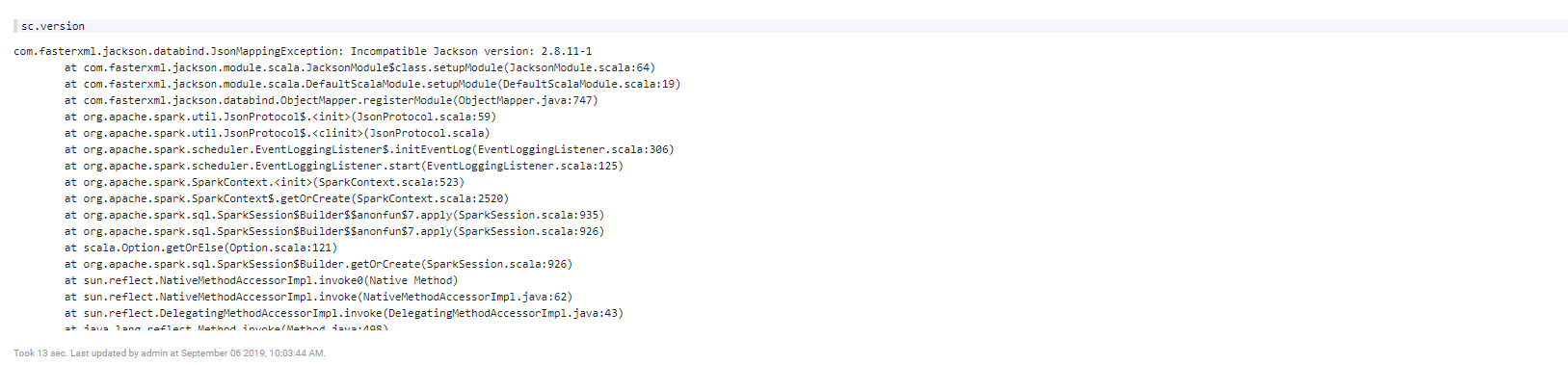
当出现
com.fasterxml.jackson.databind.JsonMappingException: Incompatible Jackson version: 2.8.11-1
解决办法:
# cd $ZEPPELIN_HOME/lib
# mv jackson-databind-2.8.11.1.jar jackson-databind-2.8.11.1.jar_bak
# cp $SPARK_HOME/jars/jackson-databind-2.6.7.1.jar $ZEPPELIN_HOME/lib
Spark 样例代码
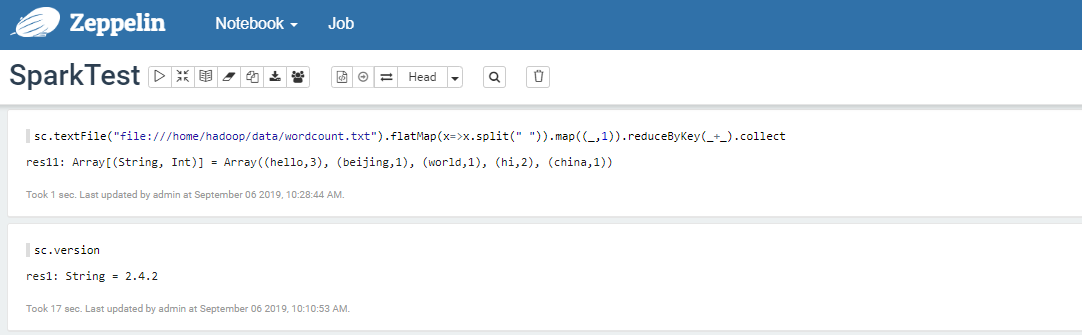
Spark SQL
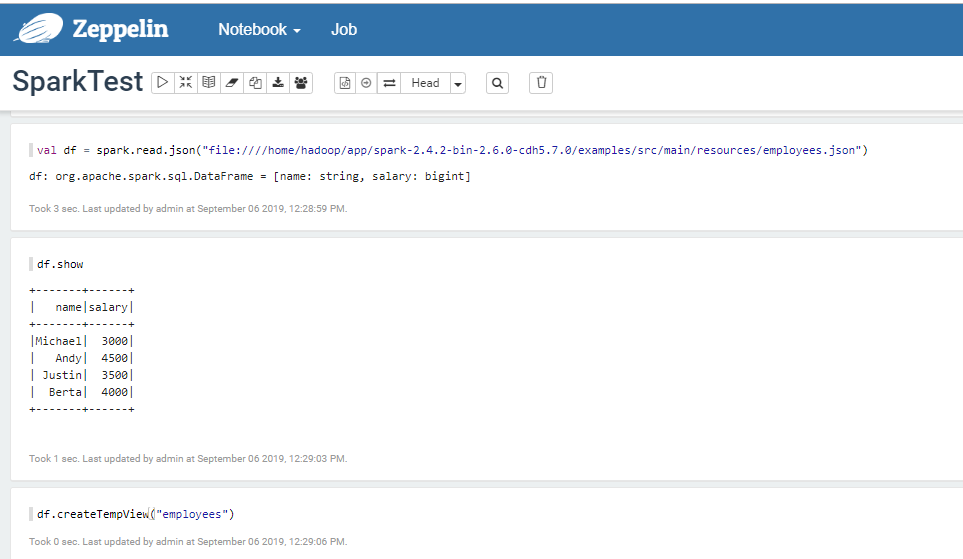
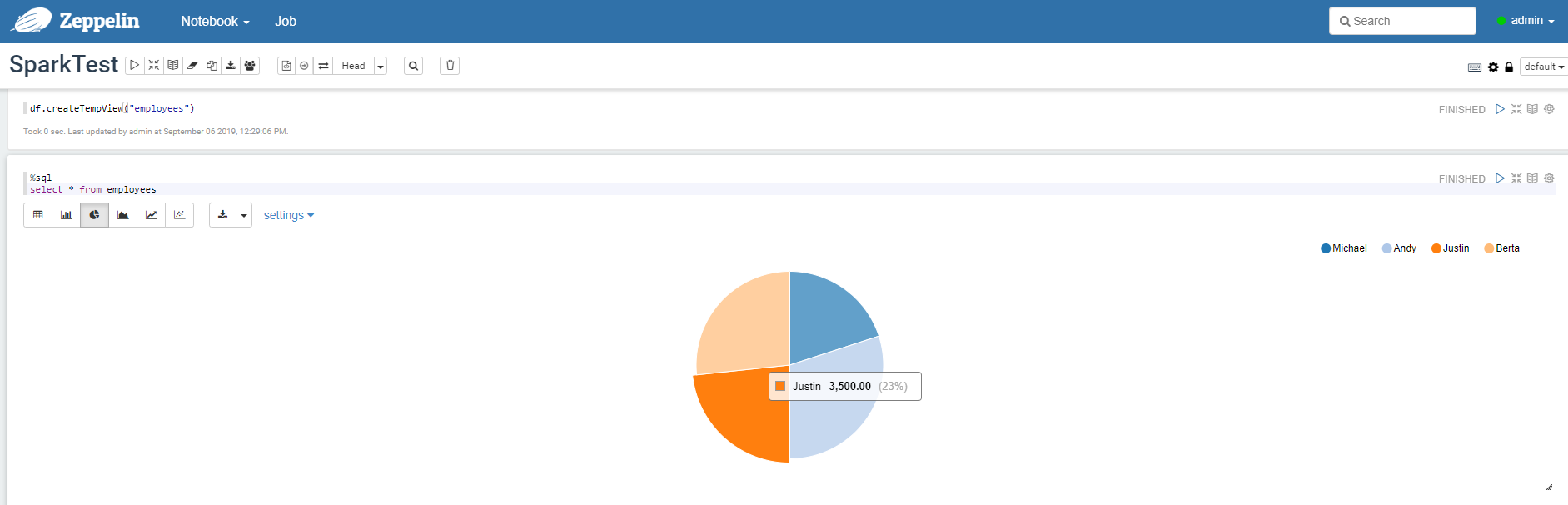
SparkSQL处理HDFS上的数据
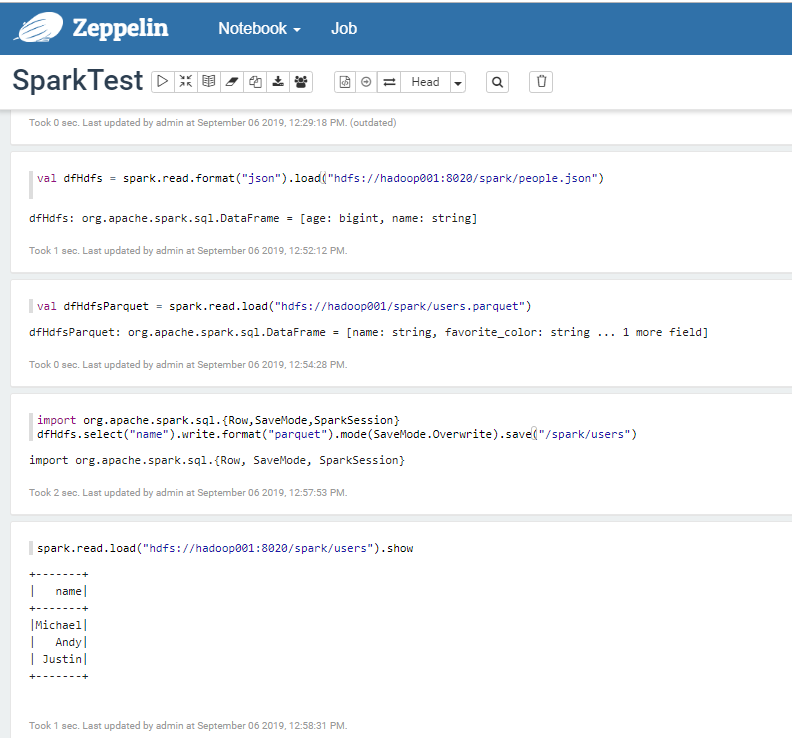
Apark Zeppelin里面自带Apache Spark,并且自带了sc,用 Apache Zeppelin还是比直接用Spark Shell或者Spark SQL 来调试方便不少。
Apache Zeppelin 操作Shell
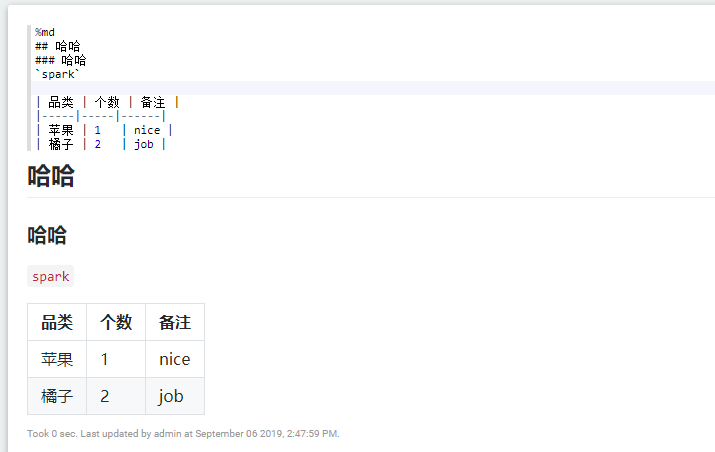
Apache Zeppelin 操作MarkDown
Apache Zeppelin 里面自带了 MarkDown
Apache Zeppelin 集成 Apache Flink
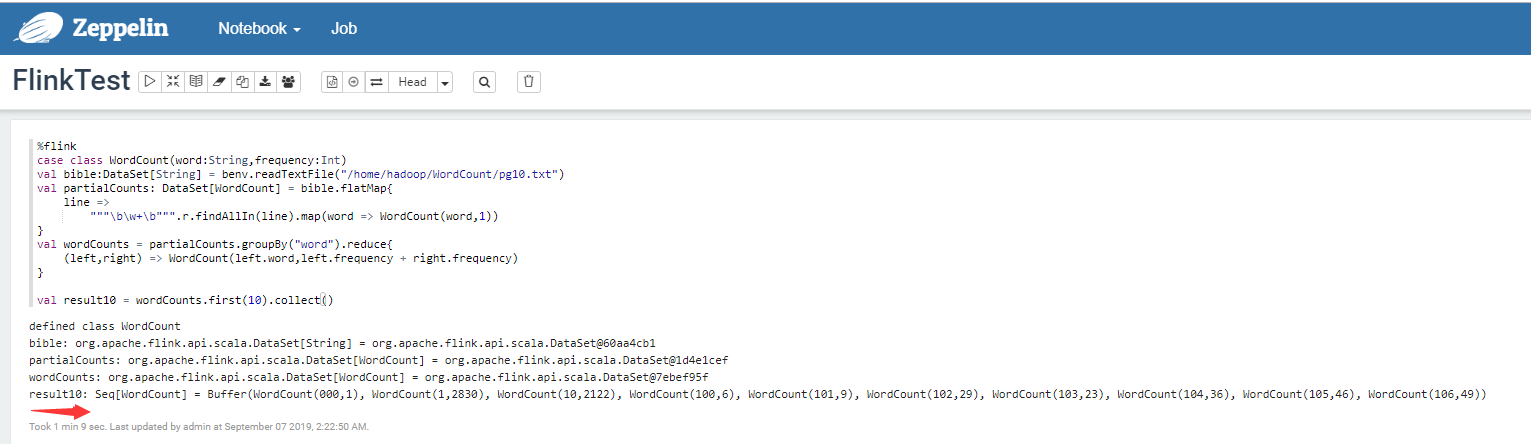
Zeppelin将创建6个变量来表示flink的入口点
senv(StreamExecutionEnvironment),benv(ExecutionEnvironment)stenv(StreamTableEnvironment for blink planner)btenv(BatchTableEnvironment for blink planner)stenv_2(StreamTableEnvironment for flink planner)btenv_2(BatchTableEnvironment for flink planner)
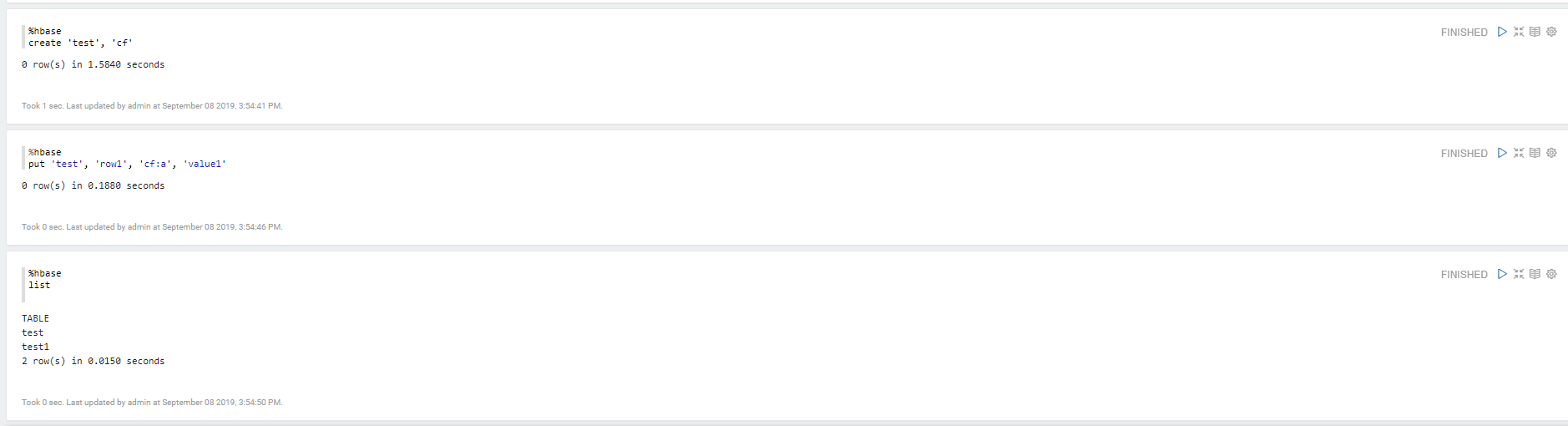
Apache Zeppelin 集成 Apache HBase
[hadoop@hadoop001 hbase]$ pwd
/home/hadoop/app/zeppelin-0.8.2-bin-all/interpreter/hbase
[hadoop@hadoop001 hbase]$ mkdir hbase_jar
[hadoop@hadoop001 hbase]$ mv hbase*.jar hbase_jar/
[hadoop@hadoop001 hbase]$ mv hadoop*.jar hbase_jar/
[hadoop@hadoop001 hbase]$ mv zookeeper-3.4.6.jar hbase_jar/
[hadoop@hadoop001 hbase]$
[hadoop@hadoop001 hbase]$ cp -f /home/hadoop/app/hbase-1.2.0-cdh5.7.0/lib/*.jar /home/hadoop/app/zeppelin-0.8.2-bin-all/interpreter/hbase/
- 编辑
interpreter.json,位置/home/hadoop/app/zeppelin-0.8.2-bin-all/interpreter/hbase/interpreter.json,修改hbase.home。
"hbase.home": {
"name": "hbase.home",
"value": "/home/hadoop/app/hbase-1.2.0-cdh5.7.0/",
"type": "string"
},
-
重启
Apache Zeppelincd /home/hadoop/app/zeppelin-0.8.2-bin-all/bin zeppelin-daemon.sh restart -
测试
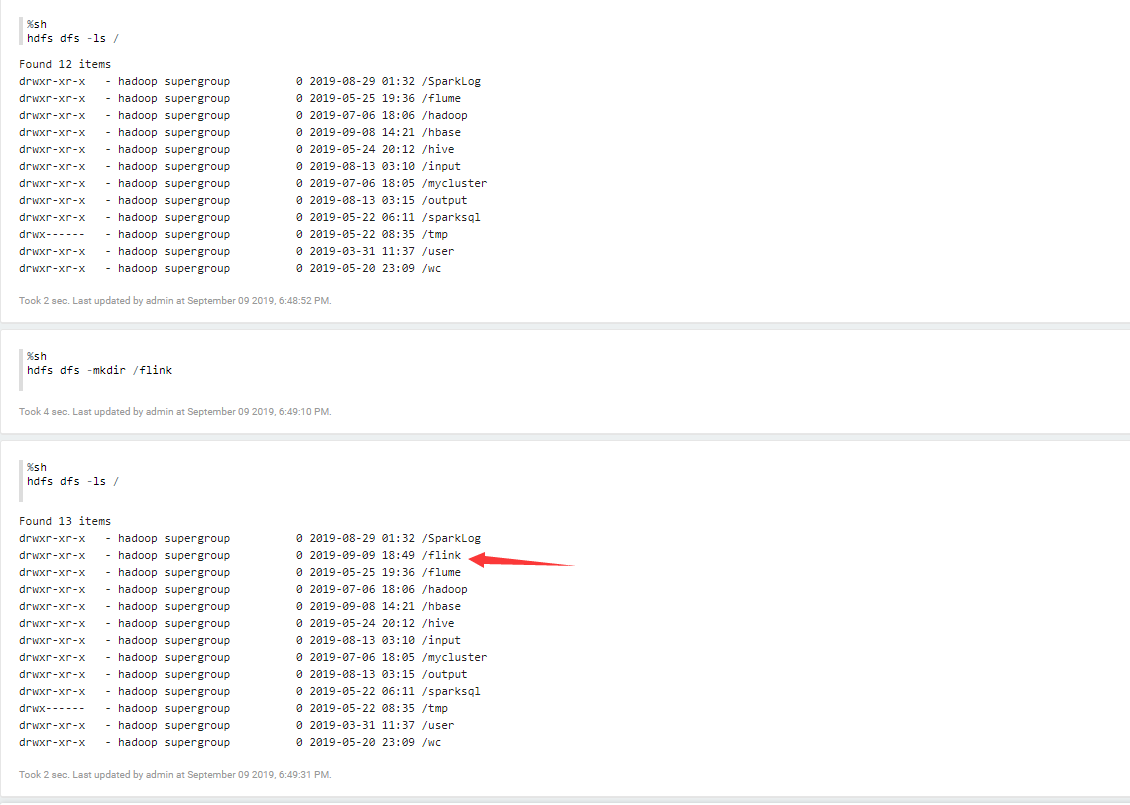
Apache Zeppelin 集成 HDFS
Apache Zeppelin 集成 Apache Hive
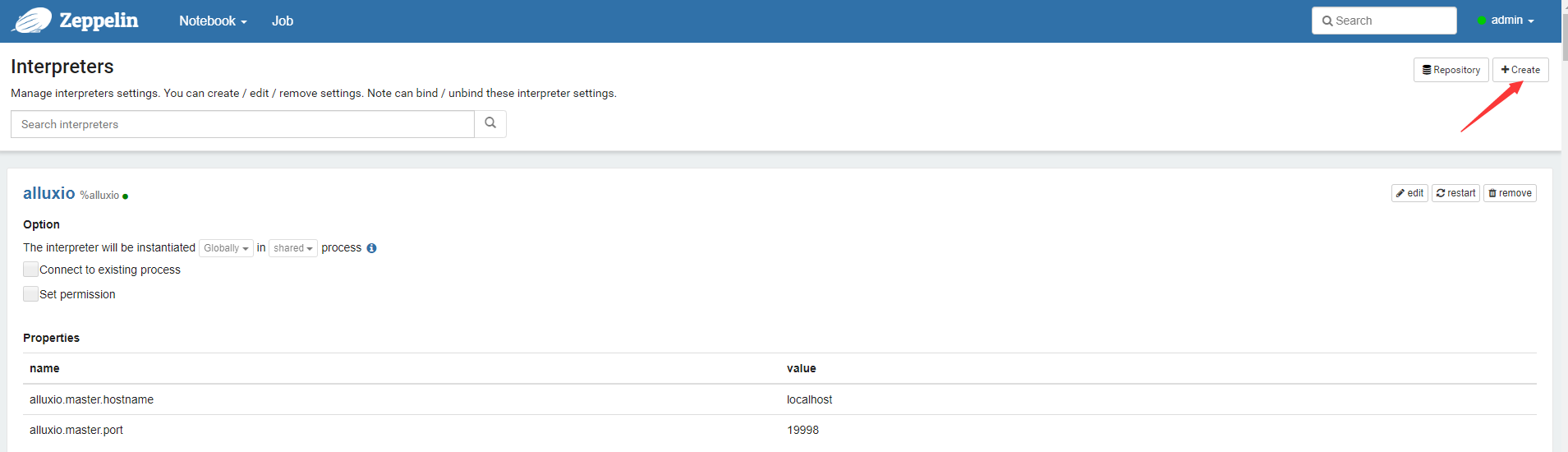
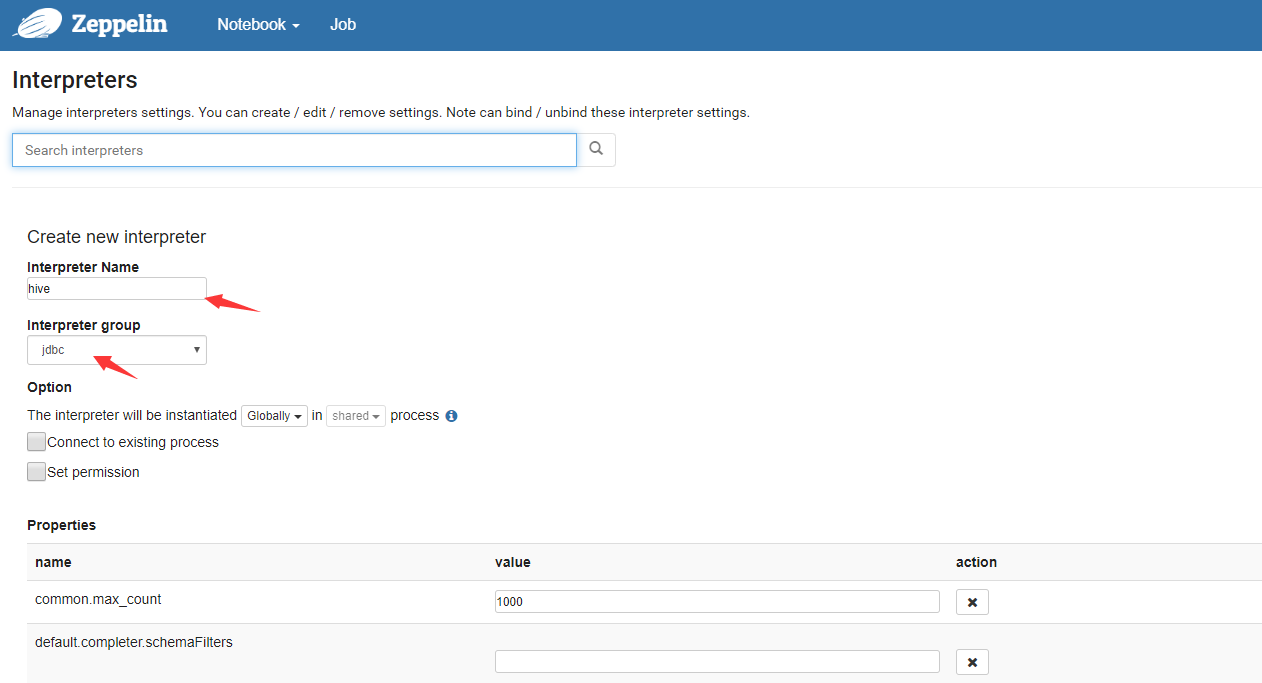
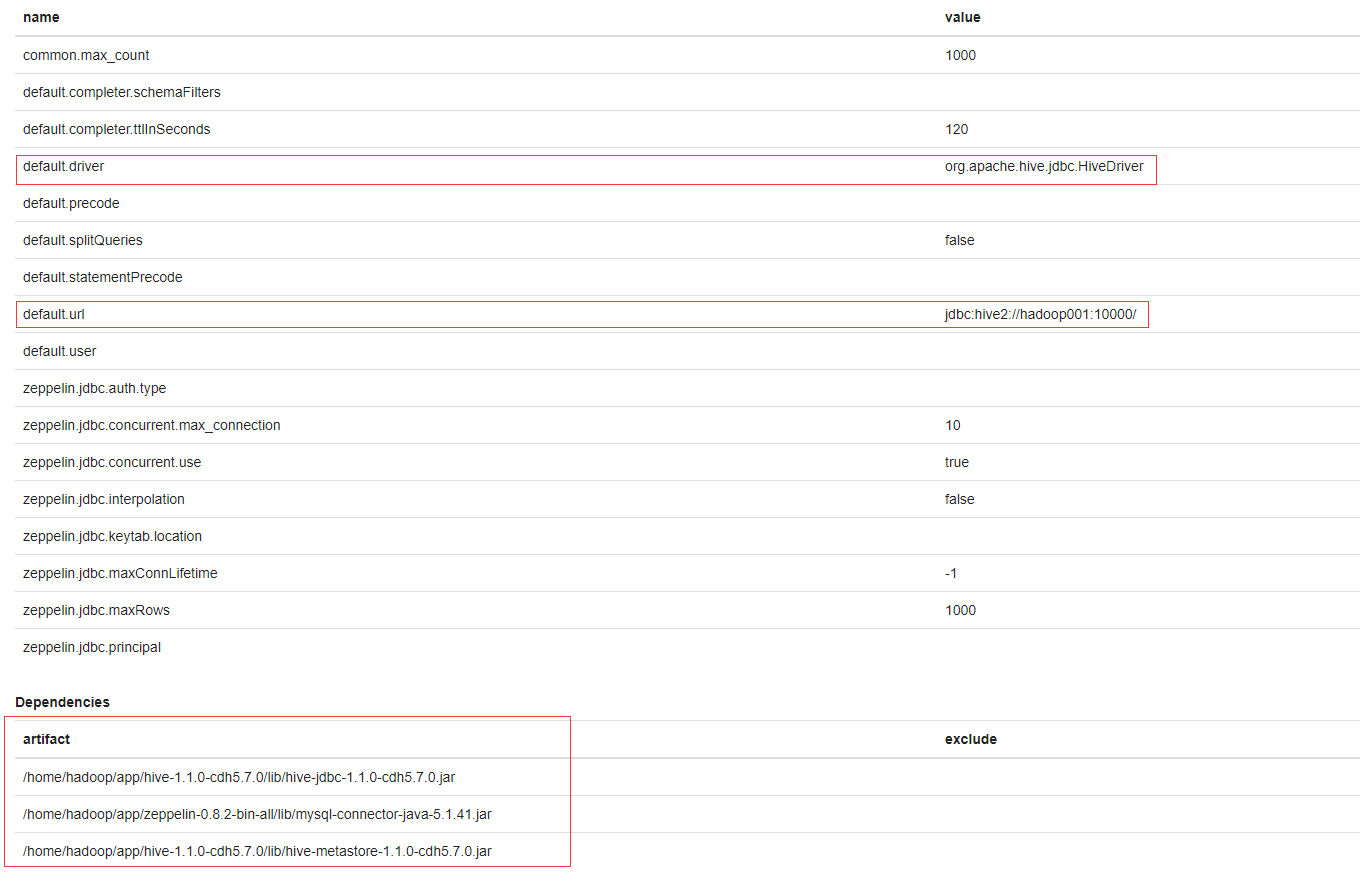
- 添加
hive的Interpreters
- 启动
hive2
[hadoop@hadoop001 lib]$ hiveserver2 &
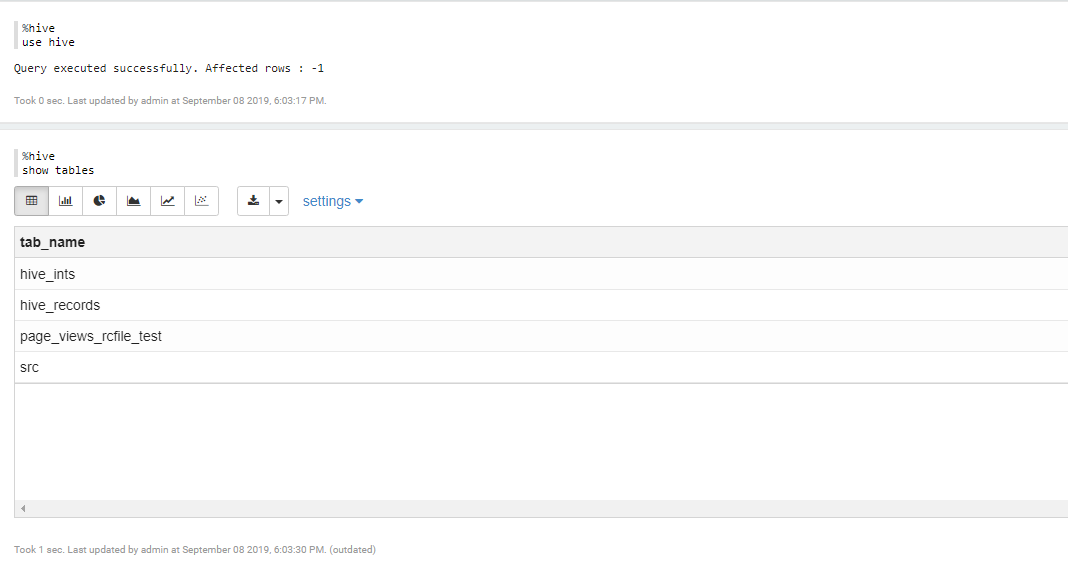
- 测试
Apache Zeppelin 集成 Elasticsearch
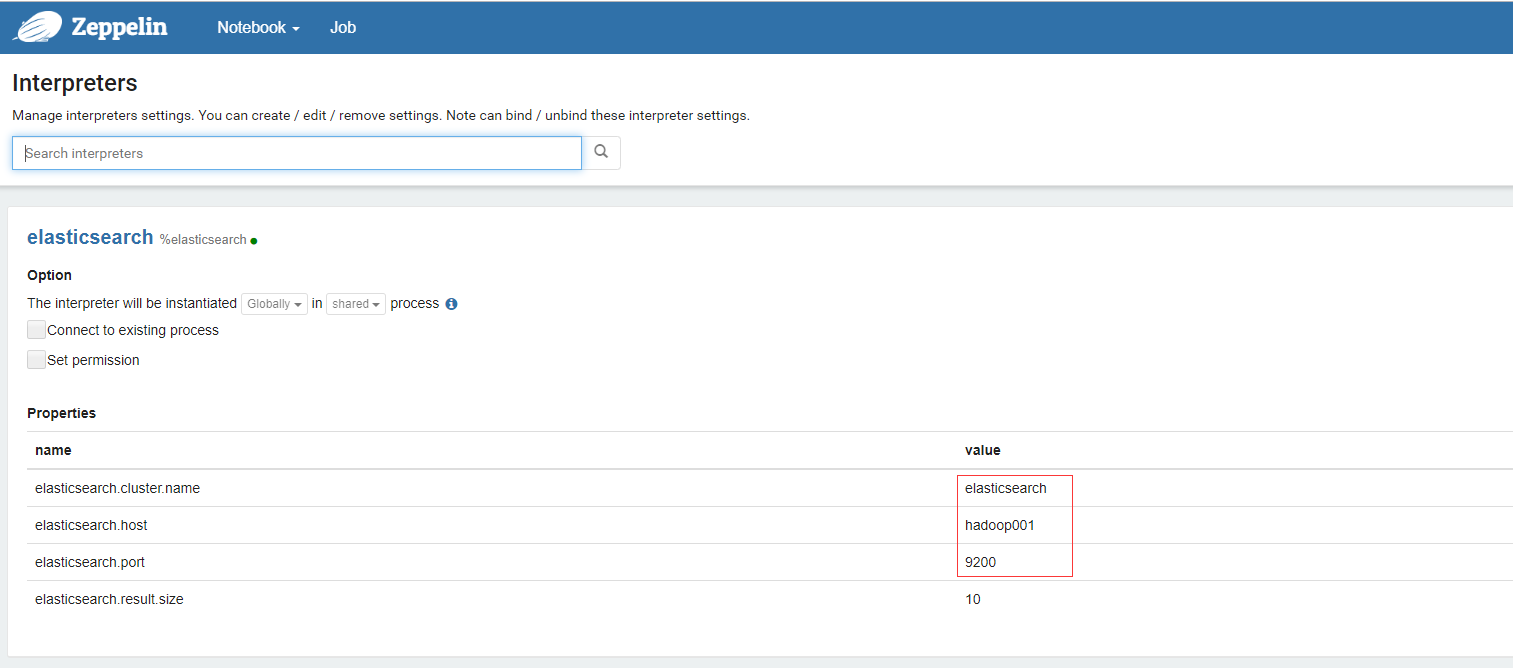
- 可以直接用
Elasticsearch的Interpreters
- 也可以直接用
shell的Interpreters
Apache Zeppelin VS Jupyter Notebook
Jupyter Notebook是IPython Notebook的演变版,更出名。
| 对比 | Zeppelin | Jupyter |
|---|---|---|
| 开发语言 | python | java |
| GithubStar | 4.6k | 6.8k |
| 安装 | 简单 | 简单 |
| 诞生 | 2012年 | 2013年 |
| 支持Spark | 支持 | 支持 |
| 支持Flink | 支持 | 暂不支持 |
| 多用户 | 支持 | 不支持 |
| 权限 | 支持 | 不支持 |
Apache Zeppelin 功能强大,适合于企业级应用,而Jupyter 更适用于个人测试学习,Apache Zeppelin集成了Flink/Spark等大数据知名产品,而Jupyter未集成Flink,功能远不如Apache Zeppelin强大。